 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluCana: Fixing LLM Hallucination with A Canary Lookahead
Dec 10, 2024In this paper, we present HalluCana, a canary lookahead to detect and correct factuality hallucinations of Large Language Models (LLMs) in long-form generation. HalluCana detects and intervenes as soon as traces of hallucination emerge, during and even before generation. To support timely detection, we exploit the internal factuality representation in the LLM hidden space, where we investigate various proxies to the LLMs' factuality self-assessment, and discuss its relation to the models' context familiarity from their pre-training. On biography generation, our method improves generation quality by up to 2.5x, while consuming over 6 times less compute.
REXEL: An End-to-end Model for Document-Level Relation Extraction and Entity Linking
Apr 19, 2024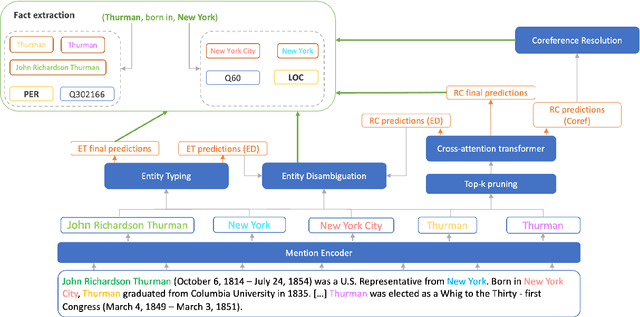
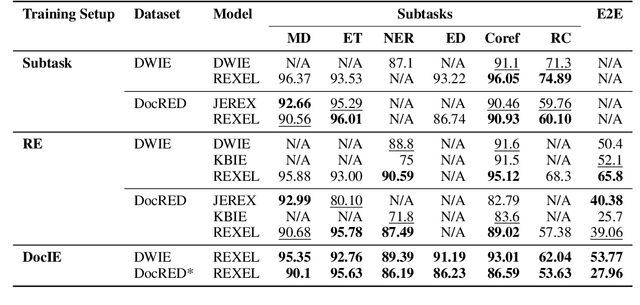
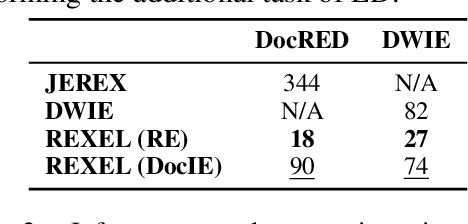
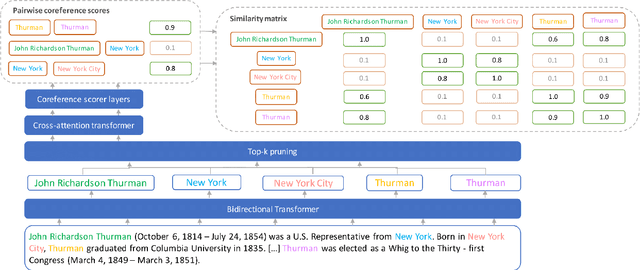
Extracting structured information from unstructured text is critical for many downstream NLP applications and is traditionally achieved by closed information extraction (cIE). However, existing approaches for cIE suffer from two limitations: (i) they are often pipelines which makes them prone to error propagation, and/or (ii) they are restricted to sentence level which prevents them from capturing long-range dependencies and results in expensive inference time. We address these limitations by proposing REXEL, a highly efficient and accurate model for the joint task of document level cIE (DocIE). REXEL performs mention detection, entity typing, entity disambiguation, coreference resolution and document-level relation classification in a single forward pass to yield facts fully linked to a reference knowledge graph. It is on average 11 times faster than competitive existing approaches in a similar setting and performs competitively both when optimised for any of the individual subtasks and a variety of combinations of different joint tasks, surpassing the baselines by an average of more than 6 F1 points. The combination of speed and accuracy makes REXEL an accurate cost-efficient system for extracting structured information at web-scale. We also release an extension of the DocRED dataset to enable benchmarking of future work on DocIE, which is available at https://github.com/amazon-science/e2e-docie.
WebIE: Faithful and Robust Information Extraction on the Web
May 23, 2023Extracting structured and grounded fact triples from raw text is a fundamental task in Information Extraction (IE). Existing IE datasets are typically collected from Wikipedia articles, using hyperlinks to link entities to the Wikidata knowledge base. However, models trained only on Wikipedia have limitations when applied to web domains, which often contain noisy text or text that does not have any factual information. We present WebIE, the first large-scale, entity-linked closed IE dataset consisting of 1.6M sentences automatically collected from the English Common Crawl corpus. WebIE also includes negative examples, i.e. sentences without fact triples, to better reflect the data on the web. We annotate ~25K triples from WebIE through crowdsourcing and introduce mWebIE, a translation of the annotated set in four other languages: French, Spanish, Portuguese, and Hindi. We evaluate the in-domain, out-of-domain, and zero-shot cross-lingual performance of generative IE models and find models trained on WebIE show better generalisability. We also propose three training strategies that use entity linking as an auxiliary task. Our experiments show that adding Entity-Linking objectives improves the faithfulness of our generative IE models.
ReFinED: An Efficient Zero-shot-capable Approach to End-to-End Entity Linking
Jul 08, 2022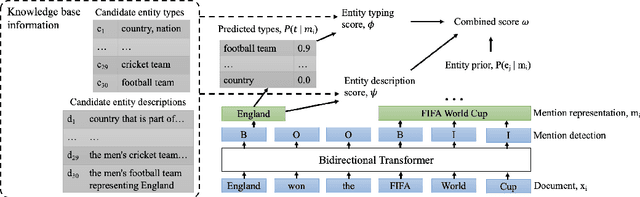
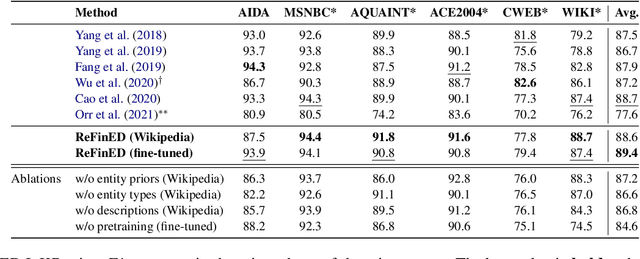
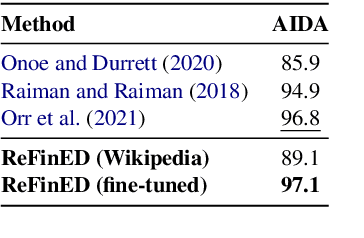
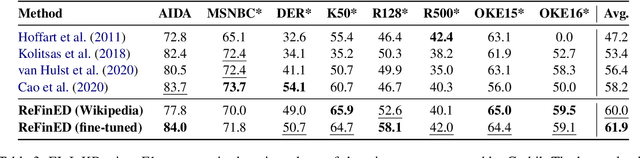
We introduce ReFinED, an efficient end-to-end entity linking model which uses fine-grained entity types and entity descriptions to perform linking. The model performs mention detection, fine-grained entity typing, and entity disambiguation for all mentions within a document in a single forward pass, making it more than 60 times faster than competitive existing approaches. ReFinED also surpasses state-of-the-art performance on standard entity linking datasets by an average of 3.7 F1. The model is capable of generalising to large-scale knowledge bases such as Wikidata (which has 15 times more entities than Wikipedia) and of zero-shot entity linking. The combination of speed, accuracy and scale makes ReFinED an effective and cost-efficient system for extracting entities from web-scale datasets, for which the model has been successfully deployed. Our code and pre-trained models are available at https://github.com/alexa/ReFinED
Improving Entity Disambiguation by Reasoning over a Knowledge Base
Jul 08, 2022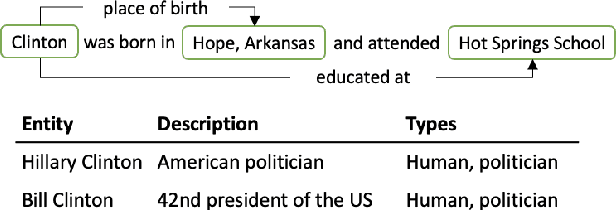
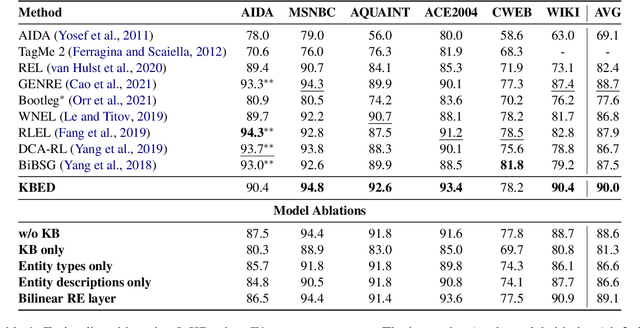
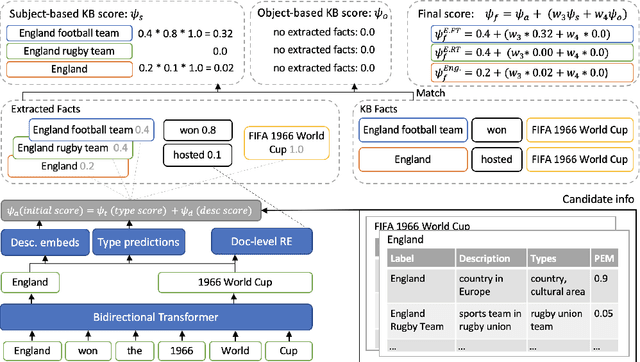
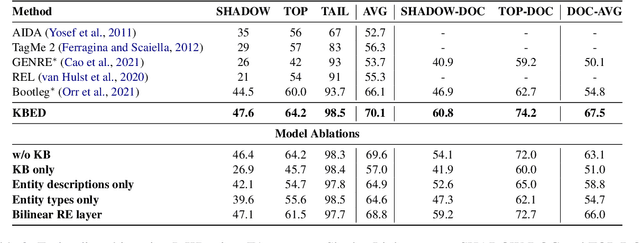
Recent work in entity disambiguation (ED) has typically neglected structured knowledge base (KB) facts, and instead relied on a limited subset of KB information, such as entity descriptions or types. This limits the range of contexts in which entities can be disambiguated. To allow the use of all KB facts, as well as descriptions and types, we introduce an ED model which links entities by reasoning over a symbolic knowledge base in a fully differentiable fashion. Our model surpasses state-of-the-art baselines on six well-established ED datasets by 1.3 F1 on average. By allowing access to all KB information, our model is less reliant on popularity-based entity priors, and improves performance on the challenging ShadowLink dataset (which emphasises infrequent and ambiguous entities) by 12.7 F1.
DARE: Data Augmented Relation Extraction with GPT-2
Apr 06, 2020
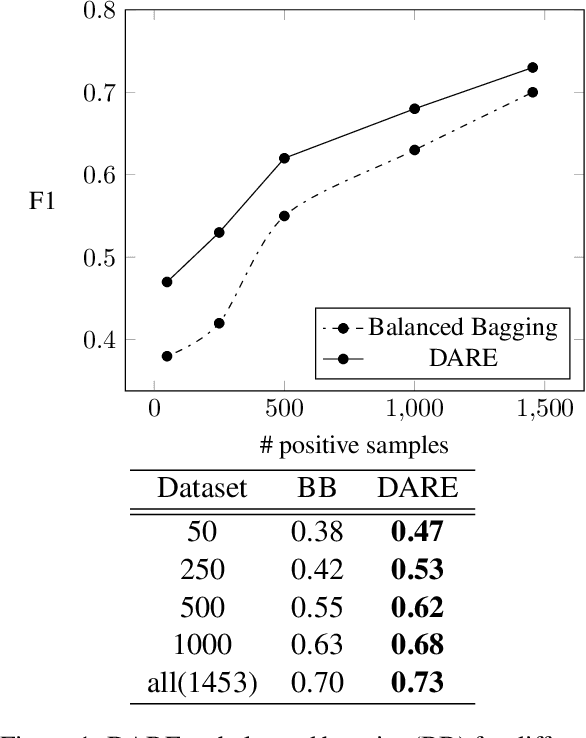

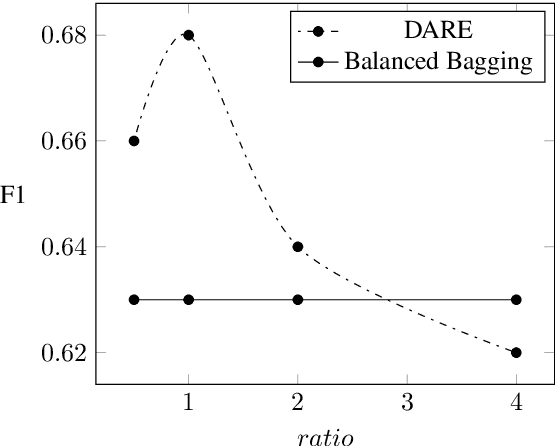
Real-world Relation Extraction (RE) tasks are challenging to deal with, either due to limited training data or class imbalance issues. In this work, we present Data Augmented Relation Extraction(DARE), a simple method to augment training data by properly fine-tuning GPT-2 to generate examples for specific relation types. The generated training data is then used in combination with the gold dataset to train a BERT-based RE classifier. In a series of experiments we show the advantages of our method, which leads in improvements of up to 11 F1 score points against a strong base-line. Also, DARE achieves new state of the art in three widely used biomedical RE datasets surpassing the previous best results by 4.7 F1 points on average.
Reasoning Over Paths via Knowledge Base Completion
Nov 01, 2019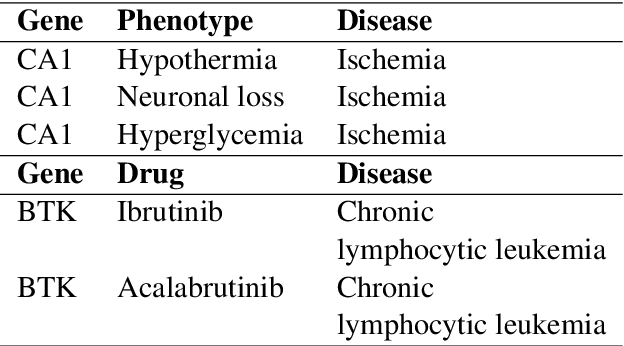
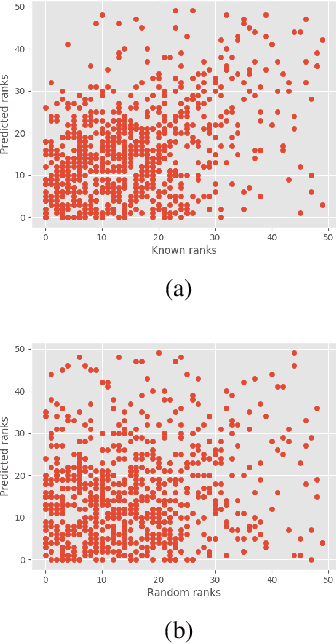
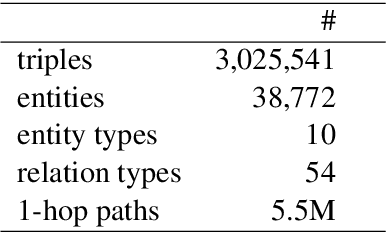

Reasoning over paths in large scale knowledge graphs is an important problem for many applications. In this paper we discuss a simple approach to automatically build and rank paths between a source and target entity pair with learned embeddings using a knowledge base completion model (KBC). We assembled a knowledge graph by mining the available biomedical scientific literature and extracted a set of high frequency paths to use for validation. We demonstrate that our method is able to effectively rank a list of known paths between a pair of entities and also come up with plausible paths that are not present in the knowledge graph. For a given entity pair we are able to reconstruct the highest ranking path 60% of the time within the the top 10 ranked paths and achieve 49% mean average precision. Our approach is compositional since any KBC model that can produce vector representations of entities can be used.
Deep Bidirectional Transformers for Relation Extraction without Supervision
Nov 01, 2019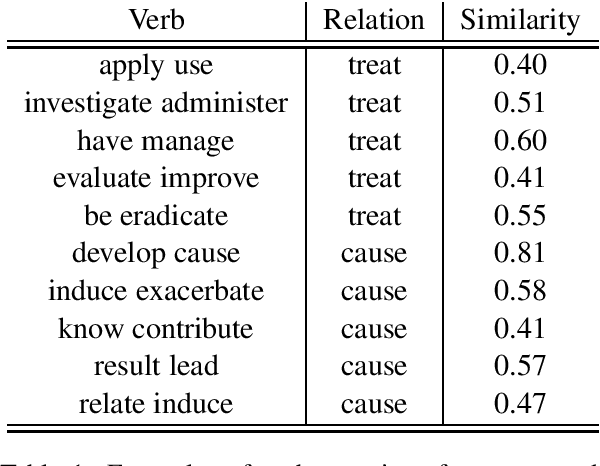
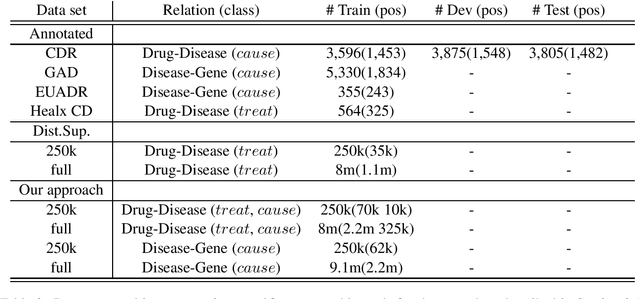
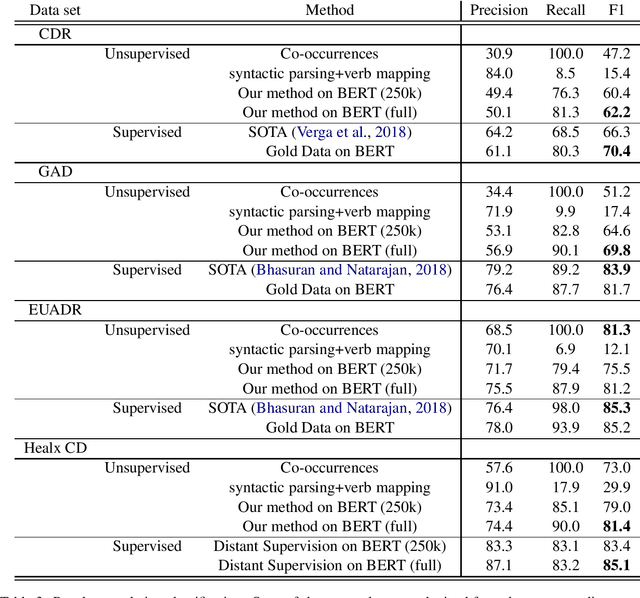
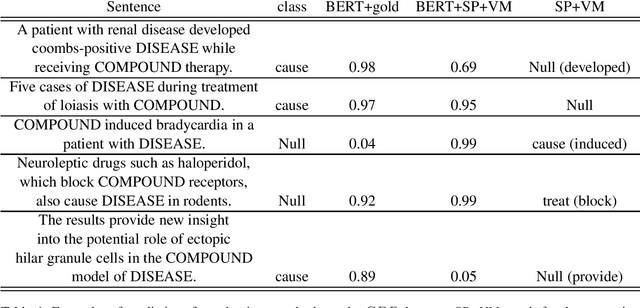
We present a novel framework to deal with relation extraction tasks in cases where there is complete lack of supervision, either in the form of gold annotations, or relations from a knowledge base. Our approach leverages syntactic parsing and pre-trained word embeddings to extract few but precise relations,which are then used to annotate a larger cor-pus, in a manner identical to distant supervision. The resulting data set is employed to fine tune a pre-trained BERT model in order to perform relation extraction. Empirical evaluation on four data sets from the biomedical domain shows that our method significantly outperforms two simple baselines for unsupervised relation extraction and, even if not using any supervision at all, achieves slightly worse results than the state-of-the-art in three out of four data sets. Importantly, we show that it is possible to successfully fine tune a large pre-trained language model with noisy data, as op-posed to previous works that rely on gold data for fine tuning.