 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden-Markov-Model Based Speech Enhancement
Jul 04, 2017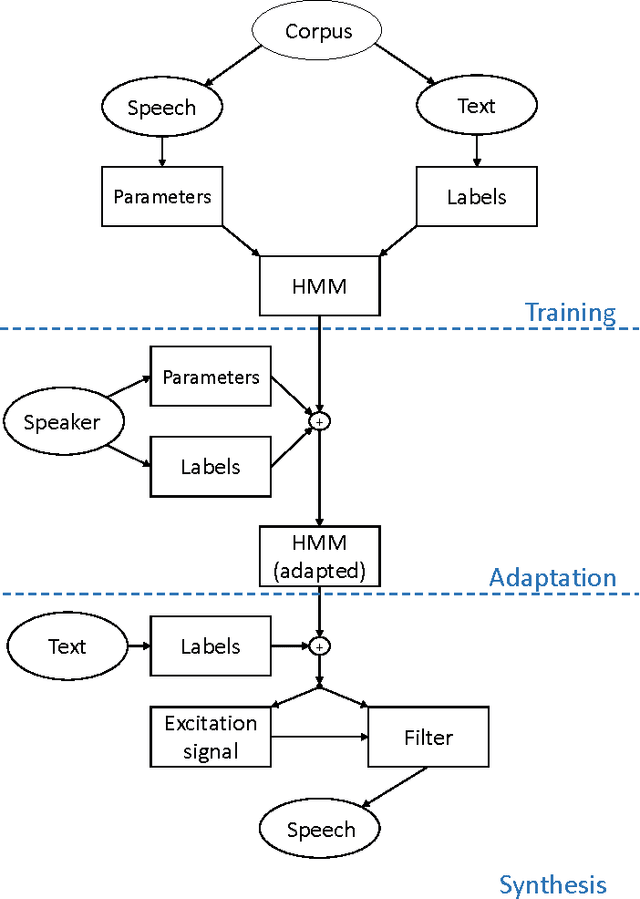
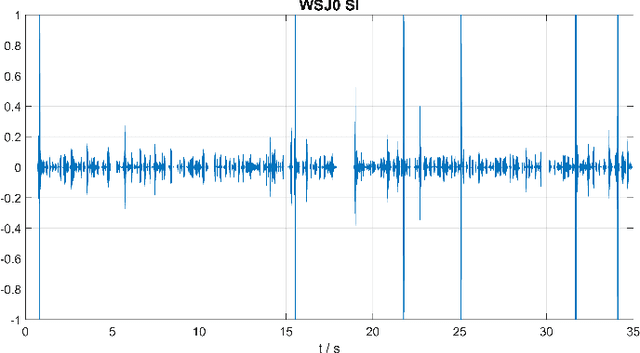
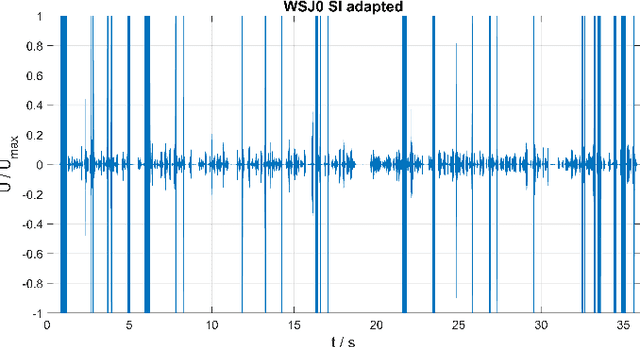
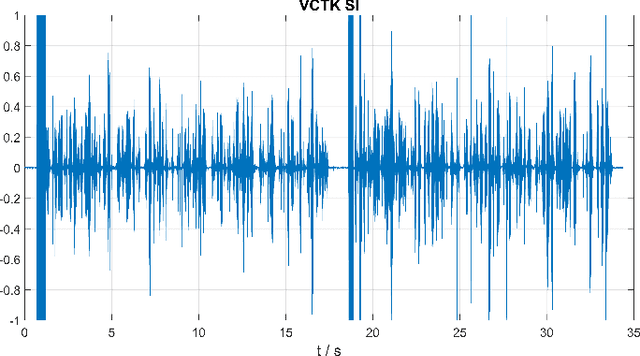
The goal of this contribution is to use a parametric speech synthesis system for reducing background noise and other interferences from recorded speech signals. In a first step, Hidden Markov Models of the synthesis system are trained. Two adequate training corpora consisting of text and corresponding speech files have been set up and cleared of various faults, including inaudible utterances or incorrect assignments between audio and text data. Those are tested and compared against each other regarding e.g. flaws in the synthesized speech, it's naturalness and intelligibility. Thus different voices have been synthesized, whose quality depends less on the number of training samples used, but much more on the cleanliness and signal-to-noise ratio of those. Generalized voice models have been used for synthesis and the results greatly differ between the two speech corpora. Tests regarding the adaptation to different speakers show that a resemblance to the original speaker is audible throughout all recordings, yet the synthesized voices sound robotic and unnatural in smaller parts. The spoken text, however, is usually intelligible, which shows that the models are working well. In a novel approach, speech is synthesized using side information of the original audio signal, particularly the pitch frequency. Results show an increase of speech quality and intelligibility in comparison to speech synthesized solely from text, up to the point of being nearly indistinguishable from the original.
Face Recognition with Machine Learning in OpenCV_ Fusion of the results with the Localization Data of an Acoustic Camera for Speaker Identification
Jul 04, 2017
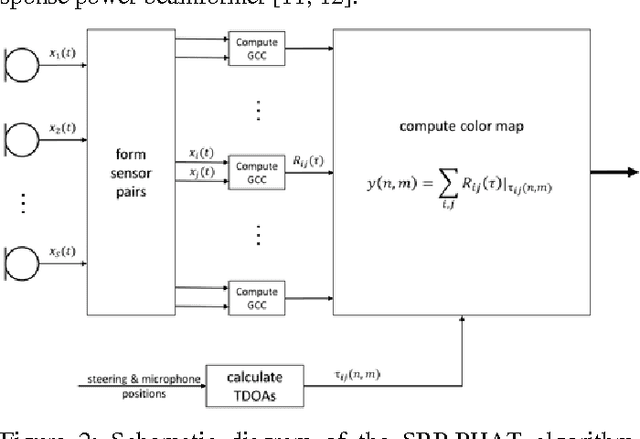

This contribution gives an overview of face recogni-tion algorithms, their implementation and practical uses. First, a training set of different persons' faces has to be collected and used to train a face recognizer. The resulting face model can be utilized to classify people in specific individuals or unknowns. After tracking the recognized face and estimating the acoustic sound source's position, both can be combined to give detailed information about possible speakers and if they are talking or not. This leads to a precise real-time description of the situation, which can be used for further applications, e.g. for multi-channel speech enhancement by adaptive beamformers.
A Bayesian Network View on Acoustic Model-Based Techniques for Robust Speech Recognition
Sep 22, 2014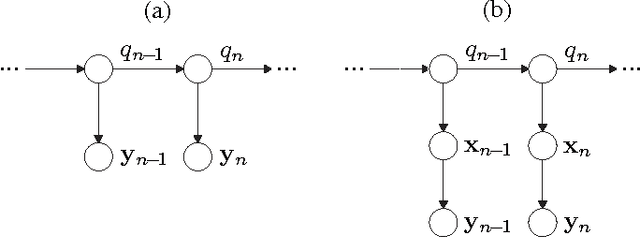
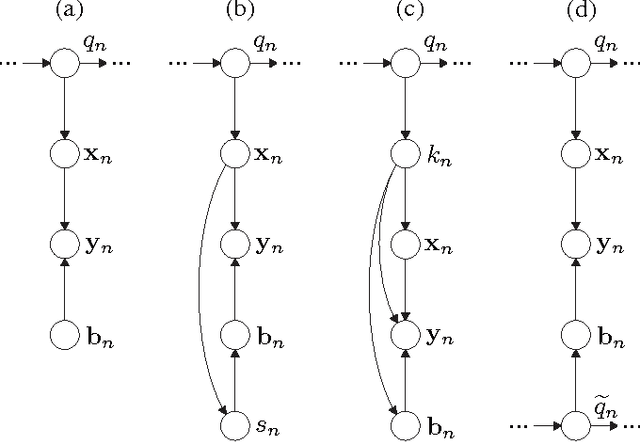
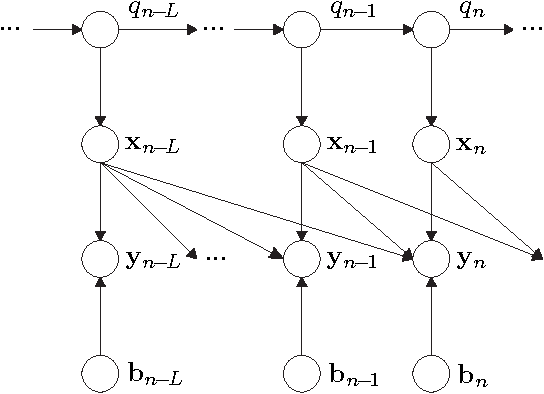
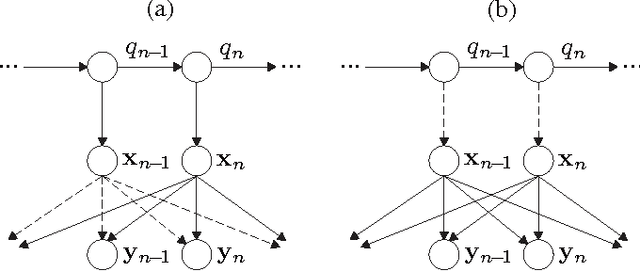
This article provides a unifying Bayesian network view on various approaches for acoustic model adaptation, missing feature, and uncertainty decoding that are well-known in the literature of robust automatic speech recognition. The representatives of these classes can often be deduced from a Bayesian network that extends the conventional hidden Markov models used in speech recognition. These extensions, in turn, can in many cases be motivated from an underlying observation model that relates clean and distorted feature vectors. By converting the observation models into a Bayesian network representation, we formulate the corresponding compensation rules leading to a unified view on known derivations as well as to new formulations for certain approaches. The generic Bayesian perspective provided in this contribution thus highlights structural differences and similarities between the analyzed approaches.