 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluCana: Fixing LLM Hallucination with A Canary Lookahead
Dec 10, 2024In this paper, we present HalluCana, a canary lookahead to detect and correct factuality hallucinations of Large Language Models (LLMs) in long-form generation. HalluCana detects and intervenes as soon as traces of hallucination emerge, during and even before generation. To support timely detection, we exploit the internal factuality representation in the LLM hidden space, where we investigate various proxies to the LLMs' factuality self-assessment, and discuss its relation to the models' context familiarity from their pre-training. On biography generation, our method improves generation quality by up to 2.5x, while consuming over 6 times less compute.
REXEL: An End-to-end Model for Document-Level Relation Extraction and Entity Linking
Apr 19, 2024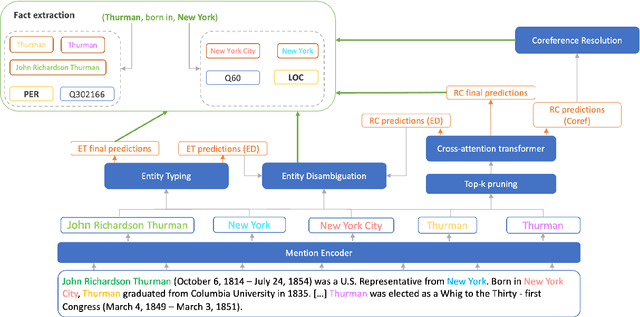
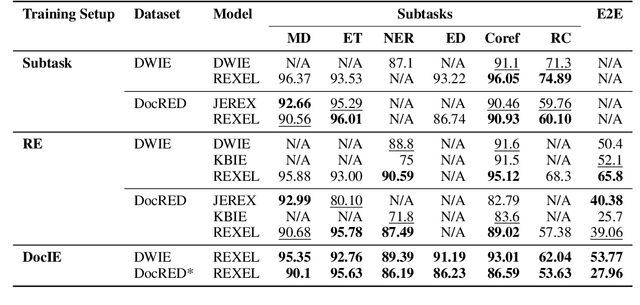
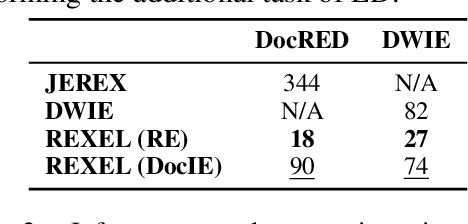
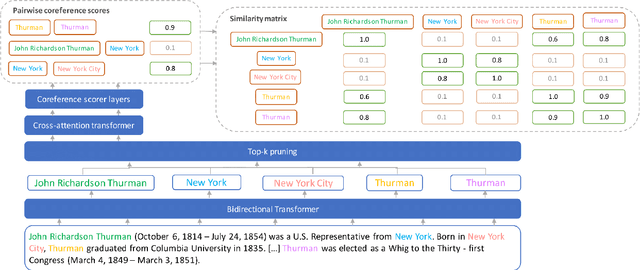
Extracting structured information from unstructured text is critical for many downstream NLP applications and is traditionally achieved by closed information extraction (cIE). However, existing approaches for cIE suffer from two limitations: (i) they are often pipelines which makes them prone to error propagation, and/or (ii) they are restricted to sentence level which prevents them from capturing long-range dependencies and results in expensive inference time. We address these limitations by proposing REXEL, a highly efficient and accurate model for the joint task of document level cIE (DocIE). REXEL performs mention detection, entity typing, entity disambiguation, coreference resolution and document-level relation classification in a single forward pass to yield facts fully linked to a reference knowledge graph. It is on average 11 times faster than competitive existing approaches in a similar setting and performs competitively both when optimised for any of the individual subtasks and a variety of combinations of different joint tasks, surpassing the baselines by an average of more than 6 F1 points. The combination of speed and accuracy makes REXEL an accurate cost-efficient system for extracting structured information at web-scale. We also release an extension of the DocRED dataset to enable benchmarking of future work on DocIE, which is available at https://github.com/amazon-science/e2e-docie.
ReFinED: An Efficient Zero-shot-capable Approach to End-to-End Entity Linking
Jul 08, 2022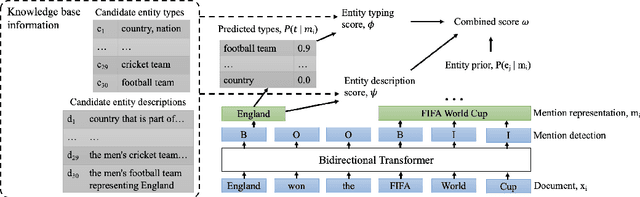
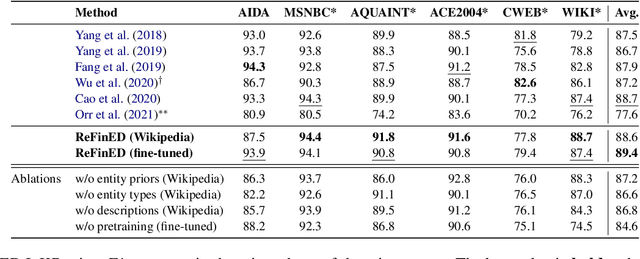
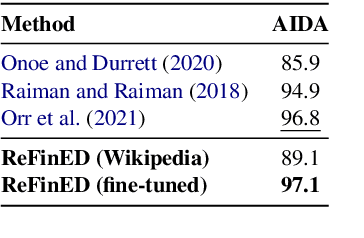
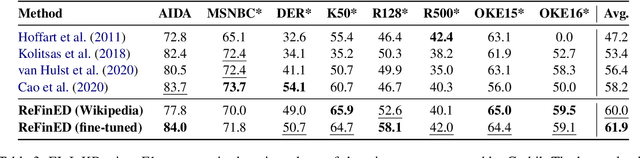
We introduce ReFinED, an efficient end-to-end entity linking model which uses fine-grained entity types and entity descriptions to perform linking. The model performs mention detection, fine-grained entity typing, and entity disambiguation for all mentions within a document in a single forward pass, making it more than 60 times faster than competitive existing approaches. ReFinED also surpasses state-of-the-art performance on standard entity linking datasets by an average of 3.7 F1. The model is capable of generalising to large-scale knowledge bases such as Wikidata (which has 15 times more entities than Wikipedia) and of zero-shot entity linking. The combination of speed, accuracy and scale makes ReFinED an effective and cost-efficient system for extracting entities from web-scale datasets, for which the model has been successfully deployed. Our code and pre-trained models are available at https://github.com/alexa/ReFinED
Proteno: Text Normalization with Limited Data for Fast Deployment in Text to Speech Systems
Apr 15, 2021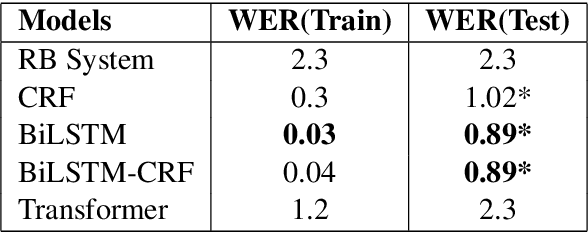
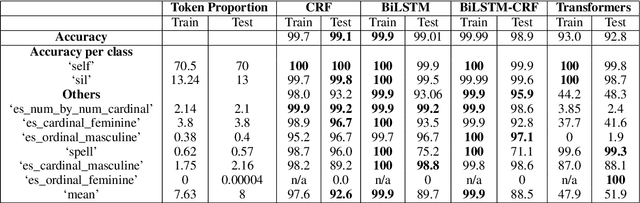


Developing Text Normalization (TN) systems for Text-to-Speech (TTS) on new languages is hard. We propose a novel architecture to facilitate it for multiple languages while using data less than 3% of the size of the data used by the state of the art results on English. We treat TN as a sequence classification problem and propose a granular tokenization mechanism that enables the system to learn majority of the classes and their normalizations from the training data itself. This is further combined with minimal precoded linguistic knowledge for other classes. We publish the first results on TN for TTS in Spanish and Tamil and also demonstrate that the performance of the approach is comparable with the previous work done on English. All annotated datasets used for experimentation will be released at https://github.com/amazon-research/proteno.
Dynamic Prosody Generation for Speech Synthesis using Linguistics-Driven Acoustic Embedding Selection
Dec 02, 2019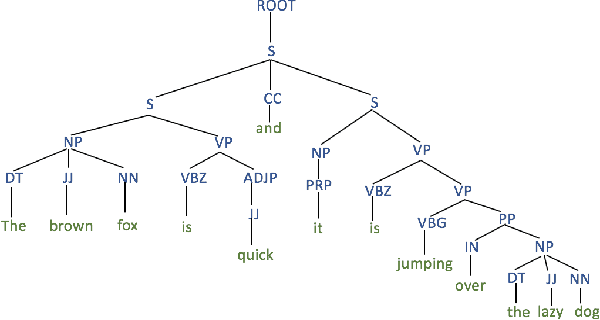

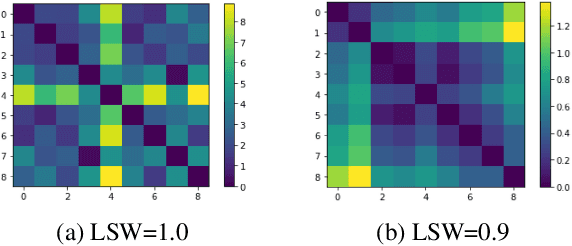
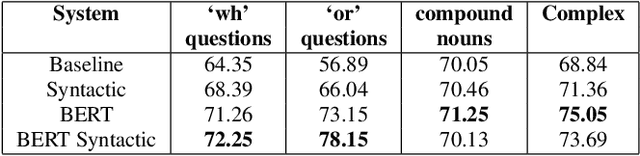
Recent advances in Text-to-Speech (TTS) have improved quality and naturalness to near-human capabilities when considering isolated sentences. But something which is still lacking in order to achieve human-like communication is the dynamic variations and adaptability of human speech. This work attempts to solve the problem of achieving a more dynamic and natural intonation in TTS systems, particularly for stylistic speech such as the newscaster speaking style. We propose a novel embedding selection approach which exploits linguistic information, leveraging the speech variability present in the training dataset. We analyze the contribution of both semantic and syntactic features. Our results show that the approach improves the prosody and naturalness for complex utterances as well as in Long Form Reading (LFR).