 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Emphasis with zero data for text-to-speech
Jul 13, 2023We present a scalable method to produce high quality emphasis for text-to-speech (TTS) that does not require recordings or annotations. Many TTS models include a phoneme duration model. A simple but effective method to achieve emphasized speech consists in increasing the predicted duration of the emphasised word. We show that this is significantly better than spectrogram modification techniques improving naturalness by $7.3\%$ and correct testers' identification of the emphasized word in a sentence by $40\%$ on a reference female en-US voice. We show that this technique significantly closes the gap to methods that require explicit recordings. The method proved to be scalable and preferred in all four languages tested (English, Spanish, Italian, German), for different voices and multiple speaking styles.
Distribution augmentation for low-resource expressive text-to-speech
Feb 19, 2022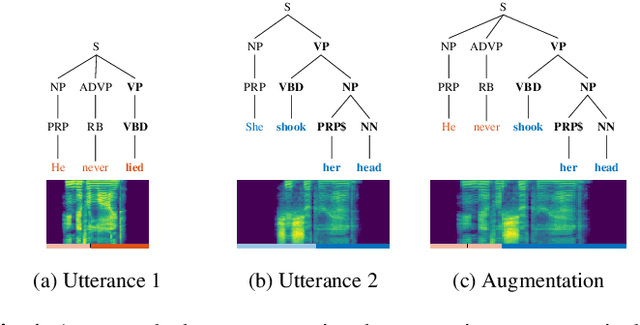
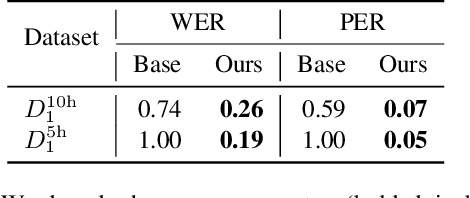
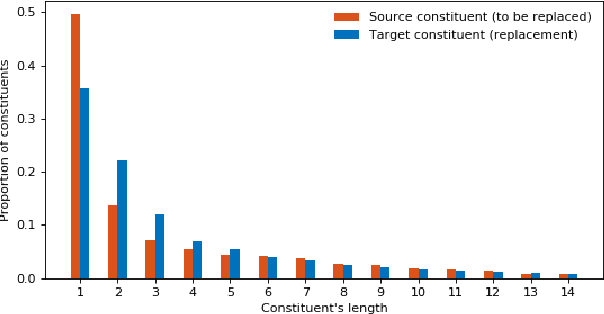
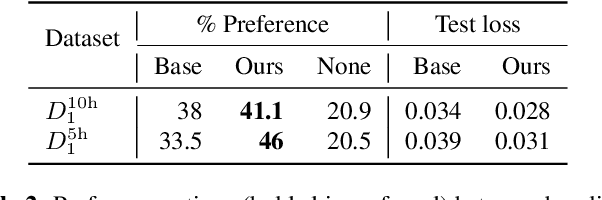
This paper presents a novel data augmentation technique for text-to-speech (TTS), that allows to generate new (text, audio) training examples without requiring any additional data. Our goal is to increase diversity of text conditionings available during training. This helps to reduce overfitting, especially in low-resource settings. Our method relies on substituting text and audio fragments in a way that preserves syntactical correctness. We take additional measures to ensure that synthesized speech does not contain artifacts caused by combining inconsistent audio samples. The perceptual evaluations show that our method improves speech quality over a number of datasets, speakers, and TTS architectures. We also demonstrate that it greatly improves robustness of attention-based TTS models.
Dynamic Prosody Generation for Speech Synthesis using Linguistics-Driven Acoustic Embedding Selection
Dec 02, 2019

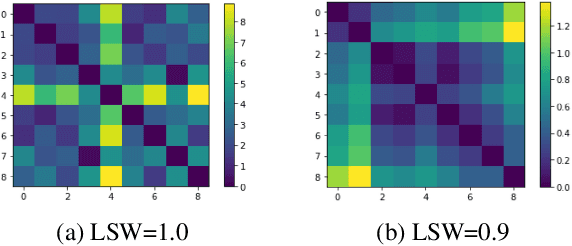
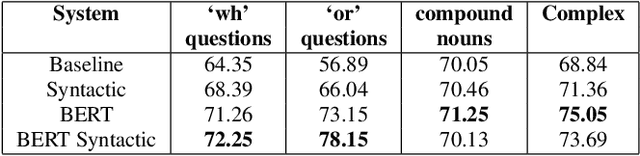
Recent advances in Text-to-Speech (TTS) have improved quality and naturalness to near-human capabilities when considering isolated sentences. But something which is still lacking in order to achieve human-like communication is the dynamic variations and adaptability of human speech. This work attempts to solve the problem of achieving a more dynamic and natural intonation in TTS systems, particularly for stylistic speech such as the newscaster speaking style. We propose a novel embedding selection approach which exploits linguistic information, leveraging the speech variability present in the training dataset. We analyze the contribution of both semantic and syntactic features. Our results show that the approach improves the prosody and naturalness for complex utterances as well as in Long Form Reading (LFR).