 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data
Feb 15, 2024



We introduce a text-to-speech (TTS) model called BASE TTS, which stands for $\textbf{B}$ig $\textbf{A}$daptive $\textbf{S}$treamable TTS with $\textbf{E}$mergent abilities. BASE TTS is the largest TTS model to-date, trained on 100K hours of public domain speech data, achieving a new state-of-the-art in speech naturalness. It deploys a 1-billion-parameter autoregressive Transformer that converts raw texts into discrete codes ("speechcodes") followed by a convolution-based decoder which converts these speechcodes into waveforms in an incremental, streamable manner. Further, our speechcodes are built using a novel speech tokenization technique that features speaker ID disentanglement and compression with byte-pair encoding. Echoing the widely-reported "emergent abilities" of large language models when trained on increasing volume of data, we show that BASE TTS variants built with 10K+ hours and 500M+ parameters begin to demonstrate natural prosody on textually complex sentences. We design and share a specialized dataset to measure these emergent abilities for text-to-speech. We showcase state-of-the-art naturalness of BASE TTS by evaluating against baselines that include publicly available large-scale text-to-speech systems: YourTTS, Bark and TortoiseTTS. Audio samples generated by the model can be heard at https://amazon-ltts-paper.com/.
Controllable Emphasis with zero data for text-to-speech
Jul 13, 2023We present a scalable method to produce high quality emphasis for text-to-speech (TTS) that does not require recordings or annotations. Many TTS models include a phoneme duration model. A simple but effective method to achieve emphasized speech consists in increasing the predicted duration of the emphasised word. We show that this is significantly better than spectrogram modification techniques improving naturalness by $7.3\%$ and correct testers' identification of the emphasized word in a sentence by $40\%$ on a reference female en-US voice. We show that this technique significantly closes the gap to methods that require explicit recordings. The method proved to be scalable and preferred in all four languages tested (English, Spanish, Italian, German), for different voices and multiple speaking styles.
Simple and Effective Multi-sentence TTS with Expressive and Coherent Prosody
Jun 29, 2022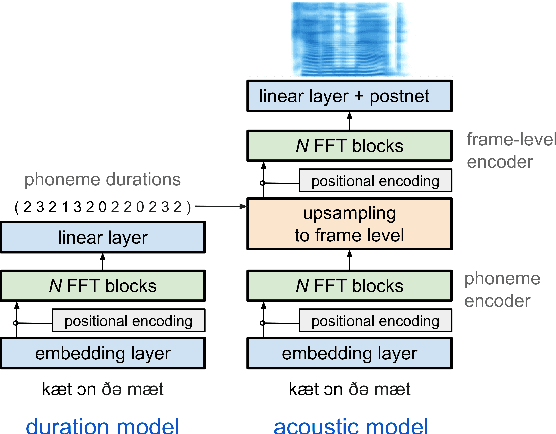

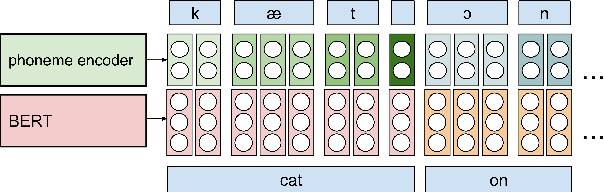
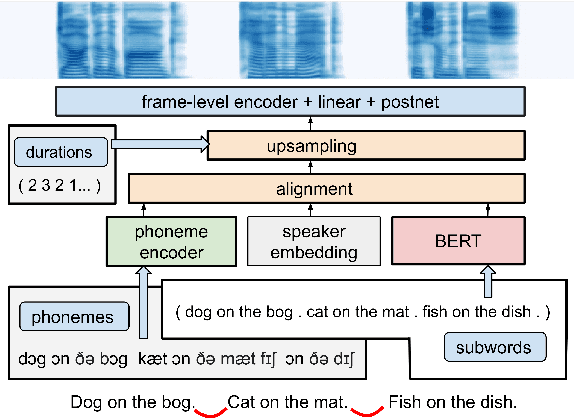
Generating expressive and contextually appropriate prosody remains a challenge for modern text-to-speech (TTS) systems. This is particularly evident for long, multi-sentence inputs. In this paper, we examine simple extensions to a Transformer-based FastSpeech-like system, with the goal of improving prosody for multi-sentence TTS. We find that long context, powerful text features, and training on multi-speaker data all improve prosody. More interestingly, they result in synergies. Long context disambiguates prosody, improves coherence, and plays to the strengths of Transformers. Fine-tuning word-level features from a powerful language model, such as BERT, appears to profit from more training data, readily available in a multi-speaker setting. We look into objective metrics on pausing and pacing and perform thorough subjective evaluations for speech naturalness. Our main system, which incorporates all the extensions, achieves consistently strong results, including statistically significant improvements in speech naturalness over all its competitors.
Distribution augmentation for low-resource expressive text-to-speech
Feb 19, 2022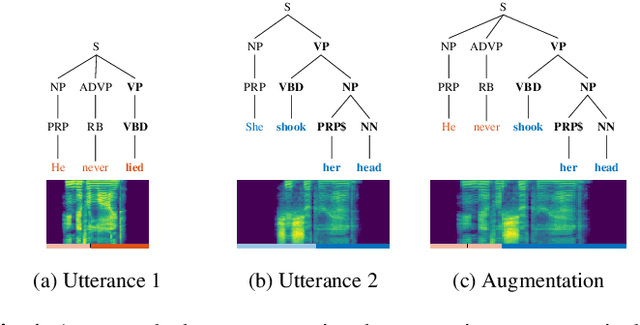
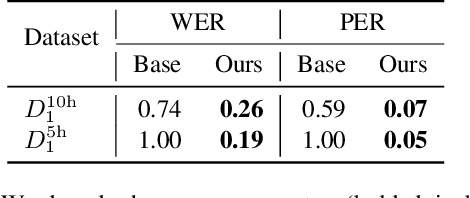
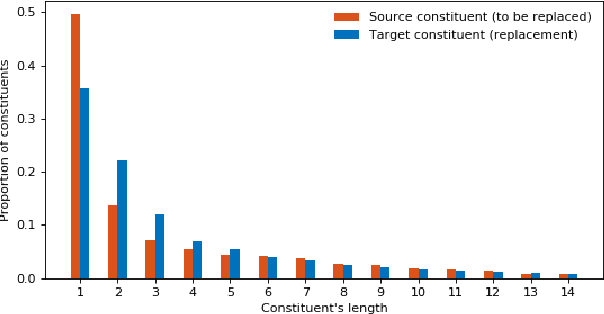
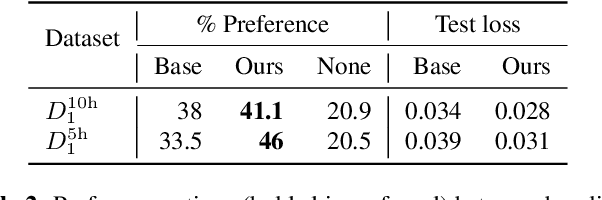
This paper presents a novel data augmentation technique for text-to-speech (TTS), that allows to generate new (text, audio) training examples without requiring any additional data. Our goal is to increase diversity of text conditionings available during training. This helps to reduce overfitting, especially in low-resource settings. Our method relies on substituting text and audio fragments in a way that preserves syntactical correctness. We take additional measures to ensure that synthesized speech does not contain artifacts caused by combining inconsistent audio samples. The perceptual evaluations show that our method improves speech quality over a number of datasets, speakers, and TTS architectures. We also demonstrate that it greatly improves robustness of attention-based TTS models.
Multi-Scale Spectrogram Modelling for Neural Text-to-Speech
Jun 29, 2021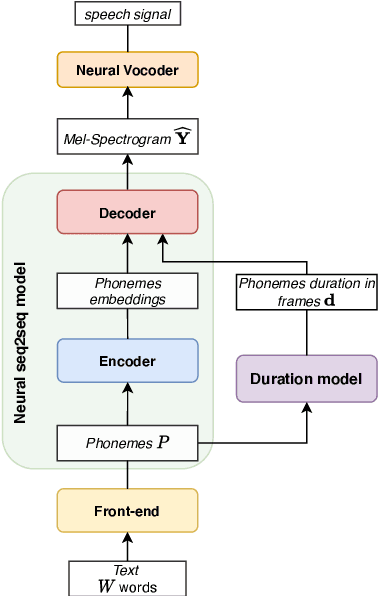
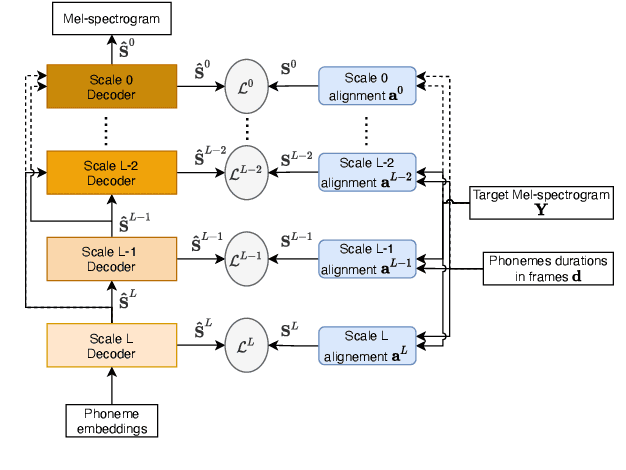
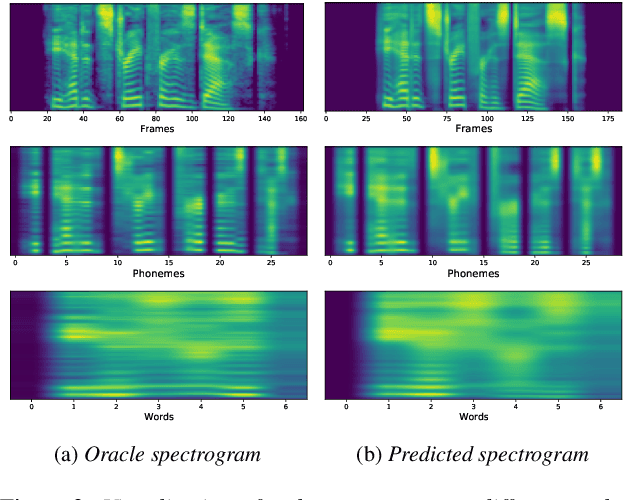
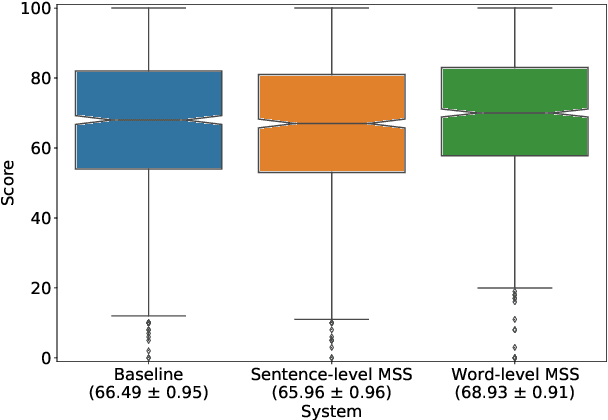
We propose a novel Multi-Scale Spectrogram (MSS) modelling approach to synthesise speech with an improved coarse and fine-grained prosody. We present a generic multi-scale spectrogram prediction mechanism where the system first predicts coarser scale mel-spectrograms that capture the suprasegmental information in speech, and later uses these coarser scale mel-spectrograms to predict finer scale mel-spectrograms capturing fine-grained prosody. We present details for two specific versions of MSS called Word-level MSS and Sentence-level MSS where the scales in our system are motivated by the linguistic units. The Word-level MSS models word, phoneme, and frame-level spectrograms while Sentence-level MSS models sentence-level spectrogram in addition. Subjective evaluations show that Word-level MSS performs statistically significantly better compared to the baseline on two voices.
A learned conditional prior for the VAE acoustic space of a TTS system
Jun 14, 2021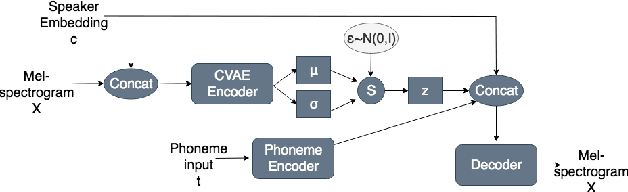
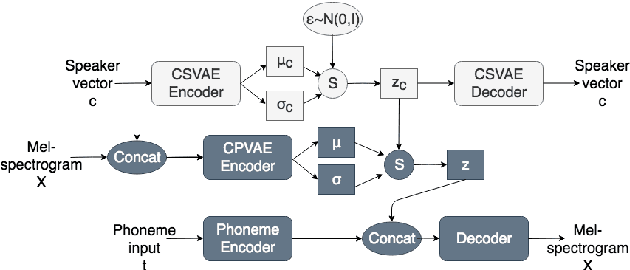
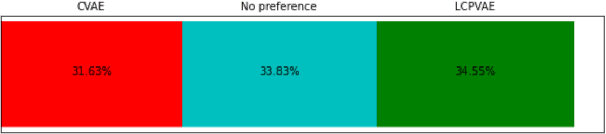
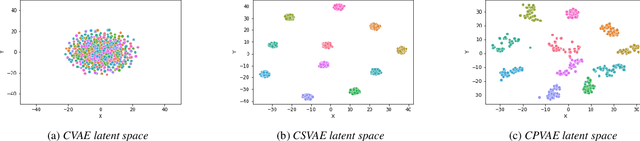
Many factors influence speech yielding different renditions of a given sentence. Generative models, such as variational autoencoders (VAEs), capture this variability and allow multiple renditions of the same sentence via sampling. The degree of prosodic variability depends heavily on the prior that is used when sampling. In this paper, we propose a novel method to compute an informative prior for the VAE latent space of a neural text-to-speech (TTS) system. By doing so, we aim to sample with more prosodic variability, while gaining controllability over the latent space's structure. By using as prior the posterior distribution of a secondary VAE, which we condition on a speaker vector, we can sample from the primary VAE taking explicitly the conditioning into account and resulting in samples from a specific region of the latent space for each condition (i.e. speaker). A formal preference test demonstrates significant preference of the proposed approach over standard Conditional VAE. We also provide visualisations of the latent space where well-separated condition-specific clusters appear, as well as ablation studies to better understand the behaviour of the system.
Prosodic Representation Learning and Contextual Sampling for Neural Text-to-Speech
Nov 04, 2020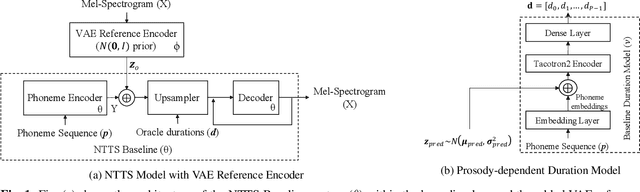
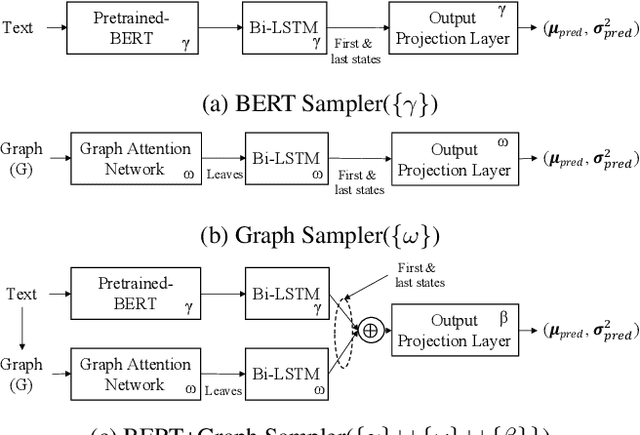
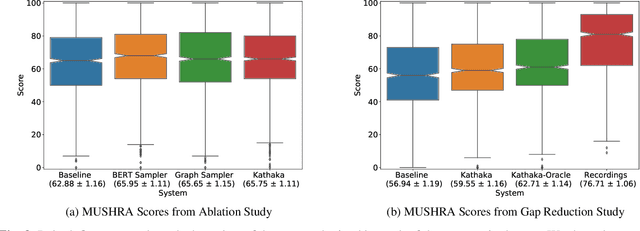
In this paper, we introduce Kathaka, a model trained with a novel two-stage training process for neural speech synthesis with contextually appropriate prosody. In Stage I, we learn a prosodic distribution at the sentence level from mel-spectrograms available during training. In Stage II, we propose a novel method to sample from this learnt prosodic distribution using the contextual information available in text. To do this, we use BERT on text, and graph-attention networks on parse trees extracted from text. We show a statistically significant relative improvement of $13.2\%$ in naturalness over a strong baseline when compared to recordings. We also conduct an ablation study on variations of our sampling technique, and show a statistically significant improvement over the baseline in each case.
Gradient tree boosting with random output projections for multi-label classification and multi-output regression
May 18, 2019
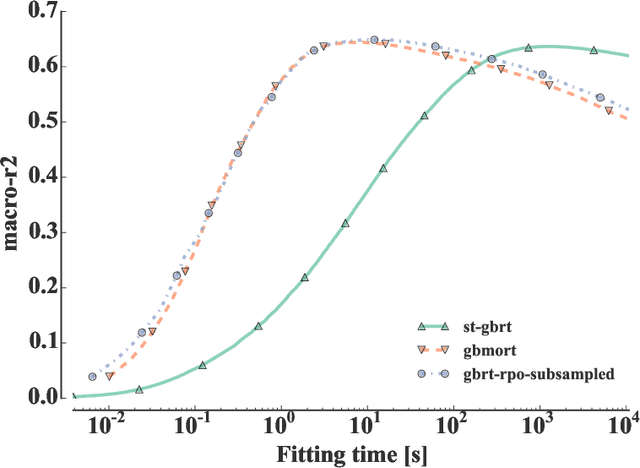
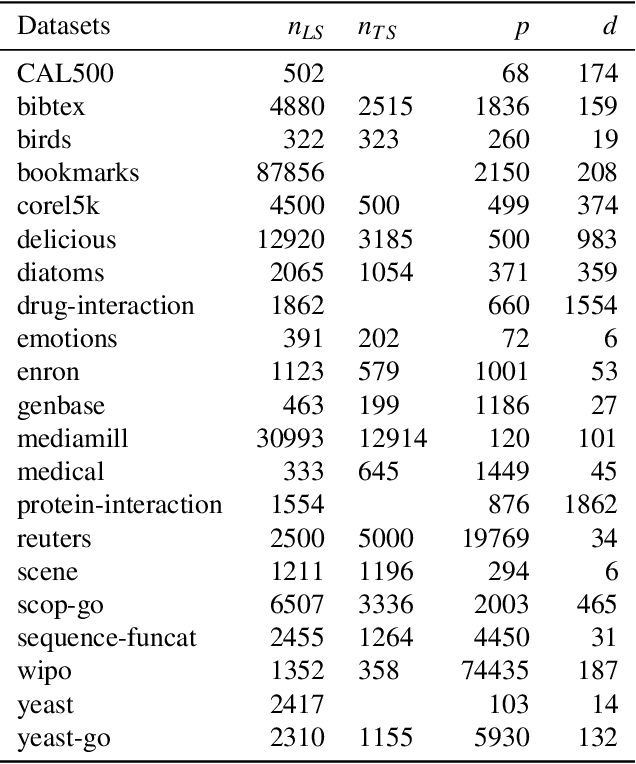
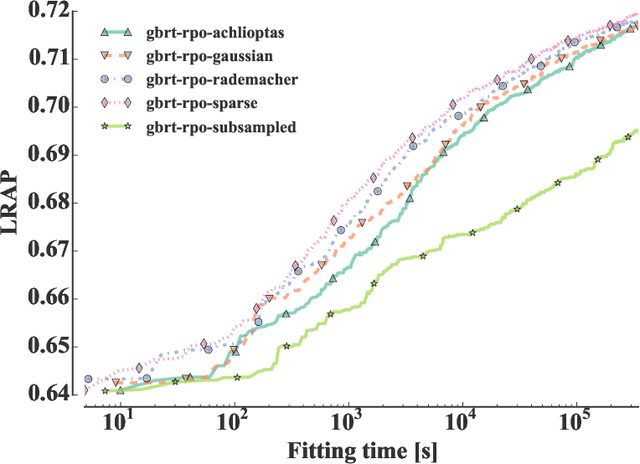
In many applications of supervised learning, multiple classification or regression outputs have to be predicted jointly. We consider several extensions of gradient boosting to address such problems. We first propose a straightforward adaptation of gradient boosting exploiting multiple output regression trees as base learners. We then argue that this method is only expected to be optimal when the outputs are fully correlated, as it forces the partitioning induced by the tree base learners to be shared by all outputs. We then propose a novel extension of gradient tree boosting to specifically address this issue. At each iteration of this new method, a regression tree structure is grown to fit a single random projection of the current residuals and the predictions of this tree are fitted linearly to the current residuals of all the outputs, independently. Because of this linear fit, the method can adapt automatically to any output correlation structure. Extensive experiments are conducted with this method, as well as other algorithmic variants, on several artificial and real problems. Randomly projecting the output space is shown to provide a better adaptation to different output correlation patterns and is therefore competitive with the best of the other methods in most settings. Thanks to model sharing, the convergence speed is also improved, reducing the computing times (or the complexity of the model) to reach a specific accuracy.
Exploiting random projections and sparsity with random forests and gradient boosting methods -- Application to multi-label and multi-output learning, random forest model compression and leveraging input sparsity
Apr 26, 2017

Within machine learning, the supervised learning field aims at modeling the input-output relationship of a system, from past observations of its behavior. Decision trees characterize the input-output relationship through a series of nested $if-then-else$ questions, the testing nodes, leading to a set of predictions, the leaf nodes. Several of such trees are often combined together for state-of-the-art performance: random forest ensembles average the predictions of randomized decision trees trained independently in parallel, while tree boosting ensembles train decision trees sequentially to refine the predictions made by the previous ones. The emergence of new applications requires scalable supervised learning algorithms in terms of computational power and memory space with respect to the number of inputs, outputs, and observations without sacrificing accuracy. In this thesis, we identify three main areas where decision tree methods could be improved for which we provide and evaluate original algorithmic solutions: (i) learning over high dimensional output spaces, (ii) learning with large sample datasets and stringent memory constraints at prediction time and (iii) learning over high dimensional sparse input spaces.
Simple connectome inference from partial correlation statistics in calcium imaging
Nov 18, 2014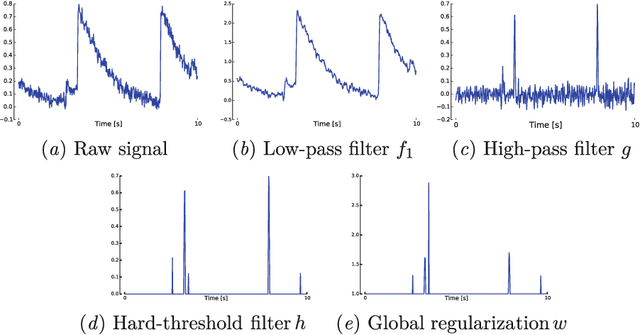
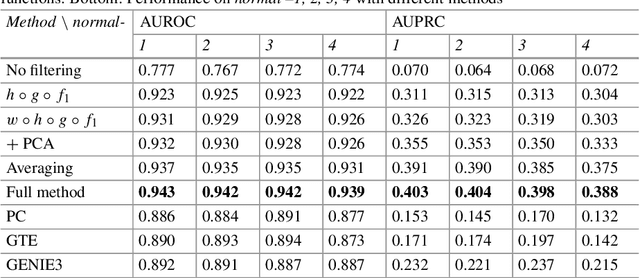
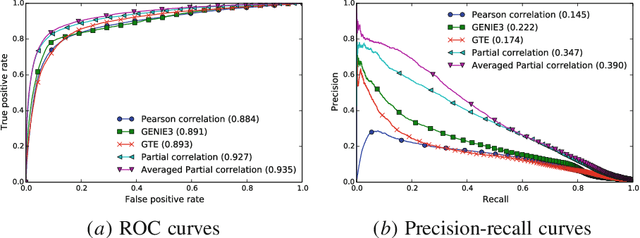

In this work, we propose a simple yet effective solution to the problem of connectome inference in calcium imaging data. The proposed algorithm consists of two steps. First, processing the raw signals to detect neural peak activities. Second, inferring the degree of association between neurons from partial correlation statistics. This paper summarises the methodology that led us to win the Connectomics Challenge, proposes a simplified version of our method, and finally compares our results with respect to other inference methods.