 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarizing Event Sequences with Serial Episodes: A Statistical Model and an Application
Paper and Code


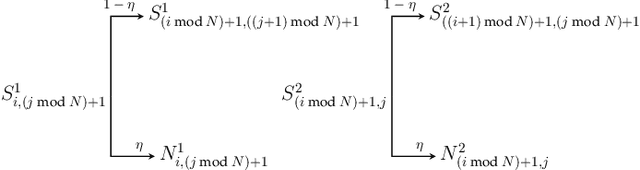
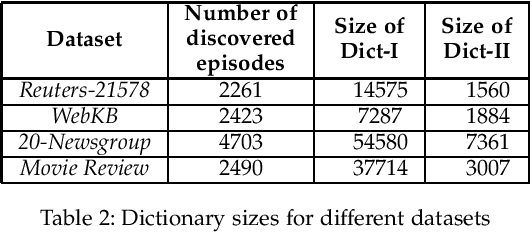
In this paper we address the problem of discovering a small set of frequent serial episodes from sequential data so as to adequately characterize or summarize the data. We discuss an algorithm based on the Minimum Description Length (MDL) principle and the algorithm is a slight modification of an earlier method, called CSC-2. We present a novel generative model for sequence data containing prominent pairs of serial episodes and, using this, provide some statistical justification for the algorithm. We believe this is the first instance of such a statistical justification for an MDL based algorithm for summarizing event sequence data. We then present a novel application of this data mining algorithm in text classification. By considering text documents as temporal sequences of words, the data mining algorithm can find a set of characteristic episodes for all the training data as a whole. The words that are part of these characteristic episodes could then be considered the only relevant words for the dictionary thus resulting in a considerably reduced feature vector dimension. We show, through simulation experiments using benchmark data sets, that the discovered frequent episodes can be used to achieve more than four-fold reduction in dictionary size without losing any classification accuracy.