 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-device neural speech synthesis
Sep 17, 2021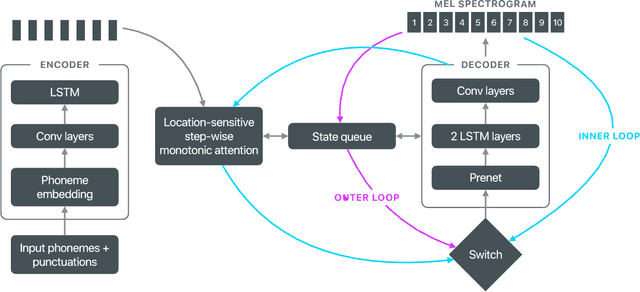

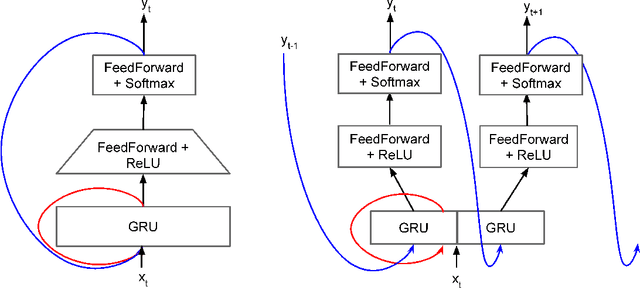
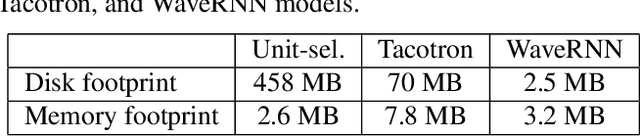
Recent advances in text-to-speech (TTS) synthesis, such as Tacotron and WaveRNN, have made it possible to construct a fully neural network based TTS system, by coupling the two components together. Such a system is conceptually simple as it only takes grapheme or phoneme input, uses Mel-spectrogram as an intermediate feature, and directly generates speech samples. The system achieves quality equal or close to natural speech. However, the high computational cost of the system and issues with robustness have limited their usage in real-world speech synthesis applications and products. In this paper, we present key modeling improvements and optimization strategies that enable deploying these models, not only on GPU servers, but also on mobile devices. The proposed system can generate high-quality 24 kHz speech at 5x faster than real time on server and 3x faster than real time on mobile devices.
Statistical Parametric Speech Synthesis Using Bottleneck Representation From Sequence Auto-encoder
Jun 19, 2016
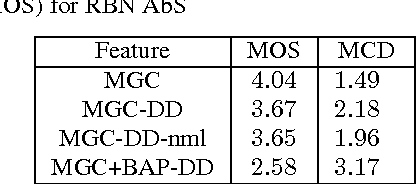
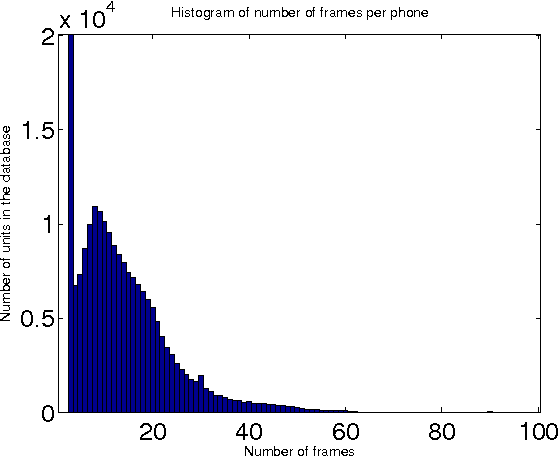
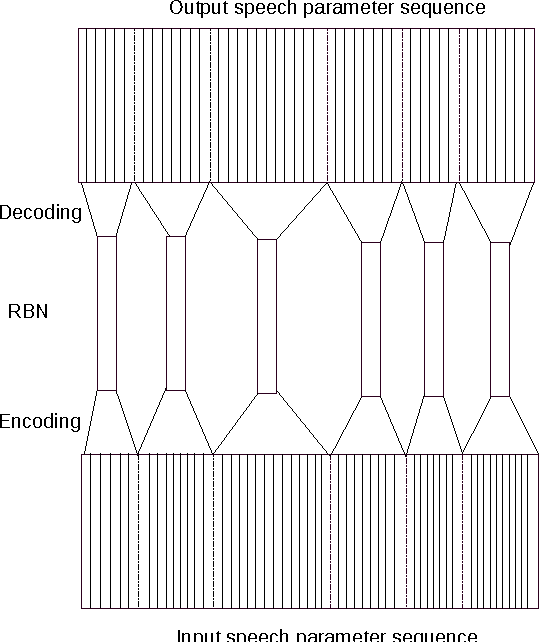
In this paper, we describe a statistical parametric speech synthesis approach with unit-level acoustic representation. In conventional deep neural network based speech synthesis, the input text features are repeated for the entire duration of phoneme for mapping text and speech parameters. This mapping is learnt at the frame-level which is the de-facto acoustic representation. However much of this computational requirement can be drastically reduced if every unit can be represented with a fixed-dimensional representation. Using recurrent neural network based auto-encoder, we show that it is indeed possible to map units of varying duration to a single vector. We then use this acoustic representation at unit-level to synthesize speech using deep neural network based statistical parametric speech synthesis technique. Results show that the proposed approach is able to synthesize at the same quality as the conventional frame based approach at a highly reduced computational cost.
Significance of Maximum Spectral Amplitude in Sub-bands for Spectral Envelope Estimation and Its Application to Statistical Parametric Speech Synthesis
Aug 03, 2015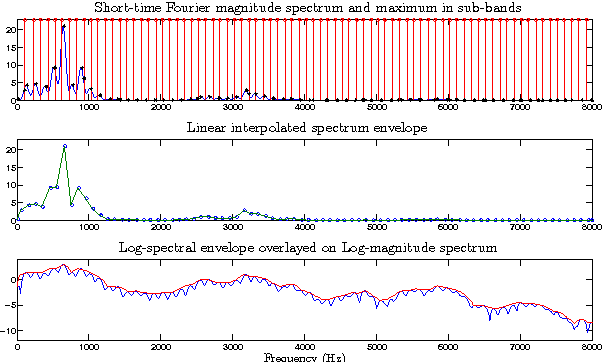
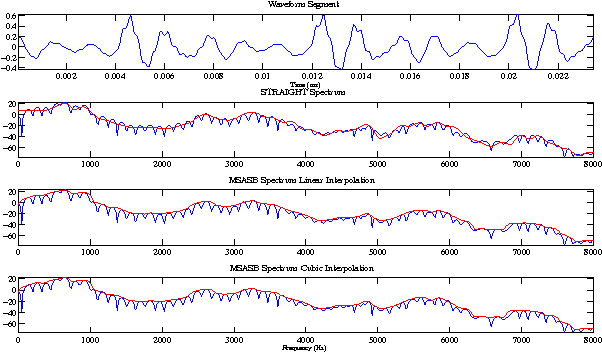
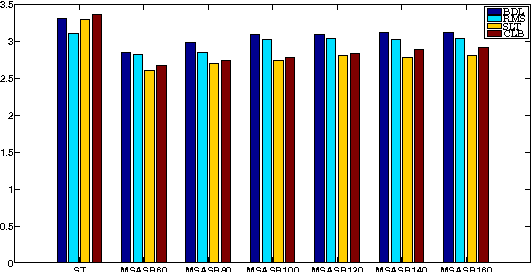
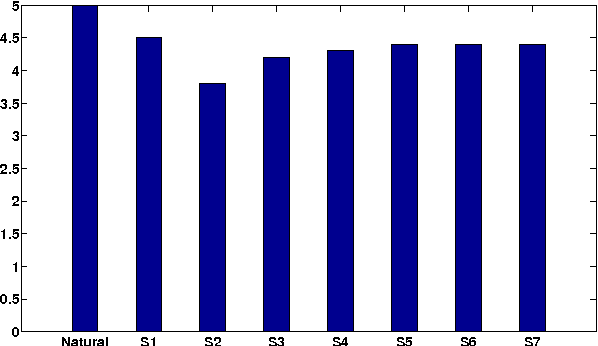
In this paper we propose a technique for spectral envelope estimation using maximum values in the sub-bands of Fourier magnitude spectrum (MSASB). Most other methods in the literature parametrize spectral envelope in cepstral domain such as Mel-generalized cepstrum etc. Such cepstral domain representations, although compact, are not readily interpretable. This difficulty is overcome by our method which parametrizes in the spectral domain itself. In our experiments, spectral envelope estimated using MSASB method was incorporated in the STRAIGHT vocoder. Both objective and subjective results of analysis-by-synthesis indicate that the proposed method is comparable to STRAIGHT. We also evaluate the effectiveness of the proposed parametrization in a statistical parametric speech synthesis framework using deep neural networks.