 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn investigation of speaker independent phrase break models in End-to-End TTS systems
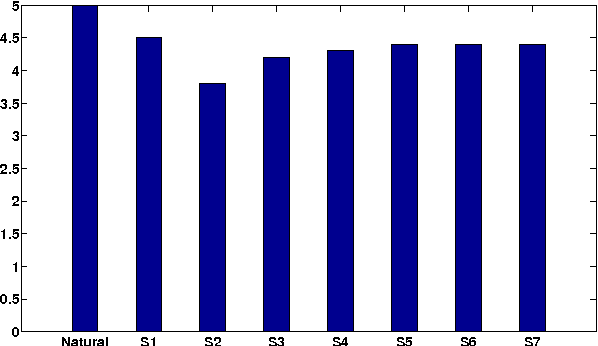
Apr 21, 2023This paper presents our work on phrase break prediction in the context of end-to-end TTS systems, motivated by the following questions: (i) Is there any utility in incorporating an explicit phrasing model in an end-to-end TTS system?, and (ii) How do you evaluate the effectiveness of a phrasing model in an end-to-end TTS system? In particular, the utility and effectiveness of phrase break prediction models are evaluated in in the context of childrens story synthesis, using listener comprehension. We show by means of perceptual listening evaluations that there is a clear preference for stories synthesized after predicting the location of phrase breaks using a trained phrasing model, over stories directly synthesized without predicting the location of phrase breaks.
Significance of Maximum Spectral Amplitude in Sub-bands for Spectral Envelope Estimation and Its Application to Statistical Parametric Speech Synthesis
Aug 03, 2015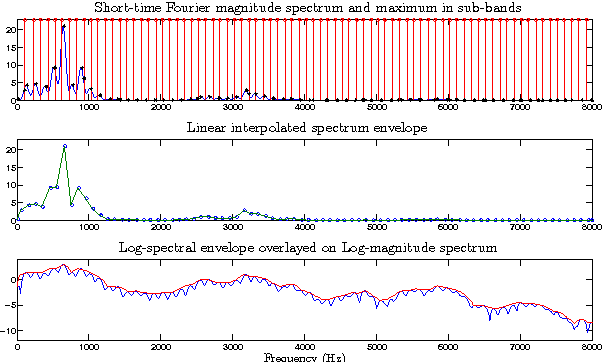
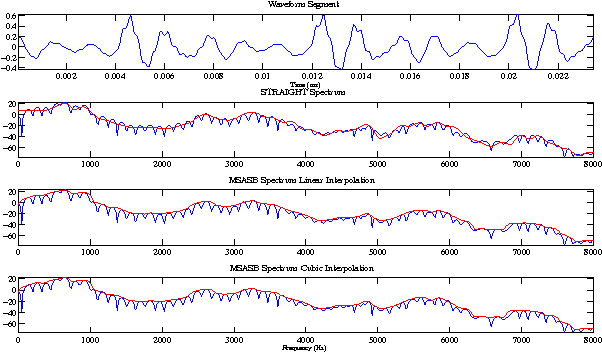
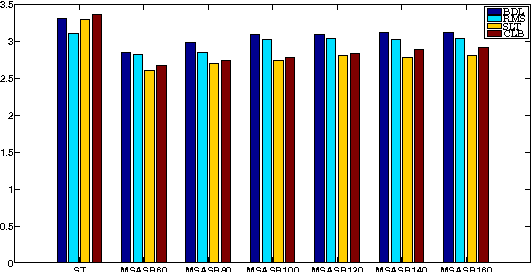
In this paper we propose a technique for spectral envelope estimation using maximum values in the sub-bands of Fourier magnitude spectrum (MSASB). Most other methods in the literature parametrize spectral envelope in cepstral domain such as Mel-generalized cepstrum etc. Such cepstral domain representations, although compact, are not readily interpretable. This difficulty is overcome by our method which parametrizes in the spectral domain itself. In our experiments, spectral envelope estimated using MSASB method was incorporated in the STRAIGHT vocoder. Both objective and subjective results of analysis-by-synthesis indicate that the proposed method is comparable to STRAIGHT. We also evaluate the effectiveness of the proposed parametrization in a statistical parametric speech synthesis framework using deep neural networks.