 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositional Description for Numerical Normalization
Aug 22, 2024



We present a Positional Description Scheme (PDS) tailored for digit sequences, integrating placeholder value information for each digit. Given the structural limitations of subword tokenization algorithms, language models encounter critical Text Normalization (TN) challenges when handling numerical tasks. Our schema addresses this challenge through straightforward pre-processing, preserving the model architecture while significantly simplifying number normalization, rendering the problem tractable. This simplifies the task and facilitates more compact production-ready models capable of learning from smaller datasets. Furthermore, our investigations reveal that PDS enhances the arithmetic processing capabilities of language models, resulting in a relative accuracy improvement of 23% to 51% on complex arithmetic tasks. We demonstrate that PDS effectively mitigates fatal numerical normalization errors in neural models, requiring only a modest amount of training data without rule-based Finite State Transducers (FST). We demonstrate that PDS is essential for both the Text-To-Speech and Speech Recognition text processing, enabling effective TN under production constraints.
Improving the quality of neural TTS using long-form content and multi-speaker multi-style modeling
Dec 20, 2022



Neural text-to-speech (TTS) can provide quality close to natural speech if an adequate amount of high-quality speech material is available for training. However, acquiring speech data for TTS training is costly and time-consuming, especially if the goal is to generate different speaking styles. In this work, we show that we can transfer speaking style across speakers and improve the quality of synthetic speech by training a multi-speaker multi-style (MSMS) model with long-form recordings, in addition to regular TTS recordings. In particular, we show that 1) multi-speaker modeling improves the overall TTS quality, 2) the proposed MSMS approach outperforms pre-training and fine-tuning approach when utilizing additional multi-speaker data, and 3) long-form speaking style is highly rated regardless of the target text domain.
Combining speakers of multiple languages to improve quality of neural voices
Aug 17, 2021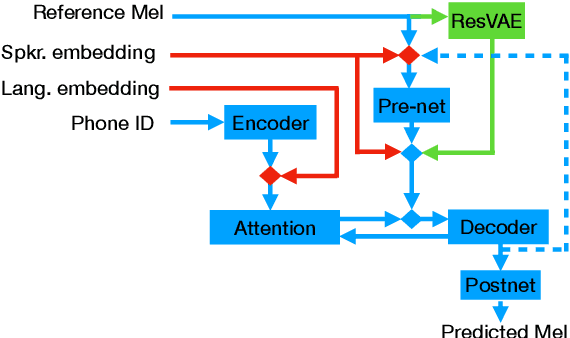

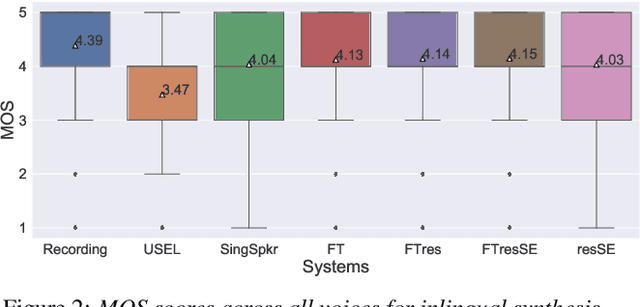
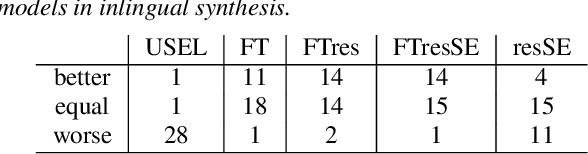
In this work, we explore multiple architectures and training procedures for developing a multi-speaker and multi-lingual neural TTS system with the goals of a) improving the quality when the available data in the target language is limited and b) enabling cross-lingual synthesis. We report results from a large experiment using 30 speakers in 8 different languages across 15 different locales. The system is trained on the same amount of data per speaker. Compared to a single-speaker model, when the suggested system is fine tuned to a speaker, it produces significantly better quality in most of the cases while it only uses less than $40\%$ of the speaker's data used to build the single-speaker model. In cross-lingual synthesis, on average, the generated quality is within $80\%$ of native single-speaker models, in terms of Mean Opinion Score.
Proteno: Text Normalization with Limited Data for Fast Deployment in Text to Speech Systems
Apr 15, 2021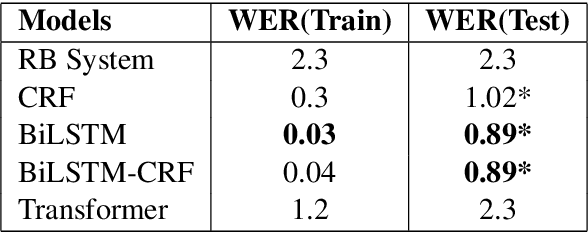
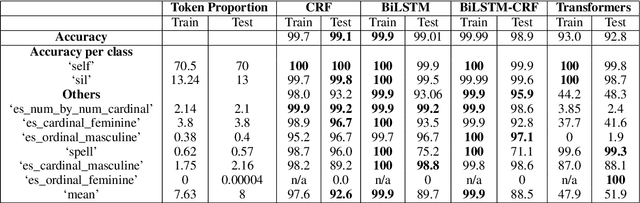


Developing Text Normalization (TN) systems for Text-to-Speech (TTS) on new languages is hard. We propose a novel architecture to facilitate it for multiple languages while using data less than 3% of the size of the data used by the state of the art results on English. We treat TN as a sequence classification problem and propose a granular tokenization mechanism that enables the system to learn majority of the classes and their normalizations from the training data itself. This is further combined with minimal precoded linguistic knowledge for other classes. We publish the first results on TN for TTS in Spanish and Tamil and also demonstrate that the performance of the approach is comparable with the previous work done on English. All annotated datasets used for experimentation will be released at https://github.com/amazon-research/proteno.
Effect of data reduction on sequence-to-sequence neural TTS
Nov 23, 2018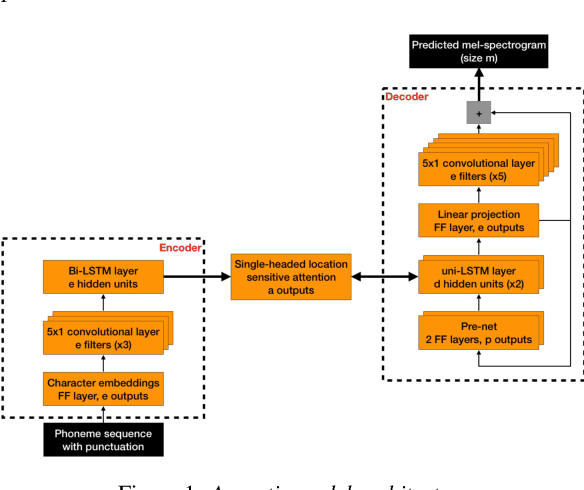
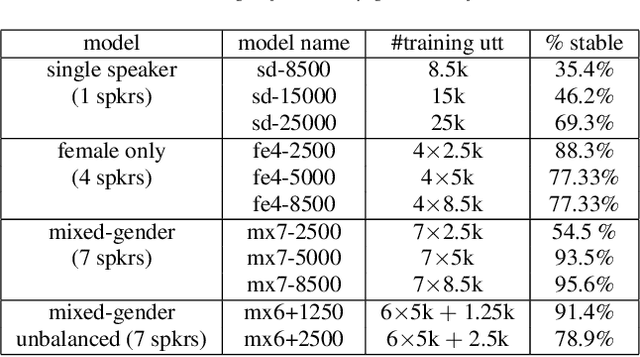
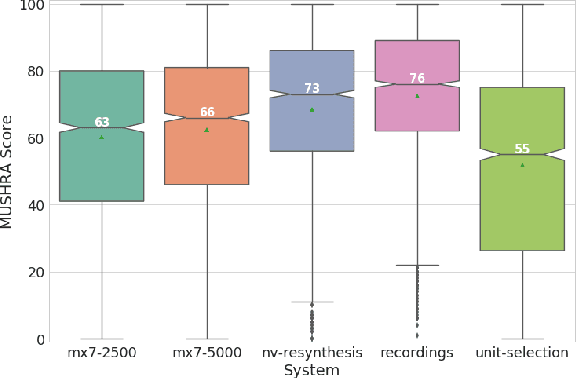
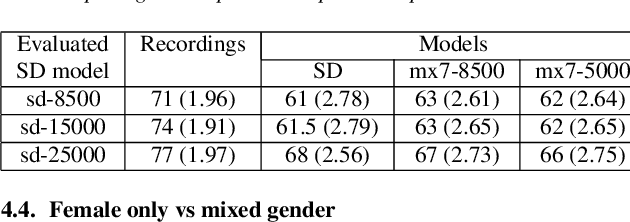
Recent speech synthesis systems based on sampling from autoregressive neural networks models can generate speech almost undistinguishable from human recordings. However, these models require large amounts of data. This paper shows that the lack of data from one speaker can be compensated with data from other speakers. The naturalness of Tacotron2-like models trained on a blend of 5k utterances from 7 speakers is better than that of speaker dependent models trained on 15k utterances, but in terms of stability multi-speaker models are always more stable. We also demonstrate that models mixing only 1250 utterances from a target speaker with 5k utterances from another 6 speakers can produce significantly better quality than state-of-the-art DNN-guided unit selection systems trained on more than 10 times the data from the target speaker.