 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive, Variable, and Controllable Duration Modelling in TTS
Jun 28, 2022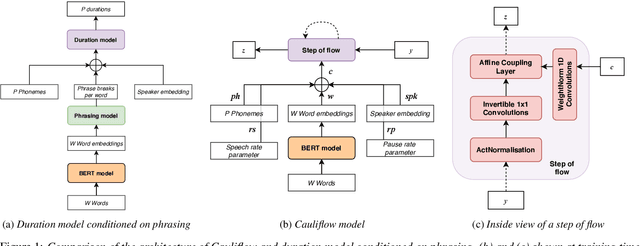
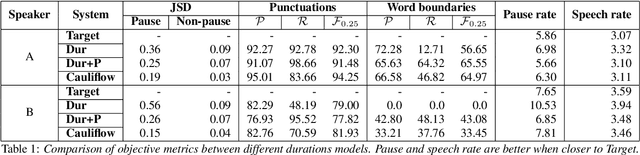
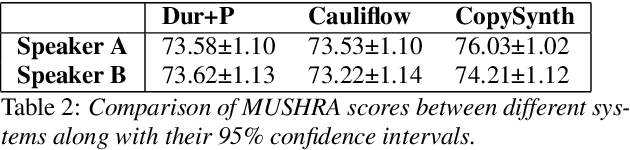
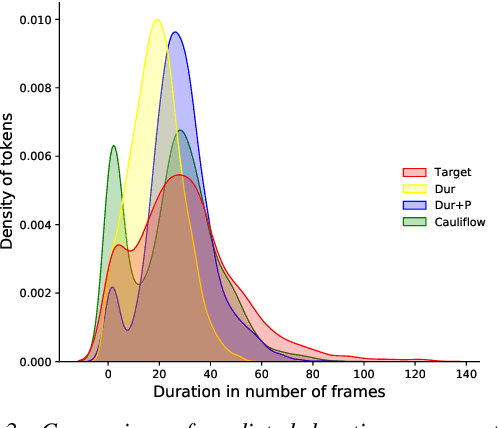
Duration modelling has become an important research problem once more with the rise of non-attention neural text-to-speech systems. The current approaches largely fall back to relying on previous statistical parametric speech synthesis technology for duration prediction, which poorly models the expressiveness and variability in speech. In this paper, we propose two alternate approaches to improve duration modelling. First, we propose a duration model conditioned on phrasing that improves the predicted durations and provides better modelling of pauses. We show that the duration model conditioned on phrasing improves the naturalness of speech over our baseline duration model. Second, we also propose a multi-speaker duration model called Cauliflow, that uses normalising flows to predict durations that better match the complex target duration distribution. Cauliflow performs on par with our other proposed duration model in terms of naturalness, whilst providing variable durations for the same prompt and variable levels of expressiveness. Lastly, we propose to condition Cauliflow on parameters that provide an intuitive control of the pacing and pausing in the synthesised speech in a novel way.
CopyCat2: A Single Model for Multi-Speaker TTS and Many-to-Many Fine-Grained Prosody Transfer
Jun 27, 2022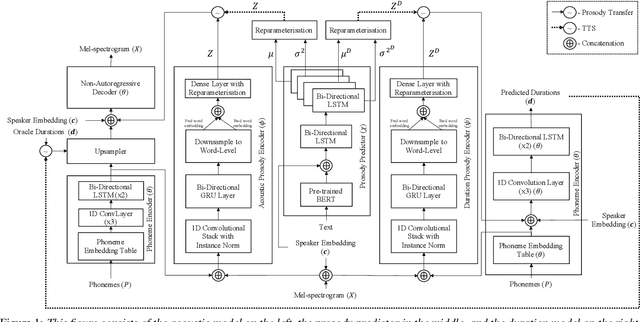
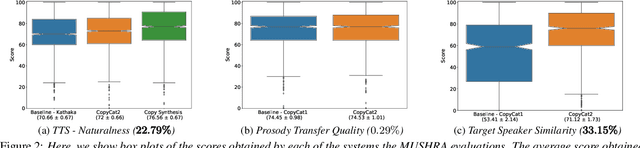
In this paper, we present CopyCat2 (CC2), a novel model capable of: a) synthesizing speech with different speaker identities, b) generating speech with expressive and contextually appropriate prosody, and c) transferring prosody at fine-grained level between any pair of seen speakers. We do this by activating distinct parts of the network for different tasks. We train our model using a novel approach to two-stage training. In Stage I, the model learns speaker-independent word-level prosody representations from speech which it uses for many-to-many fine-grained prosody transfer. In Stage II, we learn to predict these prosody representations using the contextual information available in text, thereby, enabling multi-speaker TTS with contextually appropriate prosody. We compare CC2 to two strong baselines, one in TTS with contextually appropriate prosody, and one in fine-grained prosody transfer. CC2 reduces the gap in naturalness between our baseline and copy-synthesised speech by $22.79\%$. In fine-grained prosody transfer evaluations, it obtains a relative improvement of $33.15\%$ in target speaker similarity.
A learned conditional prior for the VAE acoustic space of a TTS system
Jun 14, 2021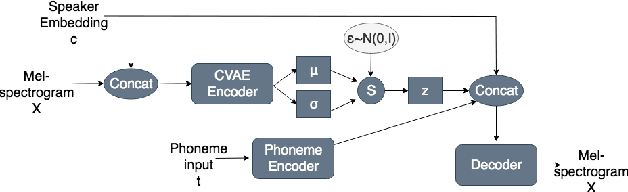
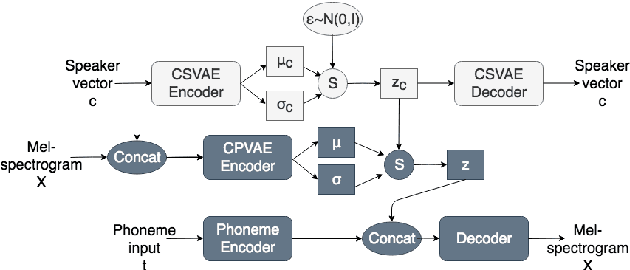
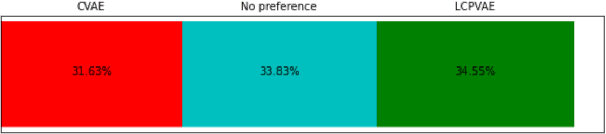
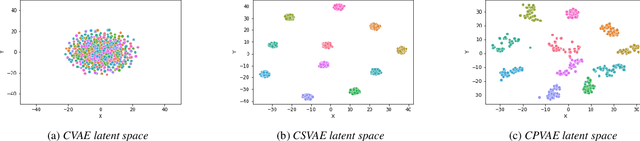
Many factors influence speech yielding different renditions of a given sentence. Generative models, such as variational autoencoders (VAEs), capture this variability and allow multiple renditions of the same sentence via sampling. The degree of prosodic variability depends heavily on the prior that is used when sampling. In this paper, we propose a novel method to compute an informative prior for the VAE latent space of a neural text-to-speech (TTS) system. By doing so, we aim to sample with more prosodic variability, while gaining controllability over the latent space's structure. By using as prior the posterior distribution of a secondary VAE, which we condition on a speaker vector, we can sample from the primary VAE taking explicitly the conditioning into account and resulting in samples from a specific region of the latent space for each condition (i.e. speaker). A formal preference test demonstrates significant preference of the proposed approach over standard Conditional VAE. We also provide visualisations of the latent space where well-separated condition-specific clusters appear, as well as ablation studies to better understand the behaviour of the system.