 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREXEL: An End-to-end Model for Document-Level Relation Extraction and Entity Linking
Apr 19, 2024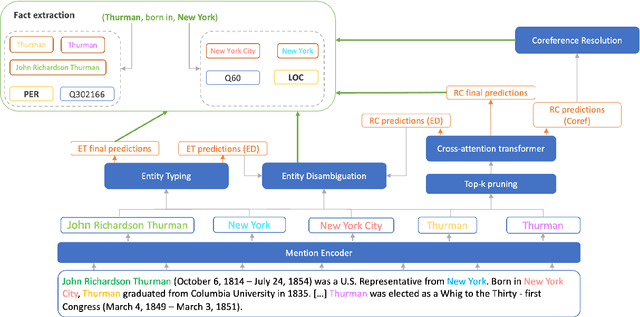
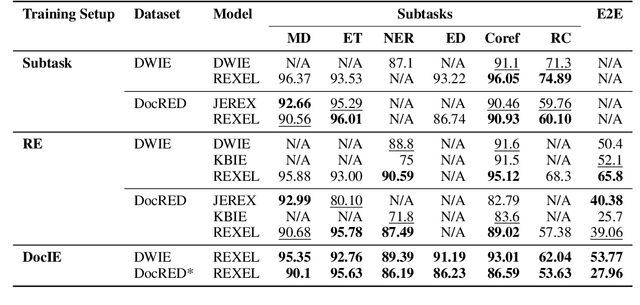
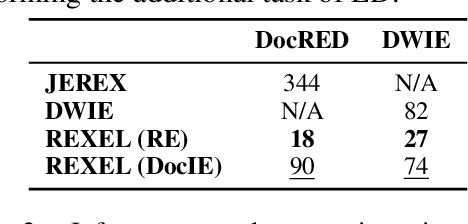
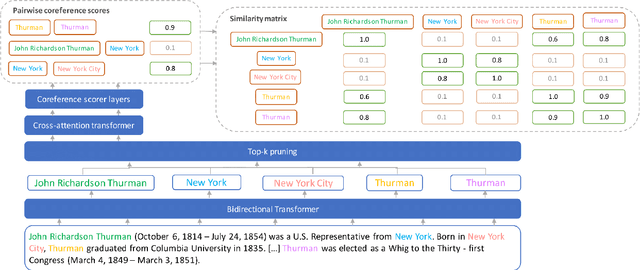
Extracting structured information from unstructured text is critical for many downstream NLP applications and is traditionally achieved by closed information extraction (cIE). However, existing approaches for cIE suffer from two limitations: (i) they are often pipelines which makes them prone to error propagation, and/or (ii) they are restricted to sentence level which prevents them from capturing long-range dependencies and results in expensive inference time. We address these limitations by proposing REXEL, a highly efficient and accurate model for the joint task of document level cIE (DocIE). REXEL performs mention detection, entity typing, entity disambiguation, coreference resolution and document-level relation classification in a single forward pass to yield facts fully linked to a reference knowledge graph. It is on average 11 times faster than competitive existing approaches in a similar setting and performs competitively both when optimised for any of the individual subtasks and a variety of combinations of different joint tasks, surpassing the baselines by an average of more than 6 F1 points. The combination of speed and accuracy makes REXEL an accurate cost-efficient system for extracting structured information at web-scale. We also release an extension of the DocRED dataset to enable benchmarking of future work on DocIE, which is available at https://github.com/amazon-science/e2e-docie.
ReFinED: An Efficient Zero-shot-capable Approach to End-to-End Entity Linking
Jul 08, 2022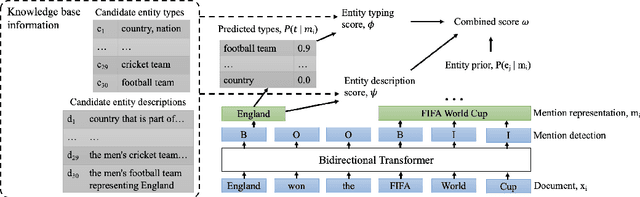
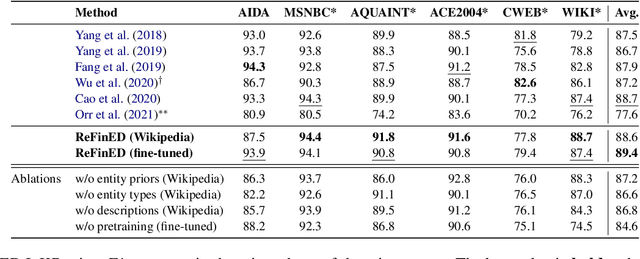
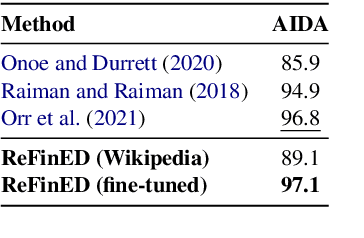
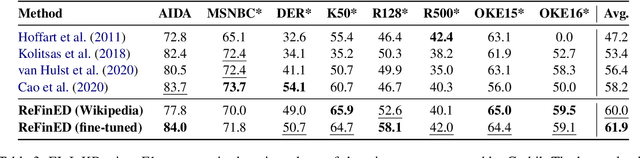
We introduce ReFinED, an efficient end-to-end entity linking model which uses fine-grained entity types and entity descriptions to perform linking. The model performs mention detection, fine-grained entity typing, and entity disambiguation for all mentions within a document in a single forward pass, making it more than 60 times faster than competitive existing approaches. ReFinED also surpasses state-of-the-art performance on standard entity linking datasets by an average of 3.7 F1. The model is capable of generalising to large-scale knowledge bases such as Wikidata (which has 15 times more entities than Wikipedia) and of zero-shot entity linking. The combination of speed, accuracy and scale makes ReFinED an effective and cost-efficient system for extracting entities from web-scale datasets, for which the model has been successfully deployed. Our code and pre-trained models are available at https://github.com/alexa/ReFinED
Improving Entity Disambiguation by Reasoning over a Knowledge Base
Jul 08, 2022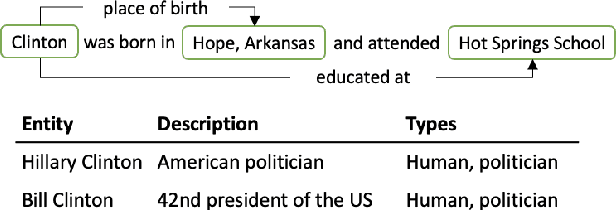
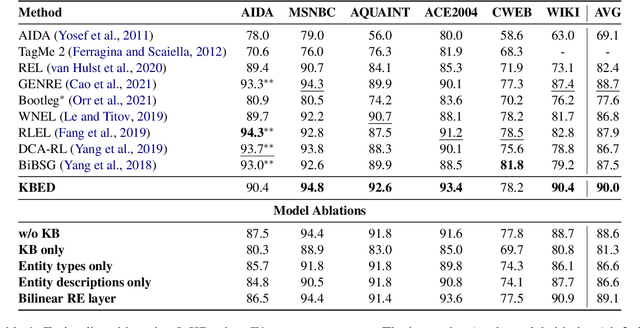
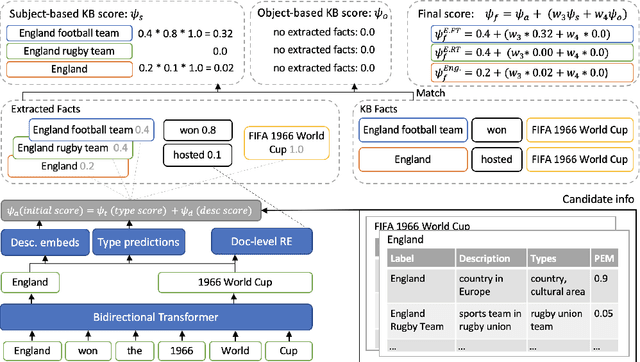
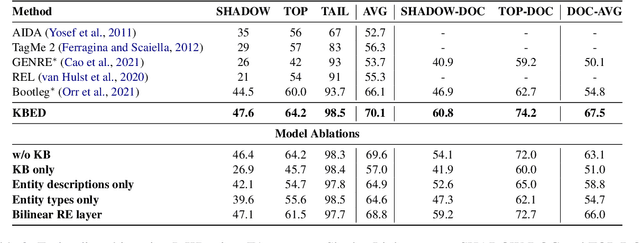
Recent work in entity disambiguation (ED) has typically neglected structured knowledge base (KB) facts, and instead relied on a limited subset of KB information, such as entity descriptions or types. This limits the range of contexts in which entities can be disambiguated. To allow the use of all KB facts, as well as descriptions and types, we introduce an ED model which links entities by reasoning over a symbolic knowledge base in a fully differentiable fashion. Our model surpasses state-of-the-art baselines on six well-established ED datasets by 1.3 F1 on average. By allowing access to all KB information, our model is less reliant on popularity-based entity priors, and improves performance on the challenging ShadowLink dataset (which emphasises infrequent and ambiguous entities) by 12.7 F1.
Measuring Social Bias in Knowledge Graph Embeddings
Dec 05, 2019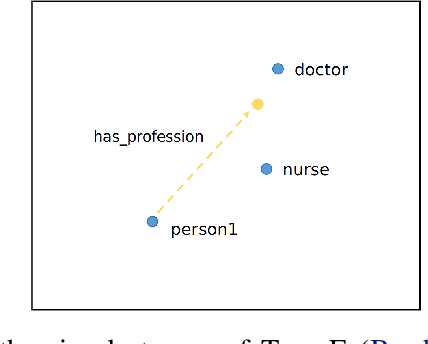
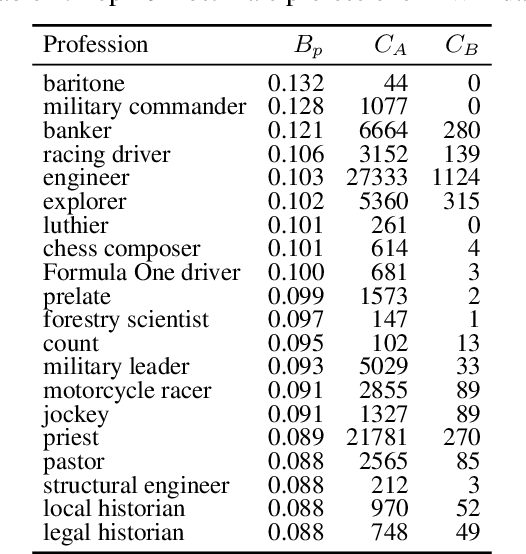
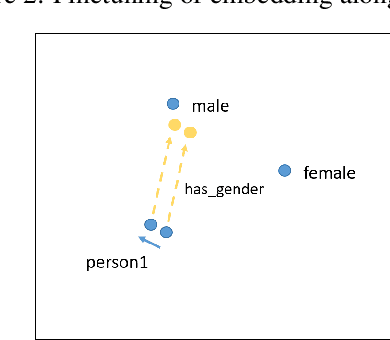
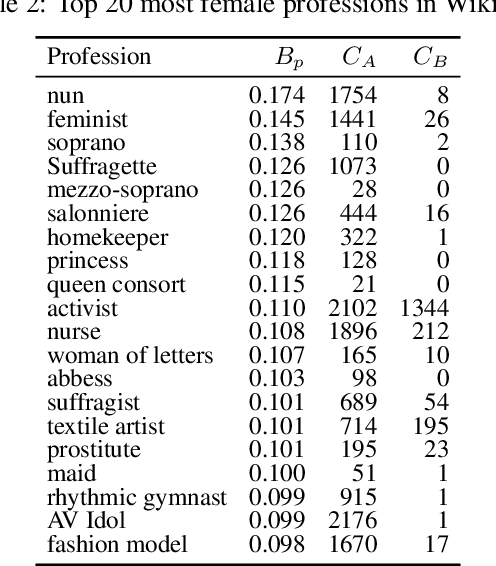
It has recently been shown that word embeddings encode social biases, with a harmful impact on downstream tasks. However, to this point there has been no similar work done in the field of graph embeddings. We present the first study on social bias in knowledge graph embeddings, and propose a new metric suitable for measuring such bias. We conduct experiments on Wikidata and Freebase, and show that, as with word embeddings, harmful social biases related to professions are encoded in the embeddings with respect to gender, religion, ethnicity and nationality. For example, graph embeddings encode the information that men are more likely to be bankers, and women more likely to be homekeepers. As graph embeddings become increasingly utilized, we suggest that it is important the existence of such biases are understood and steps taken to mitigate their impact.
Merge and Label: A novel neural network architecture for nested NER
Jun 30, 2019
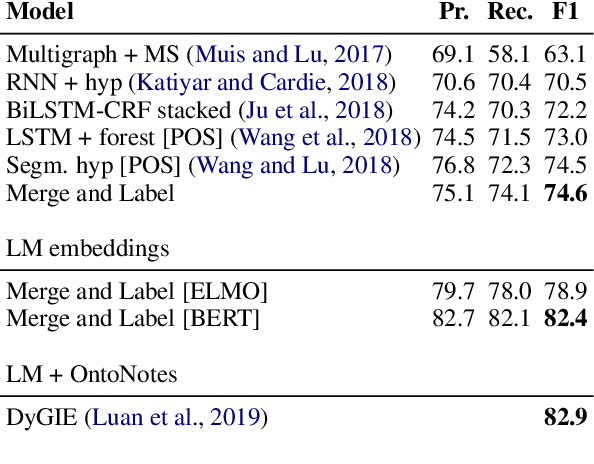

Named entity recognition (NER) is one of the best studied tasks in natural language processing. However, most approaches are not capable of handling nested structures which are common in many applications. In this paper we introduce a novel neural network architecture that first merges tokens and/or entities into entities forming nested structures, and then labels each of them independently. Unlike previous work, our merge and label approach predicts real-valued instead of discrete segmentation structures, which allow it to combine word and nested entity embeddings while maintaining differentiability. %which smoothly groups entities into single vectors across multiple levels. We evaluate our approach using the ACE 2005 Corpus, where it achieves state-of-the-art F1 of 74.6, further improved with contextual embeddings (BERT) to 82.4, an overall improvement of close to 8 F1 points over previous approaches trained on the same data. Additionally we compare it against BiLSTM-CRFs, the dominant approach for flat NER structures, demonstrating that its ability to predict nested structures does not impact performance in simpler cases.