 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroIncept Decoder for High-Fidelity Speech Reconstruction from Neural Activity
Jan 07, 2025This paper introduces a novel algorithm designed for speech synthesis from neural activity recordings obtained using invasive electroencephalography (EEG) techniques. The proposed system offers a promising communication solution for individuals with severe speech impairments. Central to our approach is the integration of time-frequency features in the high-gamma band computed from EEG recordings with an advanced NeuroIncept Decoder architecture. This neural network architecture combines Convolutional Neural Networks (CNNs) and Gated Recurrent Units (GRUs) to reconstruct audio spectrograms from neural patterns. Our model demonstrates robust mean correlation coefficients between predicted and actual spectrograms, though inter-subject variability indicates distinct neural processing mechanisms among participants. Overall, our study highlights the potential of neural decoding techniques to restore communicative abilities in individuals with speech disorders and paves the way for future advancements in brain-computer interface technologies.
Silent Speech Interfaces for Speech Restoration: A Review
Sep 27, 2020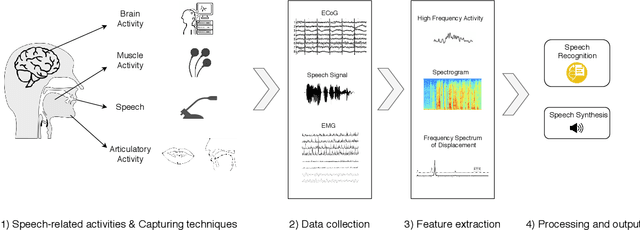

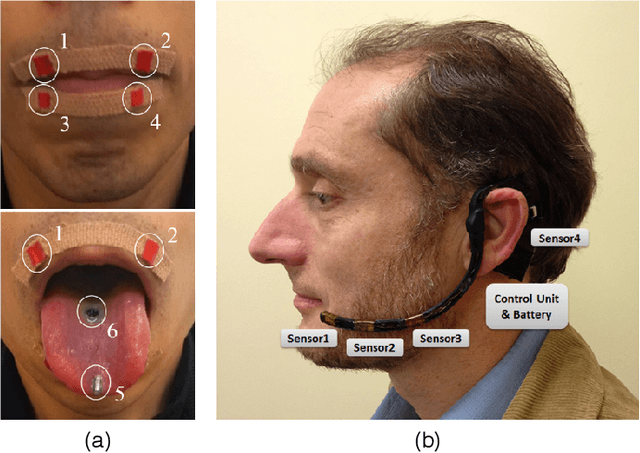

This review summarises the status of silent speech interface (SSI) research. SSIs rely on non-acoustic biosignals generated by the human body during speech production to enable communication whenever normal verbal communication is not possible or not desirable. In this review, we focus on the first case and present latest SSI research aimed at providing new alternative and augmentative communication methods for persons with severe speech disorders. SSIs can employ a variety of biosignals to enable silent communication, such as electrophysiological recordings of neural activity, electromyographic (EMG) recordings of vocal tract movements or the direct tracking of articulator movements using imaging techniques. Depending on the disorder, some sensing techniques may be better suited than others to capture speech-related information. For instance, EMG and imaging techniques are well suited for laryngectomised patients, whose vocal tract remains almost intact but are unable to speak after the removal of the vocal folds, but fail for severely paralysed individuals. From the biosignals, SSIs decode the intended message, using automatic speech recognition or speech synthesis algorithms. Despite considerable advances in recent years, most present-day SSIs have only been validated in laboratory settings for healthy users. Thus, as discussed in this paper, a number of challenges remain to be addressed in future research before SSIs can be promoted to real-world applications. If these issues can be addressed successfully, future SSIs will improve the lives of persons with severe speech impairments by restoring their communication capabilities.