 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data
Feb 15, 2024



We introduce a text-to-speech (TTS) model called BASE TTS, which stands for $\textbf{B}$ig $\textbf{A}$daptive $\textbf{S}$treamable TTS with $\textbf{E}$mergent abilities. BASE TTS is the largest TTS model to-date, trained on 100K hours of public domain speech data, achieving a new state-of-the-art in speech naturalness. It deploys a 1-billion-parameter autoregressive Transformer that converts raw texts into discrete codes ("speechcodes") followed by a convolution-based decoder which converts these speechcodes into waveforms in an incremental, streamable manner. Further, our speechcodes are built using a novel speech tokenization technique that features speaker ID disentanglement and compression with byte-pair encoding. Echoing the widely-reported "emergent abilities" of large language models when trained on increasing volume of data, we show that BASE TTS variants built with 10K+ hours and 500M+ parameters begin to demonstrate natural prosody on textually complex sentences. We design and share a specialized dataset to measure these emergent abilities for text-to-speech. We showcase state-of-the-art naturalness of BASE TTS by evaluating against baselines that include publicly available large-scale text-to-speech systems: YourTTS, Bark and TortoiseTTS. Audio samples generated by the model can be heard at https://amazon-ltts-paper.com/.
Controllable Emphasis with zero data for text-to-speech
Jul 13, 2023We present a scalable method to produce high quality emphasis for text-to-speech (TTS) that does not require recordings or annotations. Many TTS models include a phoneme duration model. A simple but effective method to achieve emphasized speech consists in increasing the predicted duration of the emphasised word. We show that this is significantly better than spectrogram modification techniques improving naturalness by $7.3\%$ and correct testers' identification of the emphasized word in a sentence by $40\%$ on a reference female en-US voice. We show that this technique significantly closes the gap to methods that require explicit recordings. The method proved to be scalable and preferred in all four languages tested (English, Spanish, Italian, German), for different voices and multiple speaking styles.
CopyCat2: A Single Model for Multi-Speaker TTS and Many-to-Many Fine-Grained Prosody Transfer
Jun 27, 2022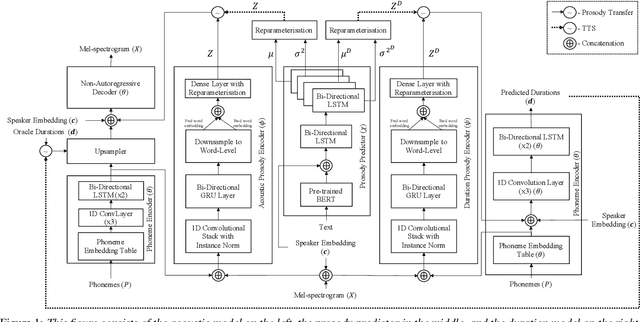
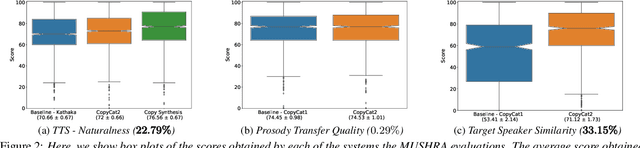
In this paper, we present CopyCat2 (CC2), a novel model capable of: a) synthesizing speech with different speaker identities, b) generating speech with expressive and contextually appropriate prosody, and c) transferring prosody at fine-grained level between any pair of seen speakers. We do this by activating distinct parts of the network for different tasks. We train our model using a novel approach to two-stage training. In Stage I, the model learns speaker-independent word-level prosody representations from speech which it uses for many-to-many fine-grained prosody transfer. In Stage II, we learn to predict these prosody representations using the contextual information available in text, thereby, enabling multi-speaker TTS with contextually appropriate prosody. We compare CC2 to two strong baselines, one in TTS with contextually appropriate prosody, and one in fine-grained prosody transfer. CC2 reduces the gap in naturalness between our baseline and copy-synthesised speech by $22.79\%$. In fine-grained prosody transfer evaluations, it obtains a relative improvement of $33.15\%$ in target speaker similarity.
Distribution augmentation for low-resource expressive text-to-speech
Feb 19, 2022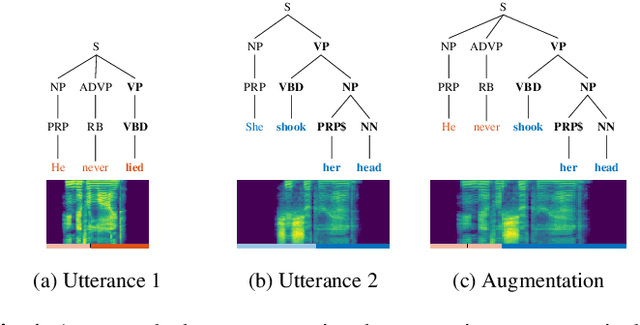
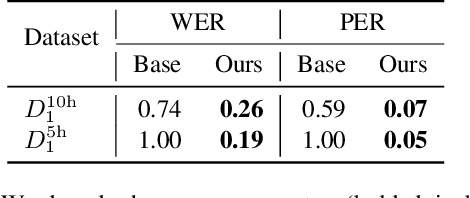
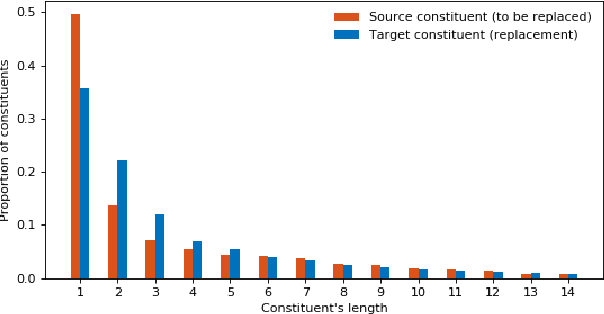
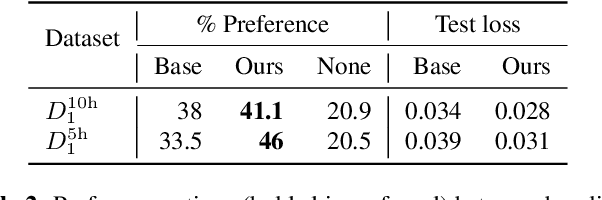
This paper presents a novel data augmentation technique for text-to-speech (TTS), that allows to generate new (text, audio) training examples without requiring any additional data. Our goal is to increase diversity of text conditionings available during training. This helps to reduce overfitting, especially in low-resource settings. Our method relies on substituting text and audio fragments in a way that preserves syntactical correctness. We take additional measures to ensure that synthesized speech does not contain artifacts caused by combining inconsistent audio samples. The perceptual evaluations show that our method improves speech quality over a number of datasets, speakers, and TTS architectures. We also demonstrate that it greatly improves robustness of attention-based TTS models.