 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple and Effective Multi-sentence TTS with Expressive and Coherent Prosody
Jun 29, 2022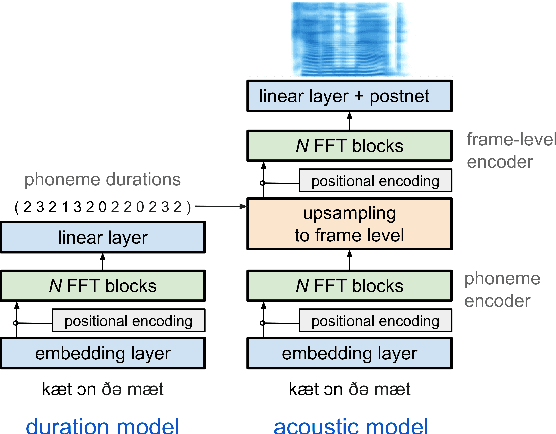

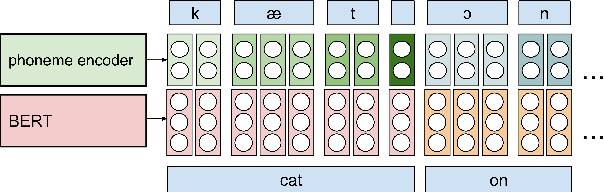
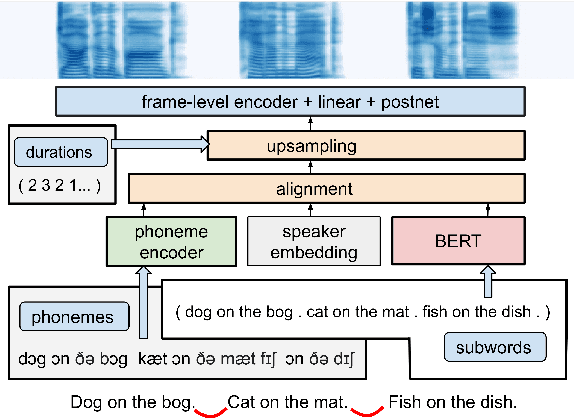
Generating expressive and contextually appropriate prosody remains a challenge for modern text-to-speech (TTS) systems. This is particularly evident for long, multi-sentence inputs. In this paper, we examine simple extensions to a Transformer-based FastSpeech-like system, with the goal of improving prosody for multi-sentence TTS. We find that long context, powerful text features, and training on multi-speaker data all improve prosody. More interestingly, they result in synergies. Long context disambiguates prosody, improves coherence, and plays to the strengths of Transformers. Fine-tuning word-level features from a powerful language model, such as BERT, appears to profit from more training data, readily available in a multi-speaker setting. We look into objective metrics on pausing and pacing and perform thorough subjective evaluations for speech naturalness. Our main system, which incorporates all the extensions, achieves consistently strong results, including statistically significant improvements in speech naturalness over all its competitors.
CopyCat2: A Single Model for Multi-Speaker TTS and Many-to-Many Fine-Grained Prosody Transfer
Jun 27, 2022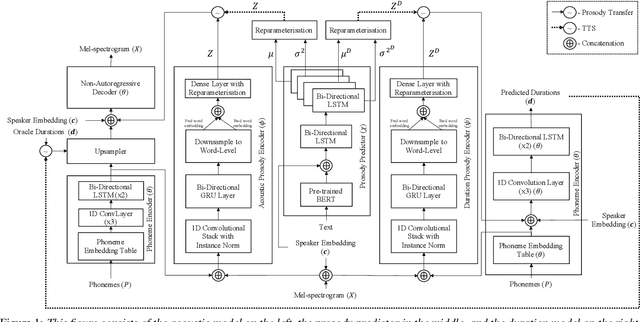
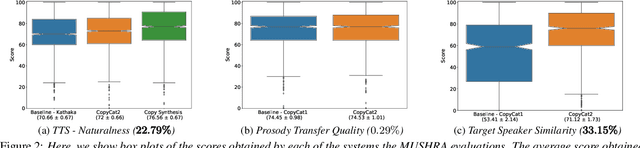
In this paper, we present CopyCat2 (CC2), a novel model capable of: a) synthesizing speech with different speaker identities, b) generating speech with expressive and contextually appropriate prosody, and c) transferring prosody at fine-grained level between any pair of seen speakers. We do this by activating distinct parts of the network for different tasks. We train our model using a novel approach to two-stage training. In Stage I, the model learns speaker-independent word-level prosody representations from speech which it uses for many-to-many fine-grained prosody transfer. In Stage II, we learn to predict these prosody representations using the contextual information available in text, thereby, enabling multi-speaker TTS with contextually appropriate prosody. We compare CC2 to two strong baselines, one in TTS with contextually appropriate prosody, and one in fine-grained prosody transfer. CC2 reduces the gap in naturalness between our baseline and copy-synthesised speech by $22.79\%$. In fine-grained prosody transfer evaluations, it obtains a relative improvement of $33.15\%$ in target speaker similarity.
Multi-Scale Spectrogram Modelling for Neural Text-to-Speech
Jun 29, 2021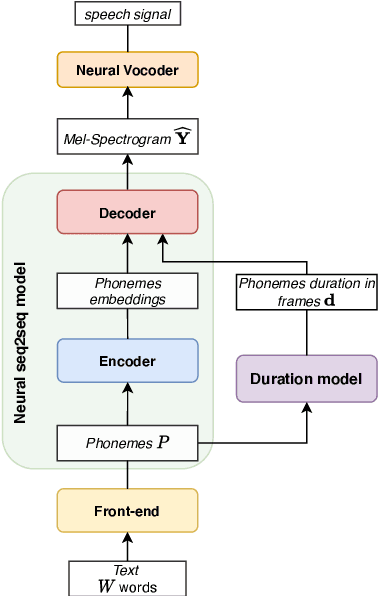
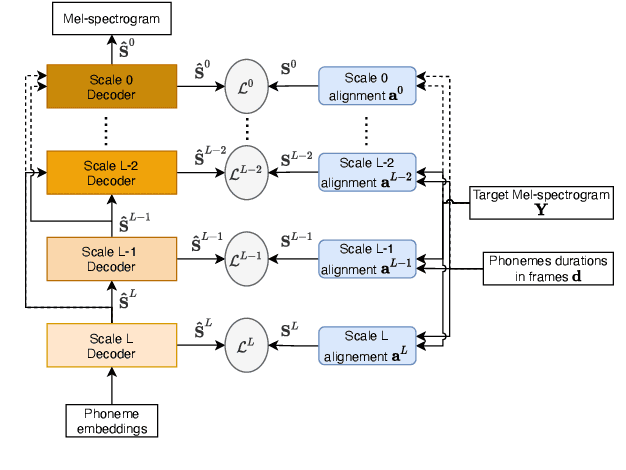
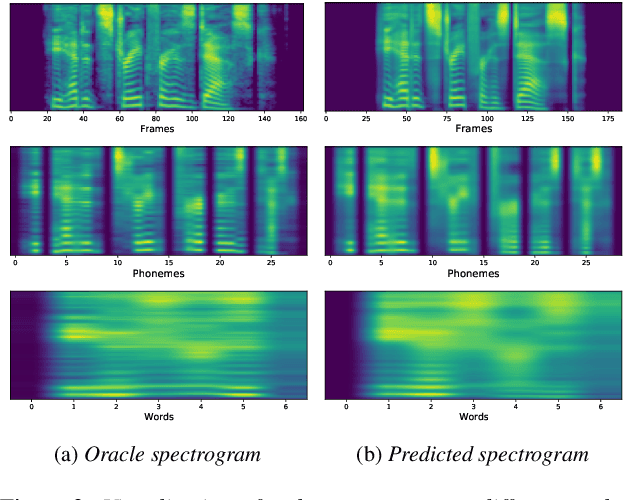
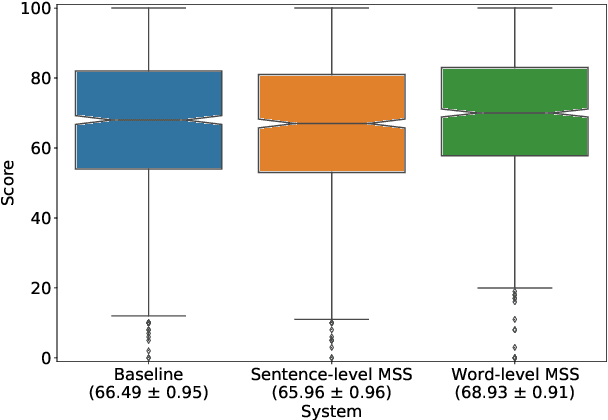
We propose a novel Multi-Scale Spectrogram (MSS) modelling approach to synthesise speech with an improved coarse and fine-grained prosody. We present a generic multi-scale spectrogram prediction mechanism where the system first predicts coarser scale mel-spectrograms that capture the suprasegmental information in speech, and later uses these coarser scale mel-spectrograms to predict finer scale mel-spectrograms capturing fine-grained prosody. We present details for two specific versions of MSS called Word-level MSS and Sentence-level MSS where the scales in our system are motivated by the linguistic units. The Word-level MSS models word, phoneme, and frame-level spectrograms while Sentence-level MSS models sentence-level spectrogram in addition. Subjective evaluations show that Word-level MSS performs statistically significantly better compared to the baseline on two voices.
Imitation Learning for Neural Morphological String Transduction
Aug 31, 2018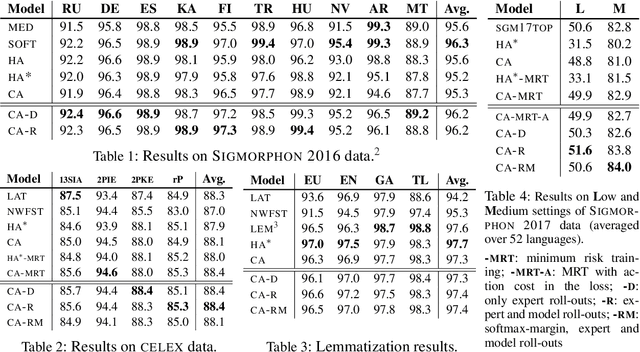
We employ imitation learning to train a neural transition-based string transducer for morphological tasks such as inflection generation and lemmatization. Previous approaches to training this type of model either rely on an external character aligner for the production of gold action sequences, which results in a suboptimal model due to the unwarranted dependence on a single gold action sequence despite spurious ambiguity, or require warm starting with an MLE model. Our approach only requires a simple expert policy, eliminating the need for a character aligner or warm start. It also addresses familiar MLE training biases and leads to strong and state-of-the-art performance on several benchmarks.
Align and Copy: UZH at SIGMORPHON 2017 Shared Task for Morphological Reinflection
Jul 06, 2017

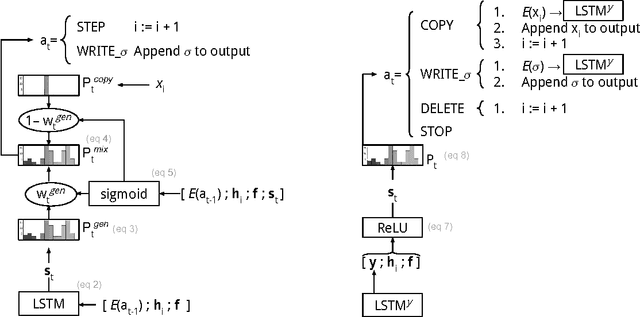
This paper presents the submissions by the University of Zurich to the SIGMORPHON 2017 shared task on morphological reinflection. The task is to predict the inflected form given a lemma and a set of morpho-syntactic features. We focus on neural network approaches that can tackle the task in a limited-resource setting. As the transduction of the lemma into the inflected form is dominated by copying over lemma characters, we propose two recurrent neural network architectures with hard monotonic attention that are strong at copying and, yet, substantially different in how they achieve this. The first approach is an encoder-decoder model with a copy mechanism. The second approach is a neural state-transition system over a set of explicit edit actions, including a designated COPY action. We experiment with character alignment and find that naive, greedy alignment consistently produces strong results for some languages. Our best system combination is the overall winner of the SIGMORPHON 2017 Shared Task 1 without external resources. At a setting with 100 training samples, both our approaches, as ensembles of models, outperform the next best competitor.