 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Frequency-Attention Alternative to CNN Frontends for Automatic Speech Recognition
Jun 12, 2023


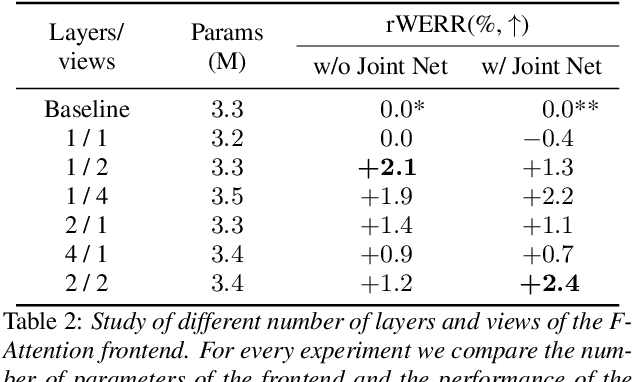
Convolutional frontends are a typical choice for Transformer-based automatic speech recognition to preprocess the spectrogram, reduce its sequence length, and combine local information in time and frequency similarly. However, the width and height of an audio spectrogram denote different information, e.g., due to reverberation as well as the articulatory system, the time axis has a clear left-to-right dependency. On the contrary, vowels and consonants demonstrate very different patterns and occupy almost disjoint frequency ranges. Therefore, we hypothesize, global attention over frequencies is beneficial over local convolution. We obtain 2.4 % relative word error rate reduction (rWERR) on a production scale Conformer transducer replacing its convolutional neural network frontend by the proposed F-Attention module on Alexa traffic. To demonstrate generalizability, we validate this on public LibriSpeech data with a long short term memory-based listen attend and spell architecture obtaining 4.6 % rWERR and demonstrate robustness to (simulated) noisy conditions.
Contextual-Utterance Training for Automatic Speech Recognition
Oct 27, 2022



Recent studies of streaming automatic speech recognition (ASR) recurrent neural network transducer (RNN-T)-based systems have fed the encoder with past contextual information in order to improve its word error rate (WER) performance. In this paper, we first propose a contextual-utterance training technique which makes use of the previous and future contextual utterances in order to do an implicit adaptation to the speaker, topic and acoustic environment. Also, we propose a dual-mode contextual-utterance training technique for streaming automatic speech recognition (ASR) systems. This proposed approach allows to make a better use of the available acoustic context in streaming models by distilling "in-place" the knowledge of a teacher, which is able to see both past and future contextual utterances, to the student which can only see the current and past contextual utterances. The experimental results show that a conformer-transducer system trained with the proposed techniques outperforms the same system trained with the classical RNN-T loss. Specifically, the proposed technique is able to reduce both the WER and the average last token emission latency by more than 6% and 40ms relative, respectively.
Compacting Neural Network Classifiers via Dropout Training
May 24, 2017
We introduce dropout compaction, a novel method for training feed-forward neural networks which realizes the performance gains of training a large model with dropout regularization, yet extracts a compact neural network for run-time efficiency. In the proposed method, we introduce a sparsity-inducing prior on the per unit dropout retention probability so that the optimizer can effectively prune hidden units during training. By changing the prior hyperparameters, we can control the size of the resulting network. We performed a systematic comparison of dropout compaction and competing methods on several real-world speech recognition tasks and found that dropout compaction achieved comparable accuracy with fewer than 50% of the hidden units, translating to a 2.5x speedup in run-time.