 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Network View on Acoustic Model-Based Techniques for Robust Speech Recognition
Paper and Code
Sep 22, 2014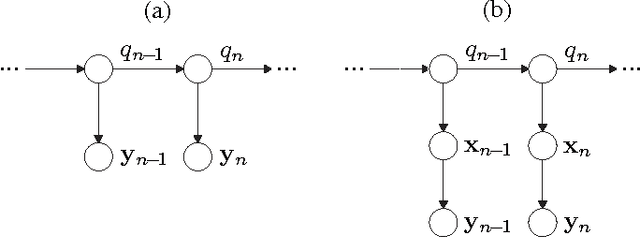
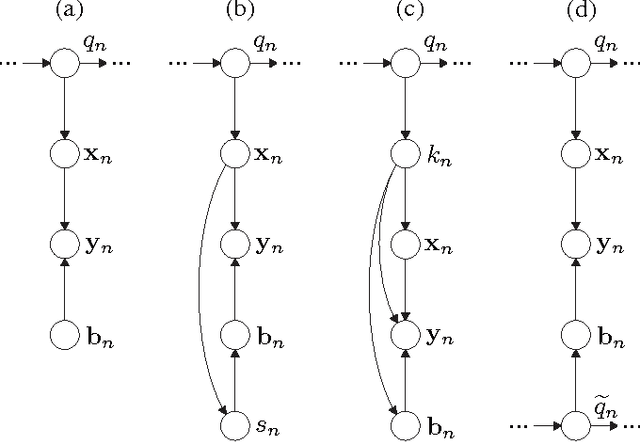
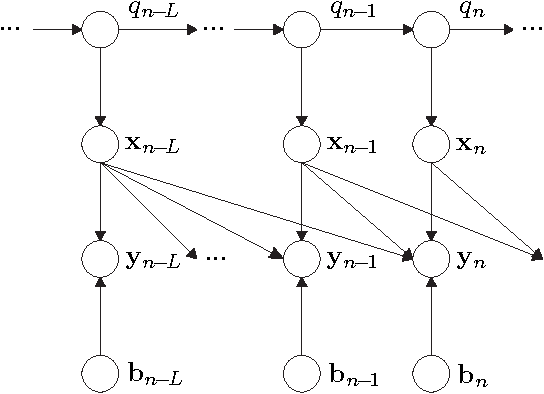
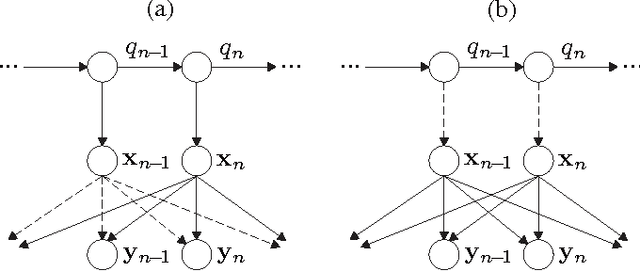
This article provides a unifying Bayesian network view on various approaches for acoustic model adaptation, missing feature, and uncertainty decoding that are well-known in the literature of robust automatic speech recognition. The representatives of these classes can often be deduced from a Bayesian network that extends the conventional hidden Markov models used in speech recognition. These extensions, in turn, can in many cases be motivated from an underlying observation model that relates clean and distorted feature vectors. By converting the observation models into a Bayesian network representation, we formulate the corresponding compensation rules leading to a unified view on known derivations as well as to new formulations for certain approaches. The generic Bayesian perspective provided in this contribution thus highlights structural differences and similarities between the analyzed approaches.