 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the quality of neural TTS using long-form content and multi-speaker multi-style modeling
Dec 20, 2022



Neural text-to-speech (TTS) can provide quality close to natural speech if an adequate amount of high-quality speech material is available for training. However, acquiring speech data for TTS training is costly and time-consuming, especially if the goal is to generate different speaking styles. In this work, we show that we can transfer speaking style across speakers and improve the quality of synthetic speech by training a multi-speaker multi-style (MSMS) model with long-form recordings, in addition to regular TTS recordings. In particular, we show that 1) multi-speaker modeling improves the overall TTS quality, 2) the proposed MSMS approach outperforms pre-training and fine-tuning approach when utilizing additional multi-speaker data, and 3) long-form speaking style is highly rated regardless of the target text domain.
Vocal effort modeling in neural TTS for improving the intelligibility of synthetic speech in noise
Mar 29, 2022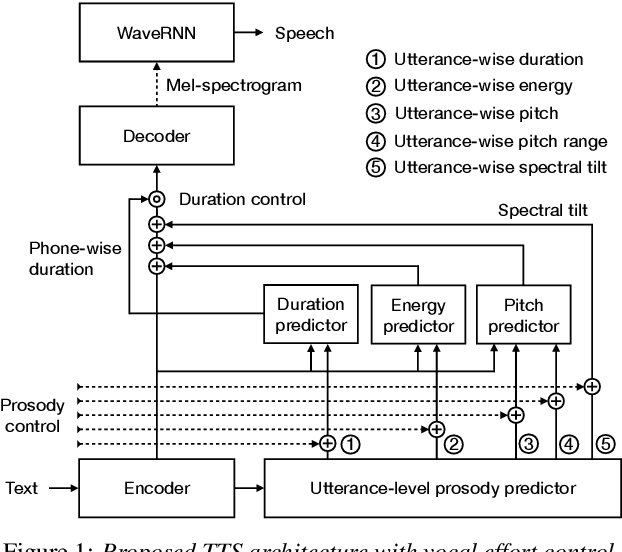
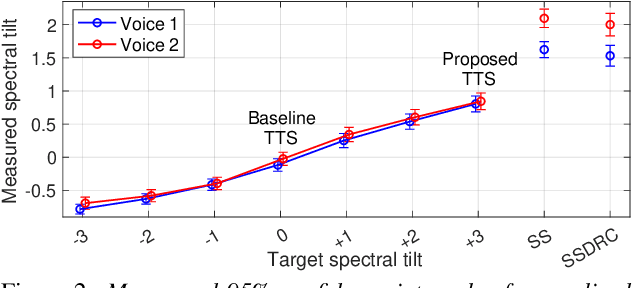
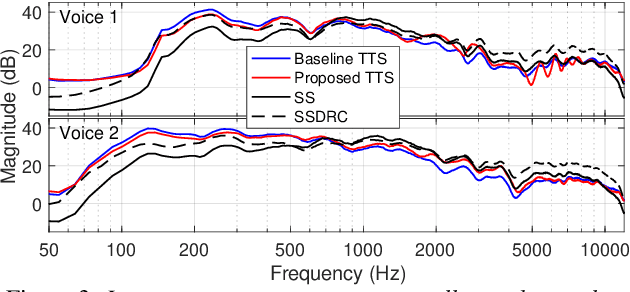
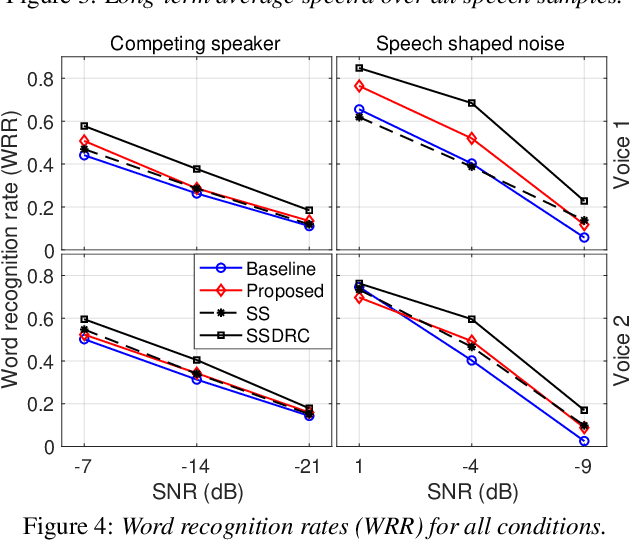
We present a neural text-to-speech (TTS) method that models natural vocal effort variation to improve the intelligibility of synthetic speech in the presence of noise. The method consists of first measuring the spectral tilt of unlabeled conventional speech data, and then conditioning a neural TTS model with normalized spectral tilt among other prosodic factors. Changing the spectral tilt parameter and keeping other prosodic factors unchanged enables effective vocal effort control at synthesis time independent of other prosodic factors. By extrapolation of the spectral tilt values beyond what has been seen in the original data, we can generate speech with high vocal effort levels, thus improving the intelligibility of speech in the presence of masking noise. We evaluate the intelligibility and quality of normal speech and speech with increased vocal effort in the presence of various masking noise conditions, and compare these to well-known speech intelligibility-enhancing algorithms. The evaluations show that the proposed method can improve the intelligibility of synthetic speech with little loss in speech quality.
Emphasis control for parallel neural TTS
Oct 06, 2021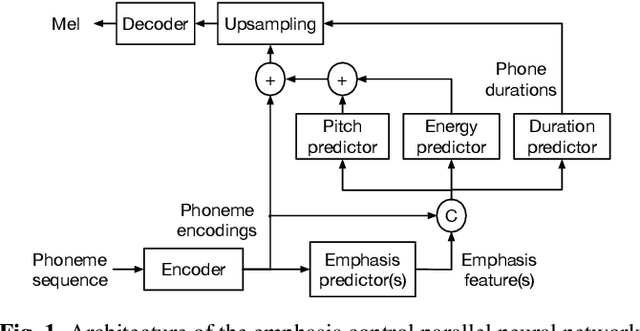
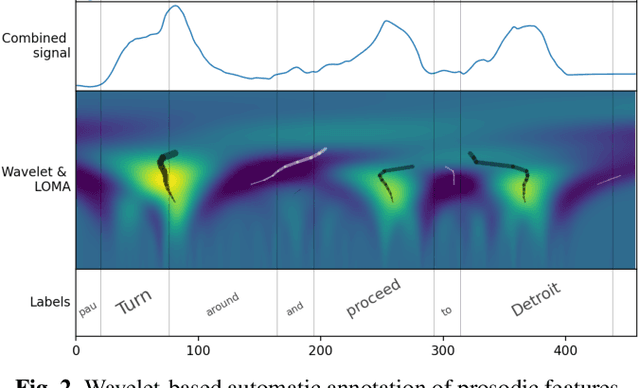
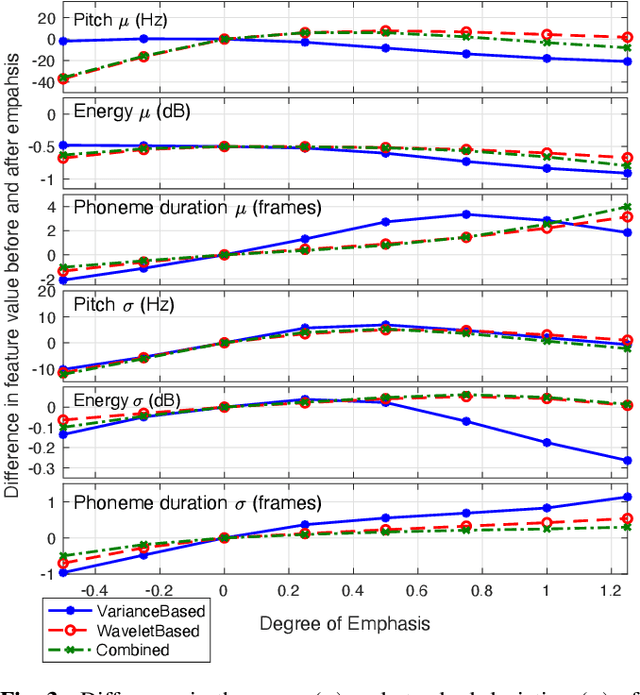
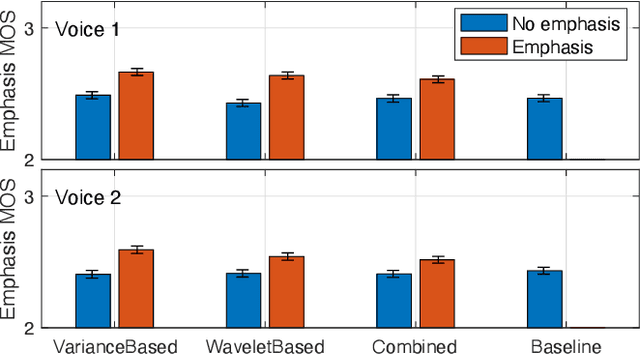
The semantic information conveyed by a speech signal is strongly influenced by local variations in prosody. Recent parallel neural text-to-speech (TTS) synthesis methods are able to generate speech with high fidelity while maintaining high performance. However, these systems often lack simple control over the output prosody, thus restricting the semantic information conveyable for a given text. This paper proposes a hierarchical parallel neural TTS system for prosodic emphasis control by learning a latent space that directly corresponds to a change in emphasis. Three candidate features for the latent space are compared: 1) Variance of pitch and duration within words in a sentence, 2) a wavelet based feature computed from pitch, energy, and duration and 3) a learned combination of the above features. Objective measures reveal that the proposed methods are able to achieve a wide range of emphasis modification, and subjective evaluations on the degree of emphasis and the overall quality indicate that they show promise for real-world applications.
Hierarchical prosody modeling and control in non-autoregressive parallel neural TTS
Oct 06, 2021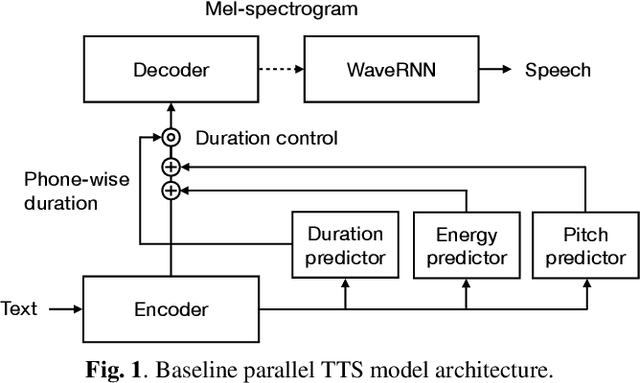
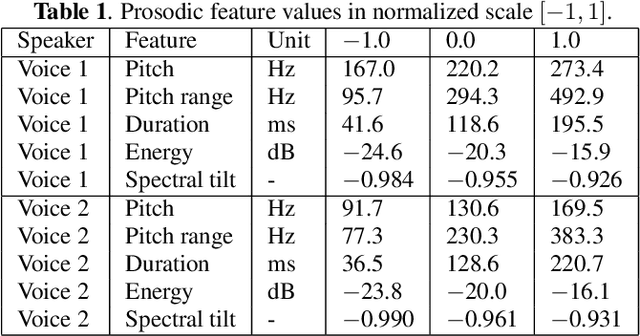
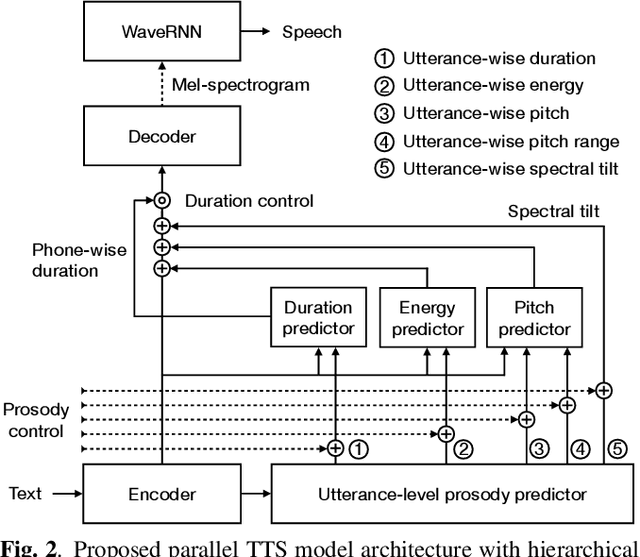
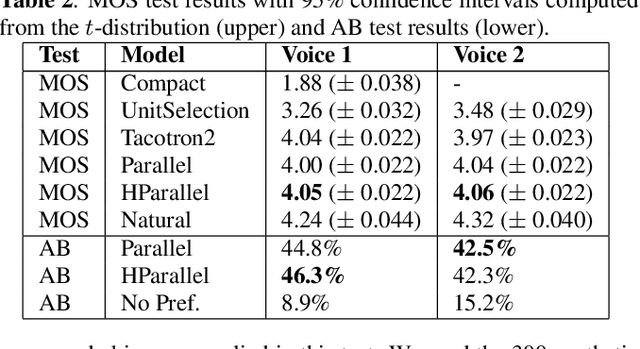
Neural text-to-speech (TTS) synthesis can generate speech that is indistinguishable from natural speech. However, the synthetic speech often represents the average prosodic style of the database instead of having more versatile prosodic variation. Moreover, many models lack the ability to control the output prosody, which does not allow for different styles for the same text input. In this work, we train a non-autoregressive parallel neural TTS model hierarchically conditioned on both coarse and fine-grained acoustic speech features to learn a latent prosody space with intuitive and meaningful dimensions. Experiments show that a non-autoregressive TTS model hierarchically conditioned on utterance-wise pitch, pitch range, duration, energy, and spectral tilt can effectively control each prosodic dimension, generate a wide variety of speaking styles, and provide word-wise emphasis control, while maintaining equal or better quality to the baseline model.
On-device neural speech synthesis
Sep 17, 2021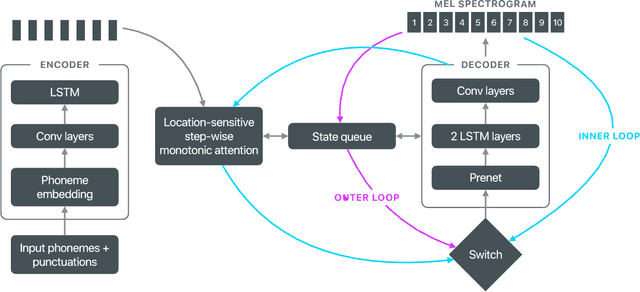

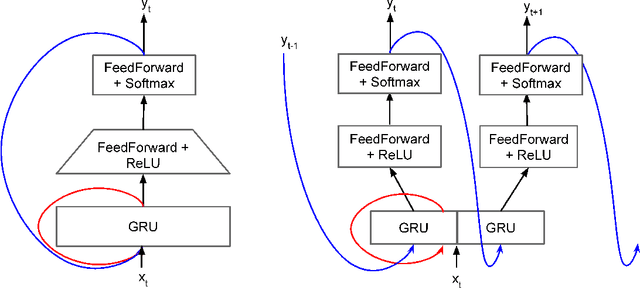
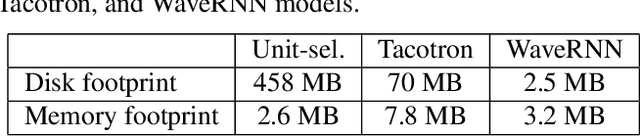
Recent advances in text-to-speech (TTS) synthesis, such as Tacotron and WaveRNN, have made it possible to construct a fully neural network based TTS system, by coupling the two components together. Such a system is conceptually simple as it only takes grapheme or phoneme input, uses Mel-spectrogram as an intermediate feature, and directly generates speech samples. The system achieves quality equal or close to natural speech. However, the high computational cost of the system and issues with robustness have limited their usage in real-world speech synthesis applications and products. In this paper, we present key modeling improvements and optimization strategies that enable deploying these models, not only on GPU servers, but also on mobile devices. The proposed system can generate high-quality 24 kHz speech at 5x faster than real time on server and 3x faster than real time on mobile devices.
Whispered and Lombard Neural Speech Synthesis
Jan 13, 2021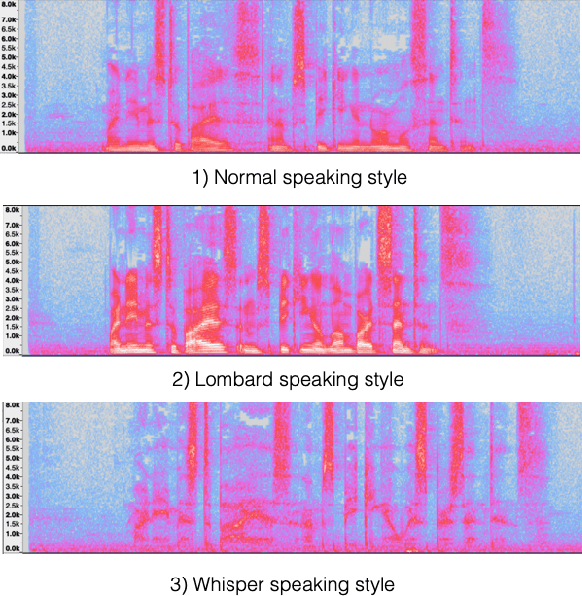

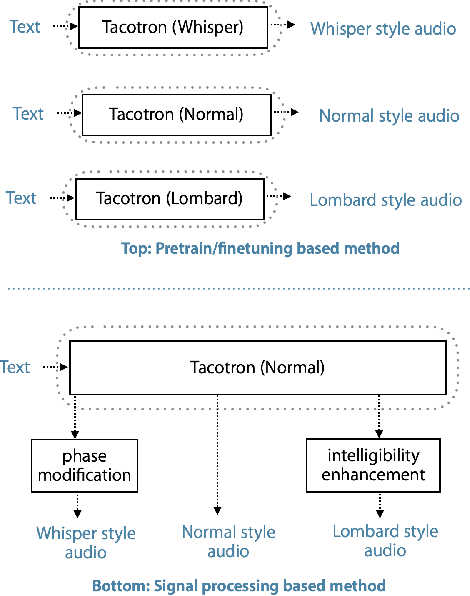
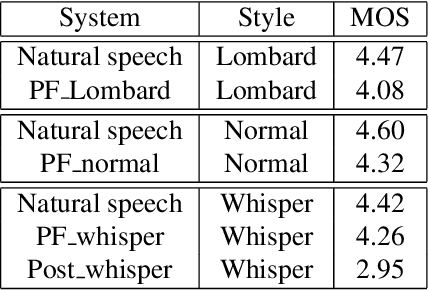
It is desirable for a text-to-speech system to take into account the environment where synthetic speech is presented, and provide appropriate context-dependent output to the user. In this paper, we present and compare various approaches for generating different speaking styles, namely, normal, Lombard, and whisper speech, using only limited data. The following systems are proposed and assessed: 1) Pre-training and fine-tuning a model for each style. 2) Lombard and whisper speech conversion through a signal processing based approach. 3) Multi-style generation using a single model based on a speaker verification model. Our mean opinion score and AB preference listening tests show that 1) we can generate high quality speech through the pre-training/fine-tuning approach for all speaking styles. 2) Although our speaker verification (SV) model is not explicitly trained to discriminate different speaking styles, and no Lombard and whisper voice is used for pre-training this system, the SV model can be used as a style encoder for generating different style embeddings as input for the Tacotron system. We also show that the resulting synthetic Lombard speech has a significant positive impact on intelligibility gain.
Controllable neural text-to-speech synthesis using intuitive prosodic features
Sep 14, 2020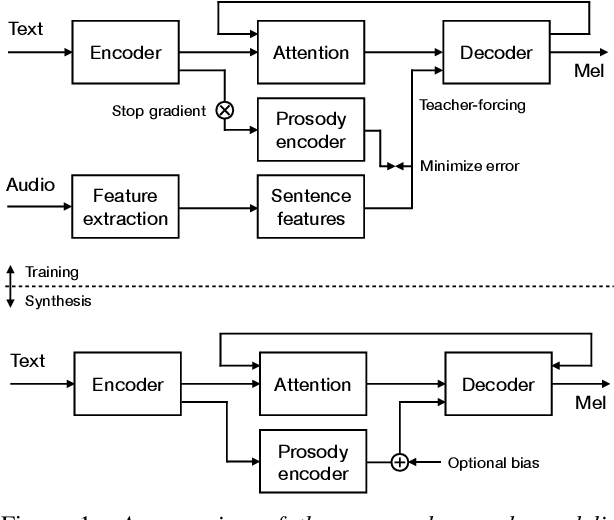
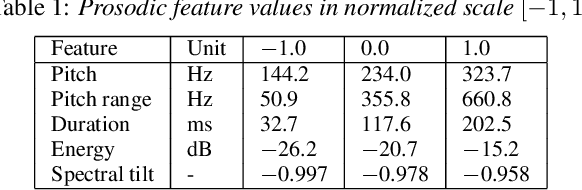
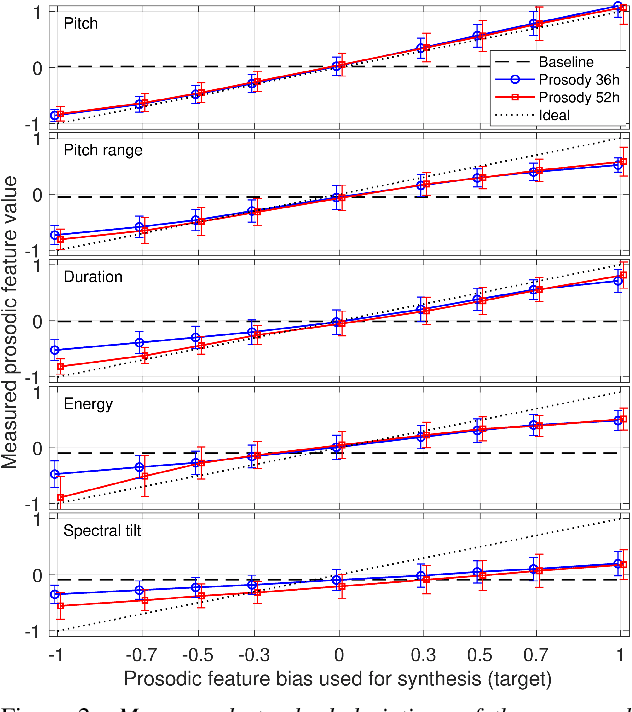
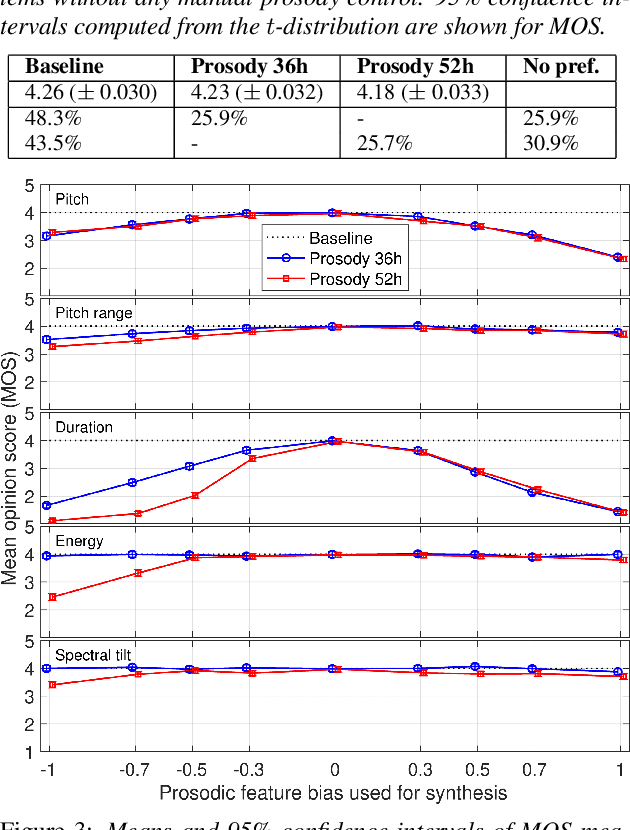
Modern neural text-to-speech (TTS) synthesis can generate speech that is indistinguishable from natural speech. However, the prosody of generated utterances often represents the average prosodic style of the database instead of having wide prosodic variation. Moreover, the generated prosody is solely defined by the input text, which does not allow for different styles for the same sentence. In this work, we train a sequence-to-sequence neural network conditioned on acoustic speech features to learn a latent prosody space with intuitive and meaningful dimensions. Experiments show that a model conditioned on sentence-wise pitch, pitch range, phone duration, energy, and spectral tilt can effectively control each prosodic dimension and generate a wide variety of speaking styles, while maintaining similar mean opinion score (4.23) to our Tacotron baseline (4.26).
Parametric Representation for Singing Voice Synthesis: a Comparative Evaluation
Jun 07, 2020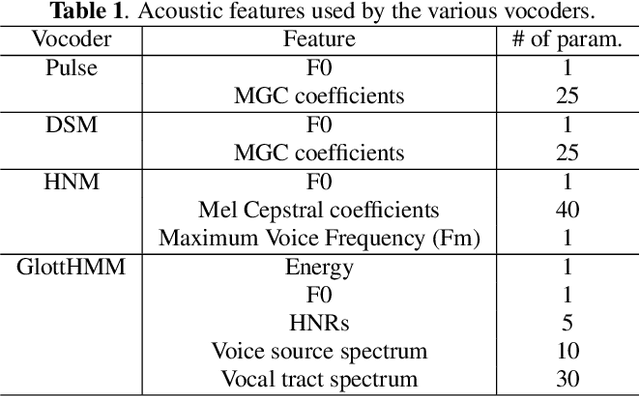
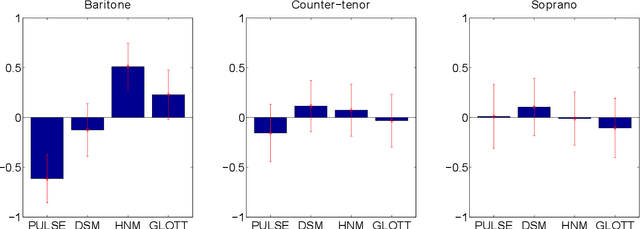
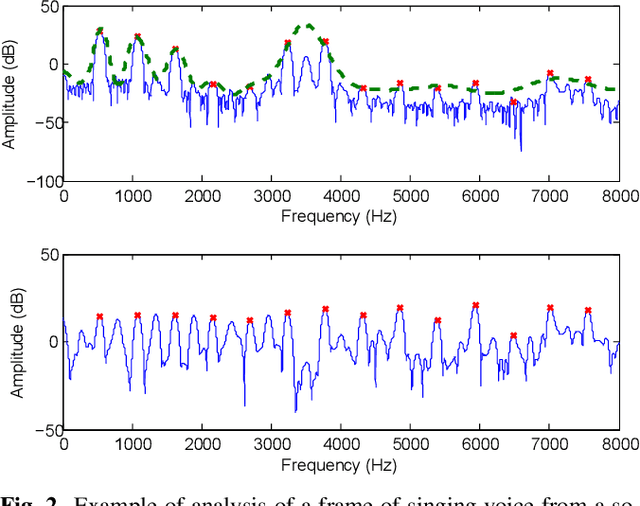
Various parametric representations have been proposed to model the speech signal. While the performance of such vocoders is well-known in the context of speech processing, their extrapolation to singing voice synthesis might not be straightforward. The goal of this paper is twofold. First, a comparative subjective evaluation is performed across four existing techniques suitable for statistical parametric synthesis: traditional pulse vocoder, Deterministic plus Stochastic Model, Harmonic plus Noise Model and GlottHMM. The behavior of these techniques as a function of the singer type (baritone, counter-tenor and soprano) is studied. Secondly, the artifacts occurring in high-pitched voices are discussed and possible approaches to overcome them are suggested.