 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Gaussian-Bernoulli RBMs using Difference of Convex Functions Optimization
Feb 11, 2021
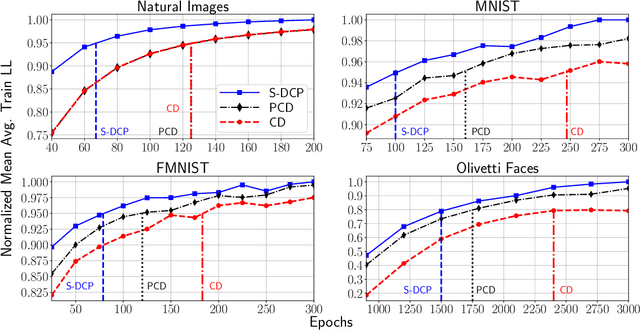
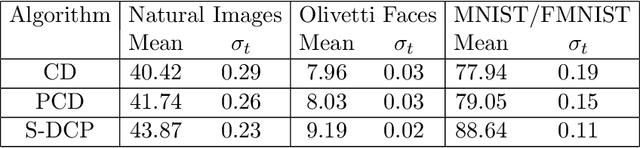
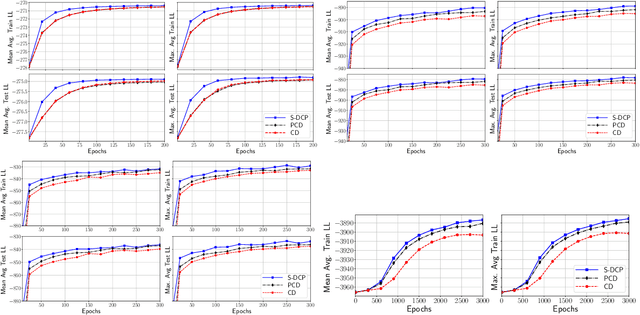
The Gaussian-Bernoulli restricted Boltzmann machine (GB-RBM) is a useful generative model that captures meaningful features from the given $n$-dimensional continuous data. The difficulties associated with learning GB-RBM are reported extensively in earlier studies. They indicate that the training of the GB-RBM using the current standard algorithms, namely, contrastive divergence (CD) and persistent contrastive divergence (PCD), needs a carefully chosen small learning rate to avoid divergence which, in turn, results in slow learning. In this work, we alleviate such difficulties by showing that the negative log-likelihood for a GB-RBM can be expressed as a difference of convex functions if we keep the variance of the conditional distribution of visible units (given hidden unit states) and the biases of the visible units, constant. Using this, we propose a stochastic {\em difference of convex functions} (DC) programming (S-DCP) algorithm for learning the GB-RBM. We present extensive empirical studies on several benchmark datasets to validate the performance of this S-DCP algorithm. It is seen that S-DCP is better than the CD and PCD algorithms in terms of speed of learning and the quality of the generative model learnt.
Summarizing Event Sequences with Serial Episodes: A Statistical Model and an Application
Apr 01, 2019

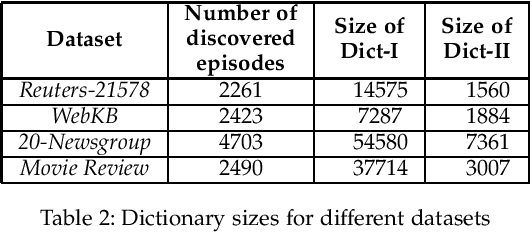
In this paper we address the problem of discovering a small set of frequent serial episodes from sequential data so as to adequately characterize or summarize the data. We discuss an algorithm based on the Minimum Description Length (MDL) principle and the algorithm is a slight modification of an earlier method, called CSC-2. We present a novel generative model for sequence data containing prominent pairs of serial episodes and, using this, provide some statistical justification for the algorithm. We believe this is the first instance of such a statistical justification for an MDL based algorithm for summarizing event sequence data. We then present a novel application of this data mining algorithm in text classification. By considering text documents as temporal sequences of words, the data mining algorithm can find a set of characteristic episodes for all the training data as a whole. The words that are part of these characteristic episodes could then be considered the only relevant words for the dictionary thus resulting in a considerably reduced feature vector dimension. We show, through simulation experiments using benchmark data sets, that the discovered frequent episodes can be used to achieve more than four-fold reduction in dictionary size without losing any classification accuracy.