 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA learned conditional prior for the VAE acoustic space of a TTS system
Jun 14, 2021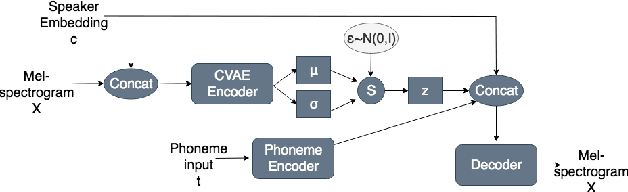
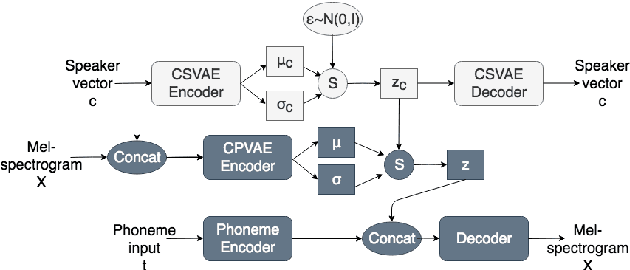
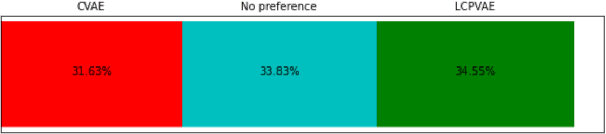
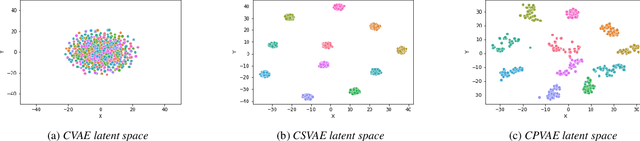
Many factors influence speech yielding different renditions of a given sentence. Generative models, such as variational autoencoders (VAEs), capture this variability and allow multiple renditions of the same sentence via sampling. The degree of prosodic variability depends heavily on the prior that is used when sampling. In this paper, we propose a novel method to compute an informative prior for the VAE latent space of a neural text-to-speech (TTS) system. By doing so, we aim to sample with more prosodic variability, while gaining controllability over the latent space's structure. By using as prior the posterior distribution of a secondary VAE, which we condition on a speaker vector, we can sample from the primary VAE taking explicitly the conditioning into account and resulting in samples from a specific region of the latent space for each condition (i.e. speaker). A formal preference test demonstrates significant preference of the proposed approach over standard Conditional VAE. We also provide visualisations of the latent space where well-separated condition-specific clusters appear, as well as ablation studies to better understand the behaviour of the system.