 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn improved uncertainty decoding scheme with weighted samples for DNN-HMM hybrid systems
Aug 04, 2016

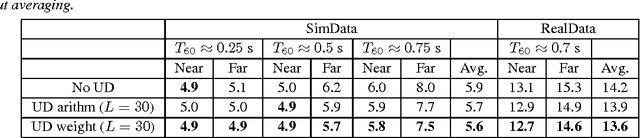
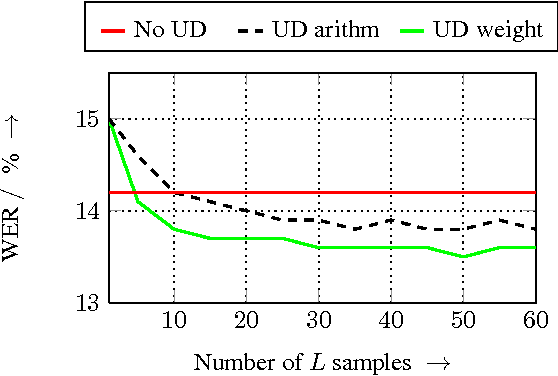
In this paper, we advance a recently-proposed uncertainty decoding scheme for DNN-HMM (deep neural network - hidden Markov model) hybrid systems. This numerical sampling concept averages DNN outputs produced by a finite set of feature samples (drawn from a probabilistic distortion model) to approximate the posterior likelihoods of the context-dependent HMM states. As main innovation, we propose a weighted DNN-output averaging based on a minimum classification error criterion and apply it to a probabilistic distortion model for spatial diffuseness features. The experimental evaluation is performed on the 8-channel REVERB Challenge task using a DNN-HMM hybrid system with multichannel front-end signal enhancement. We show that the recognition accuracy of the DNN-HMM hybrid system improves by incorporating uncertainty decoding based on random sampling and that the proposed weighted DNN-output averaging further reduces the word error rate scores.
Estimating parameters of nonlinear systems using the elitist particle filter based on evolutionary strategies
May 25, 2016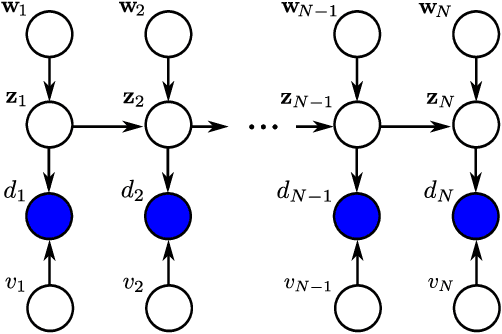



In this article, we present the elitist particle filter based on evolutionary strategies (EPFES) as an efficient approach for nonlinear system identification. The EPFES is derived from the frequently-employed state-space model, where the relevant information of the nonlinear system is captured by an unknown state vector. Similar to classical particle filtering, the EPFES consists of a set of particles and respective weights which represent different realizations of the latent state vector and their likelihood of being the solution of the optimization problem. As main innovation, the EPFES includes an evolutionary elitist-particle selection which combines long-term information with instantaneous sampling from an approximated continuous posterior distribution. In this article, we propose two advancements of the previously-published elitist-particle selection process. Further, the EPFES is shown to be a generalization of the widely-used Gaussian particle filter and thus evaluated with respect to the latter for two completely different scenarios: First, we consider the so-called univariate nonstationary growth model with time-variant latent state variable, where the evolutionary selection of elitist particles is evaluated for non-recursively calculated particle weights. Second, the problem of nonlinear acoustic echo cancellation is addressed in a simulated scenario with speech as input signal: By using long-term fitness measures, we highlight the efficacy of the well-generalizing EPFES in estimating the nonlinear system even for large search spaces. Finally, we illustrate similarities between the EPFES and evolutionary algorithms to outline future improvements by fusing the achievements of both fields of research.
Spatial Diffuseness Features for DNN-Based Speech Recognition in Noisy and Reverberant Environments
Feb 16, 2015


We propose a spatial diffuseness feature for deep neural network (DNN)-based automatic speech recognition to improve recognition accuracy in reverberant and noisy environments. The feature is computed in real-time from multiple microphone signals without requiring knowledge or estimation of the direction of arrival, and represents the relative amount of diffuse noise in each time and frequency bin. It is shown that using the diffuseness feature as an additional input to a DNN-based acoustic model leads to a reduced word error rate for the REVERB challenge corpus, both compared to logmelspec features extracted from noisy signals, and features enhanced by spectral subtraction.
The NLMS algorithm with time-variant optimum stepsize derived from a Bayesian network perspective
Nov 18, 2014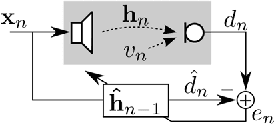
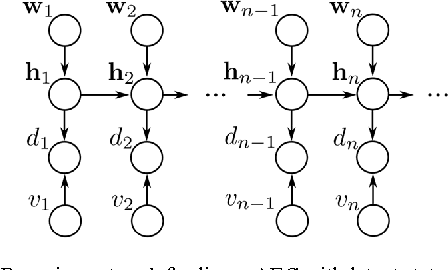

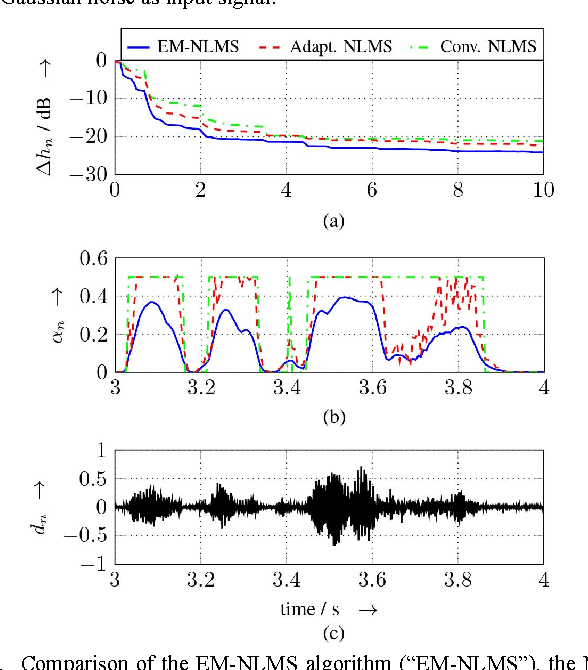
In this article, we derive a new stepsize adaptation for the normalized least mean square algorithm (NLMS) by describing the task of linear acoustic echo cancellation from a Bayesian network perspective. Similar to the well-known Kalman filter equations, we model the acoustic wave propagation from the loudspeaker to the microphone by a latent state vector and define a linear observation equation (to model the relation between the state vector and the observation) as well as a linear process equation (to model the temporal progress of the state vector). Based on additional assumptions on the statistics of the random variables in observation and process equation, we apply the expectation-maximization (EM) algorithm to derive an NLMS-like filter adaptation. By exploiting the conditional independence rules for Bayesian networks, we reveal that the resulting EM-NLMS algorithm has a stepsize update equivalent to the optimal-stepsize calculation proposed by Yamamoto and Kitayama in 1982, which has been adopted in many textbooks. As main difference, the instantaneous stepsize value is estimated in the M step of the EM algorithm (instead of being approximated by artificially extending the acoustic echo path). The EM-NLMS algorithm is experimentally verified for synthesized scenarios with both, white noise and male speech as input signal.
A Bayesian Network View on Acoustic Model-Based Techniques for Robust Speech Recognition
Sep 22, 2014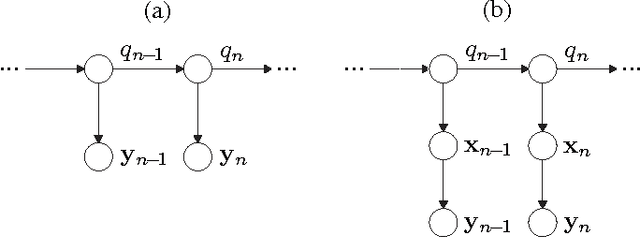
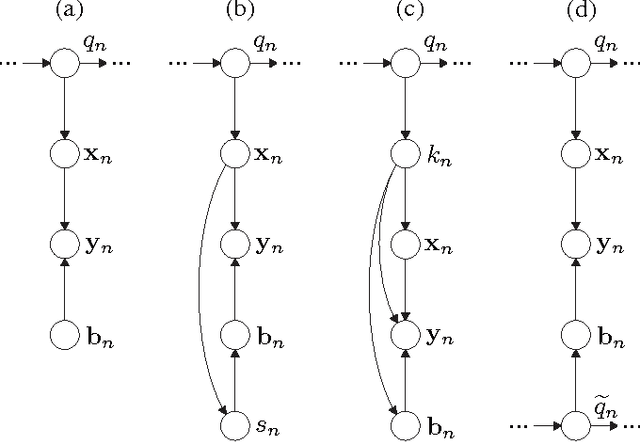
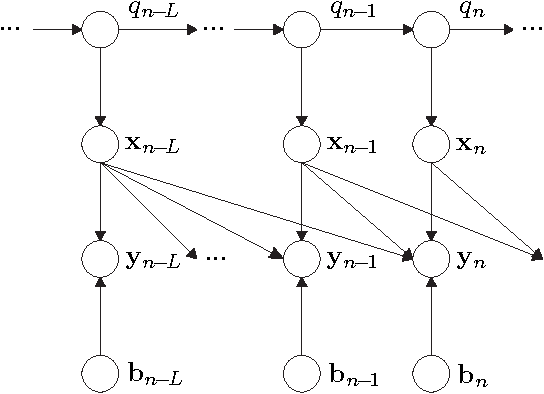
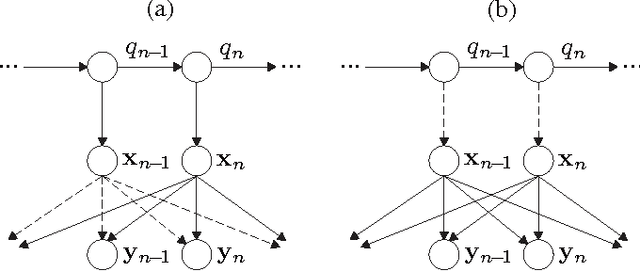
This article provides a unifying Bayesian network view on various approaches for acoustic model adaptation, missing feature, and uncertainty decoding that are well-known in the literature of robust automatic speech recognition. The representatives of these classes can often be deduced from a Bayesian network that extends the conventional hidden Markov models used in speech recognition. These extensions, in turn, can in many cases be motivated from an underlying observation model that relates clean and distorted feature vectors. By converting the observation models into a Bayesian network representation, we formulate the corresponding compensation rules leading to a unified view on known derivations as well as to new formulations for certain approaches. The generic Bayesian perspective provided in this contribution thus highlights structural differences and similarities between the analyzed approaches.