 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Modeling of Multi-Domain Multi-Device ASR Systems
May 13, 2022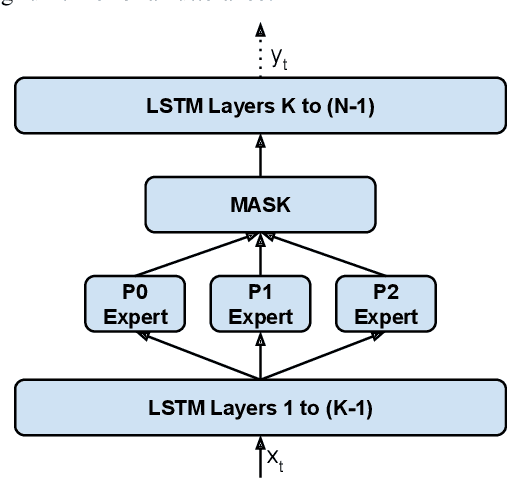

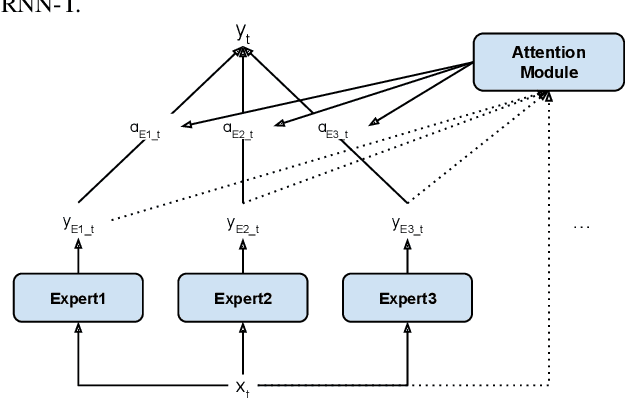
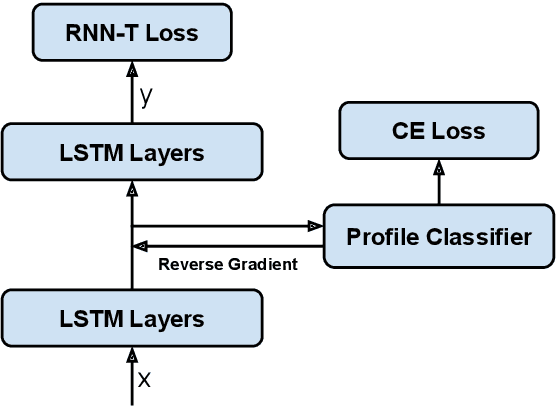
Modern Automatic Speech Recognition (ASR) systems often use a portfolio of domain-specific models in order to get high accuracy for distinct user utterance types across different devices. In this paper, we propose an innovative approach that integrates the different per-domain per-device models into a unified model, using a combination of domain embedding, domain experts, mixture of experts and adversarial training. We run careful ablation studies to show the benefit of each of these innovations in contributing to the accuracy of the overall unified model. Experiments show that our proposed unified modeling approach actually outperforms the carefully tuned per-domain models, giving relative gains of up to 10% over a baseline model with negligible increase in the number of parameters.
Improving RNN-T ASR Performance with Date-Time and Location Awareness
Jun 16, 2021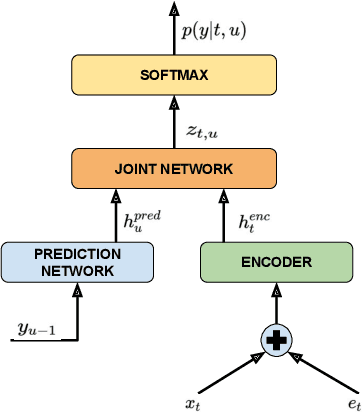
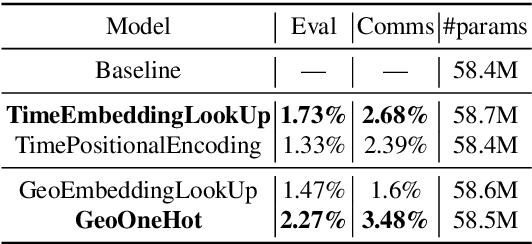
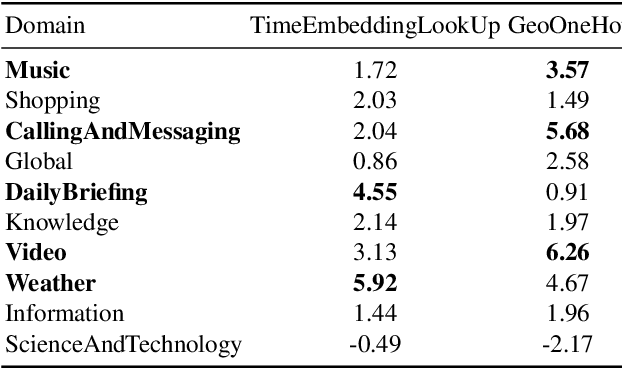

In this paper, we explore the benefits of incorporating context into a Recurrent Neural Network (RNN-T) based Automatic Speech Recognition (ASR) model to improve the speech recognition for virtual assistants. Specifically, we use meta information extracted from the time at which the utterance is spoken and the approximate location information to make ASR context aware. We show that these contextual information, when used individually, improves overall performance by as much as 3.48% relative to the baseline and when the contexts are combined, the model learns complementary features and the recognition improves by 4.62%. On specific domains, these contextual signals show improvements as high as 11.5%, without any significant degradation on others. We ran experiments with models trained on data of sizes 30K hours and 10K hours. We show that the scale of improvement with the 10K hours dataset is much higher than the one obtained with 30K hours dataset. Our results indicate that with limited data to train the ASR model, contextual signals can improve the performance significantly.
Summarizing Event Sequences with Serial Episodes: A Statistical Model and an Application
Apr 01, 2019

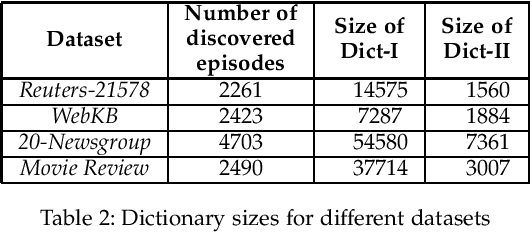
In this paper we address the problem of discovering a small set of frequent serial episodes from sequential data so as to adequately characterize or summarize the data. We discuss an algorithm based on the Minimum Description Length (MDL) principle and the algorithm is a slight modification of an earlier method, called CSC-2. We present a novel generative model for sequence data containing prominent pairs of serial episodes and, using this, provide some statistical justification for the algorithm. We believe this is the first instance of such a statistical justification for an MDL based algorithm for summarizing event sequence data. We then present a novel application of this data mining algorithm in text classification. By considering text documents as temporal sequences of words, the data mining algorithm can find a set of characteristic episodes for all the training data as a whole. The words that are part of these characteristic episodes could then be considered the only relevant words for the dictionary thus resulting in a considerably reduced feature vector dimension. We show, through simulation experiments using benchmark data sets, that the discovered frequent episodes can be used to achieve more than four-fold reduction in dictionary size without losing any classification accuracy.