 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParametric Representation for Singing Voice Synthesis: a Comparative Evaluation
Paper and Code
Jun 07, 2020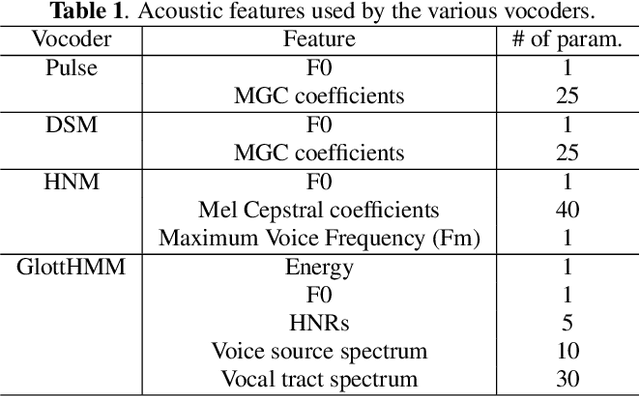
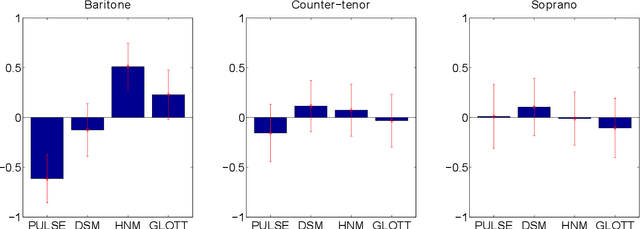
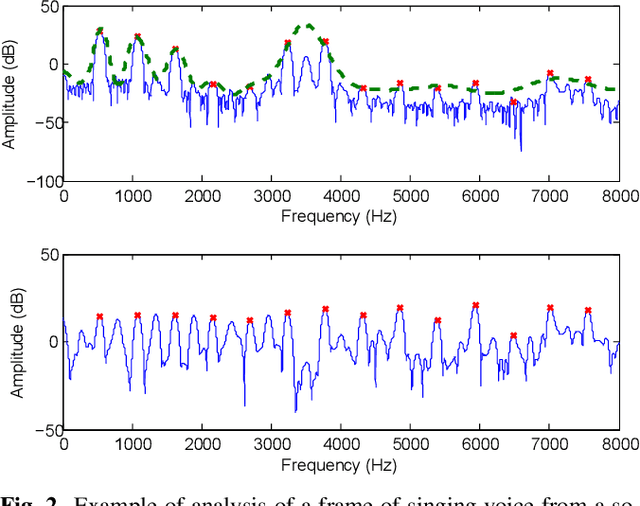
Various parametric representations have been proposed to model the speech signal. While the performance of such vocoders is well-known in the context of speech processing, their extrapolation to singing voice synthesis might not be straightforward. The goal of this paper is twofold. First, a comparative subjective evaluation is performed across four existing techniques suitable for statistical parametric synthesis: traditional pulse vocoder, Deterministic plus Stochastic Model, Harmonic plus Noise Model and GlottHMM. The behavior of these techniques as a function of the singer type (baritone, counter-tenor and soprano) is studied. Secondly, the artifacts occurring in high-pitched voices are discussed and possible approaches to overcome them are suggested.