 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Frame Decoding for Ultra-Low-Bitrate Image Compression with Video Diffusion Priors
Mar 16, 2026We present a novel paradigm for ultra-low-bitrate image compression (ULB-IC) that exploits the ``temporal'' evolution in generative image compression. Specifically, we define an explicit intermediate state during decoding: a compact anchor frame, which preserves the scene geometry and semantic layout while discarding high-frequency details. We then reinterpret generative decoding as a virtual temporal transition from this anchor to the final reconstructed image.To model this progression, we leverage a pretrained video diffusion model (VDM) as temporal priors: the anchor frame serves as the initial frame and the original image as the target frame, transforming the decoding process into a next-frame prediction task.In contrast to image diffusion-based ULB-IC models, our decoding proceeds from a visible, semantically faithful anchor, which improves both fidelity and realism for perceptual image compression. Extensive experiments demonstrate that our method achieves superior objective and subjective performance. On the CLIC2020 test set, our method achieves over \textbf{50\% bitrate savings} across LPIPS, DISTS, FID, and KID compared to DiffC, while also delivering a significant decoding speedup of up to $\times$5. Code will be released later.
YUNet: Improved YOLOv11 Network for Skyline Detection
Feb 18, 2025Skyline detection plays an important role in geolocalizaion, flight control, visual navigation, port security, etc. The appearance of the sky and non-sky areas are variable, because of different weather or illumination environment, which brings challenges to skyline detection. In this research, we proposed the YUNet algorithm, which improved the YOLOv11 architecture to segment the sky region and extract the skyline in complicated and variable circumstances. To improve the ability of multi-scale and large range contextual feature fusion, the YOLOv11 architecture is extended as an UNet-like architecture, consisting of an encoder, neck and decoder submodule. The encoder extracts the multi-scale features from the given images. The neck makes fusion of these multi-scale features. The decoder applies the fused features to complete the prediction rebuilding. To validate the proposed approach, the YUNet was tested on Skyfinder and CH1 datasets for segmentation and skyline detection respectively. Our test shows that the IoU of YUnet segmentation can reach 0.9858, and the average error of YUnet skyline detection is just 1.36 pixels. The implementation is published at https://github.com/kuazhangxiaoai/SkylineDet-YOLOv11Seg.git.
Controllable Distortion-Perception Tradeoff Through Latent Diffusion for Neural Image Compression
Dec 16, 2024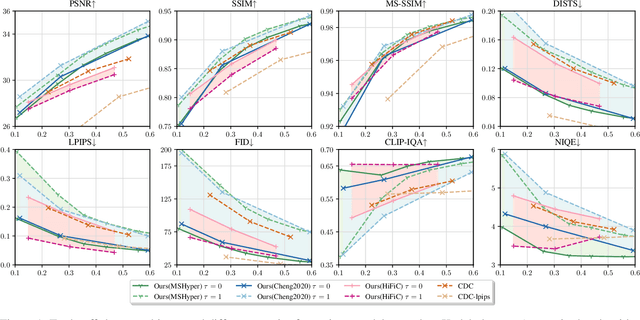

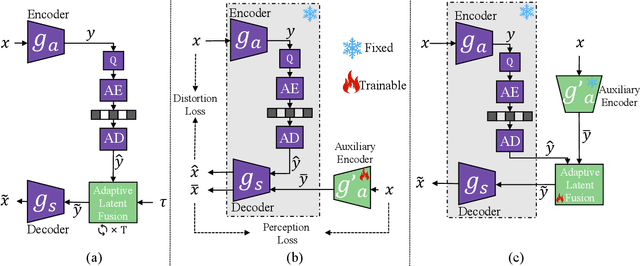
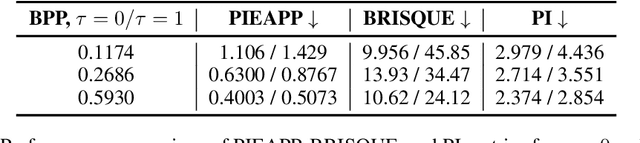
Neural image compression often faces a challenging trade-off among rate, distortion and perception. While most existing methods typically focus on either achieving high pixel-level fidelity or optimizing for perceptual metrics, we propose a novel approach that simultaneously addresses both aspects for a fixed neural image codec. Specifically, we introduce a plug-and-play module at the decoder side that leverages a latent diffusion process to transform the decoded features, enhancing either low distortion or high perceptual quality without altering the original image compression codec. Our approach facilitates fusion of original and transformed features without additional training, enabling users to flexibly adjust the balance between distortion and perception during inference. Extensive experimental results demonstrate that our method significantly enhances the pretrained codecs with a wide, adjustable distortion-perception range while maintaining their original compression capabilities. For instance, we can achieve more than 150% improvement in LPIPS-BDRate without sacrificing more than 1 dB in PSNR.
Vocal effort modeling in neural TTS for improving the intelligibility of synthetic speech in noise
Mar 29, 2022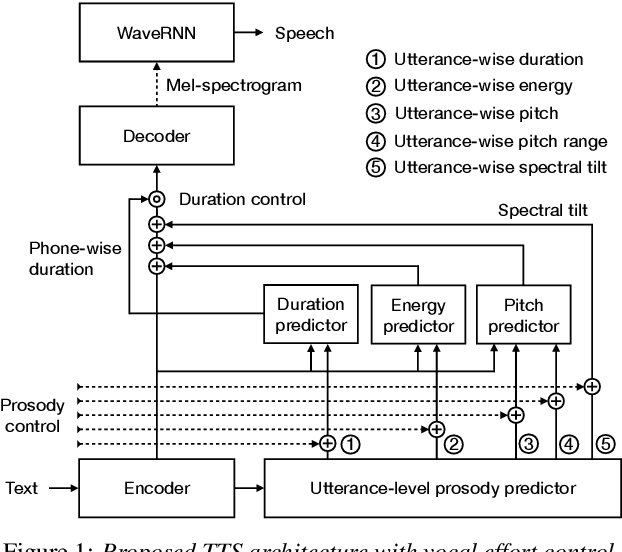
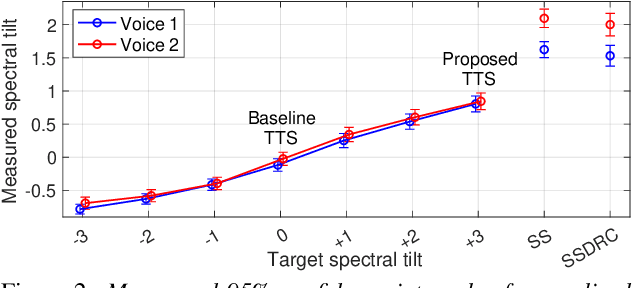
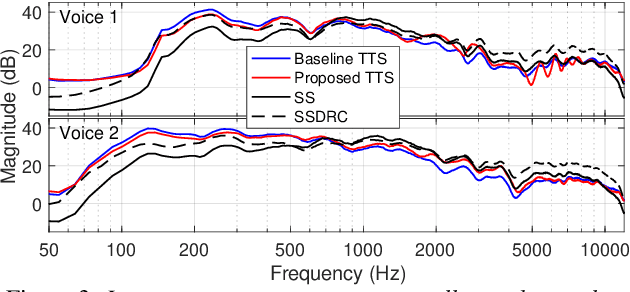
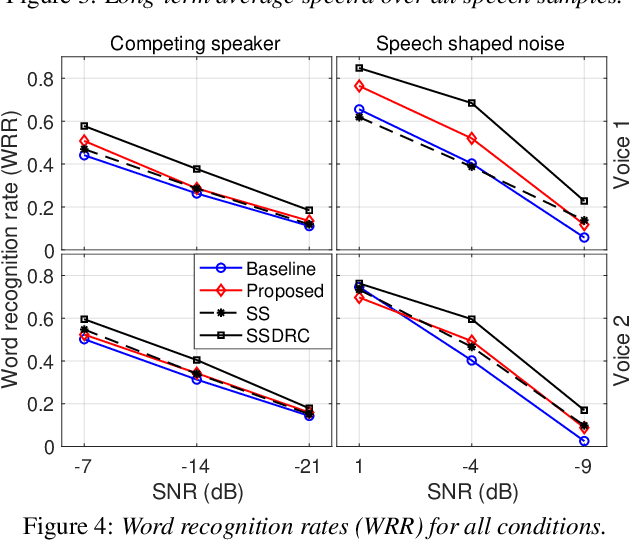
We present a neural text-to-speech (TTS) method that models natural vocal effort variation to improve the intelligibility of synthetic speech in the presence of noise. The method consists of first measuring the spectral tilt of unlabeled conventional speech data, and then conditioning a neural TTS model with normalized spectral tilt among other prosodic factors. Changing the spectral tilt parameter and keeping other prosodic factors unchanged enables effective vocal effort control at synthesis time independent of other prosodic factors. By extrapolation of the spectral tilt values beyond what has been seen in the original data, we can generate speech with high vocal effort levels, thus improving the intelligibility of speech in the presence of masking noise. We evaluate the intelligibility and quality of normal speech and speech with increased vocal effort in the presence of various masking noise conditions, and compare these to well-known speech intelligibility-enhancing algorithms. The evaluations show that the proposed method can improve the intelligibility of synthetic speech with little loss in speech quality.
Emphasis control for parallel neural TTS
Oct 06, 2021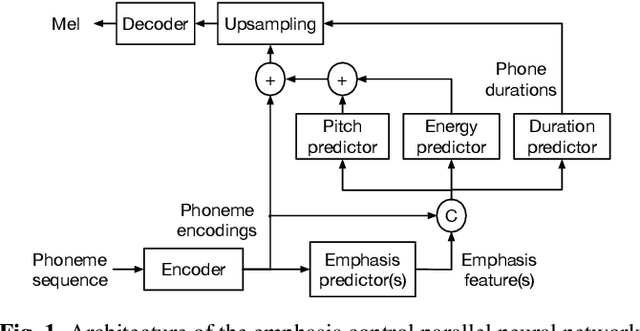
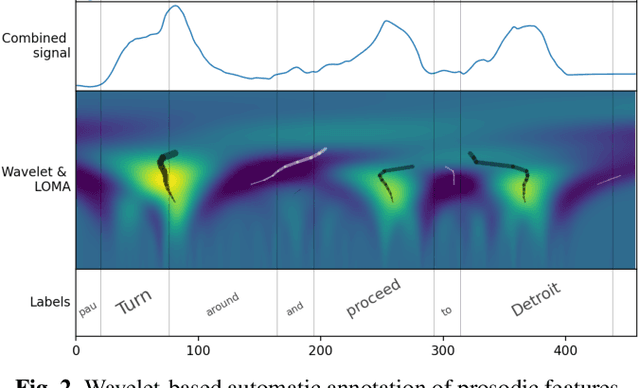
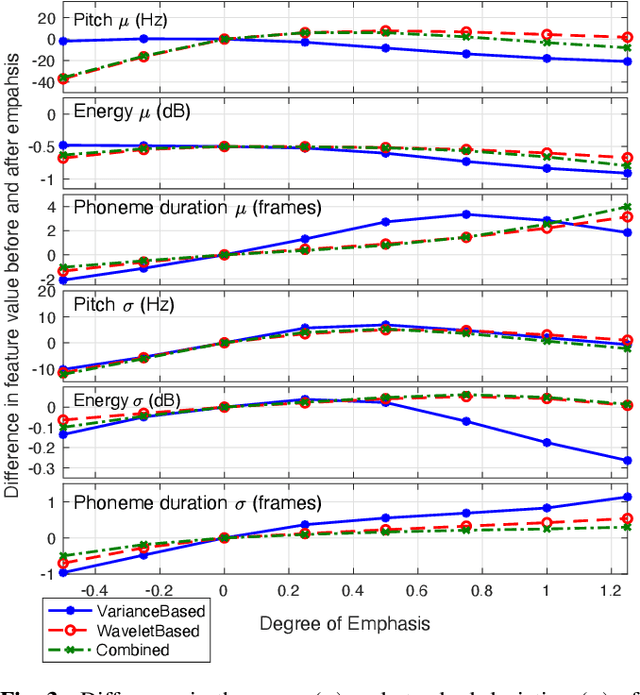
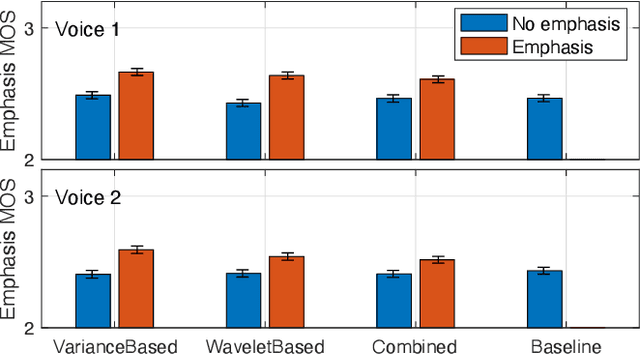
The semantic information conveyed by a speech signal is strongly influenced by local variations in prosody. Recent parallel neural text-to-speech (TTS) synthesis methods are able to generate speech with high fidelity while maintaining high performance. However, these systems often lack simple control over the output prosody, thus restricting the semantic information conveyable for a given text. This paper proposes a hierarchical parallel neural TTS system for prosodic emphasis control by learning a latent space that directly corresponds to a change in emphasis. Three candidate features for the latent space are compared: 1) Variance of pitch and duration within words in a sentence, 2) a wavelet based feature computed from pitch, energy, and duration and 3) a learned combination of the above features. Objective measures reveal that the proposed methods are able to achieve a wide range of emphasis modification, and subjective evaluations on the degree of emphasis and the overall quality indicate that they show promise for real-world applications.
Hierarchical prosody modeling and control in non-autoregressive parallel neural TTS
Oct 06, 2021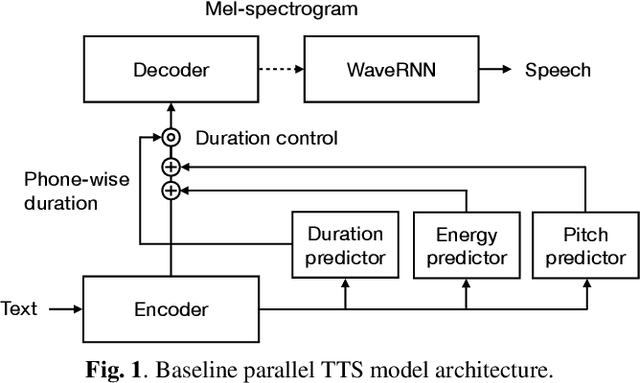
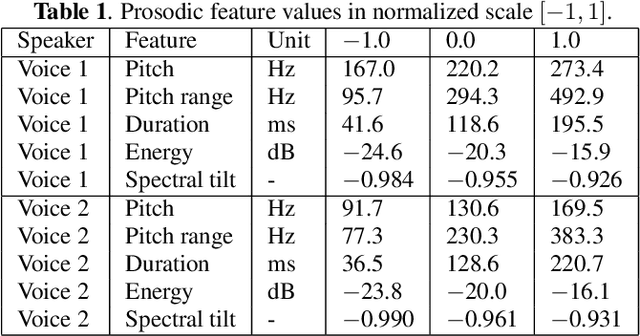
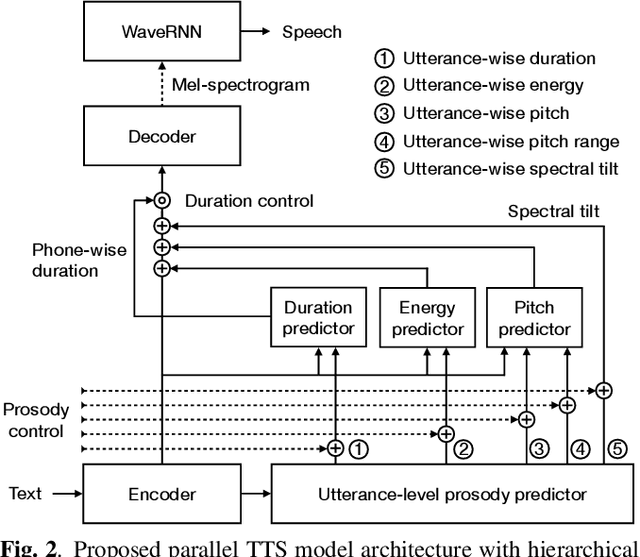
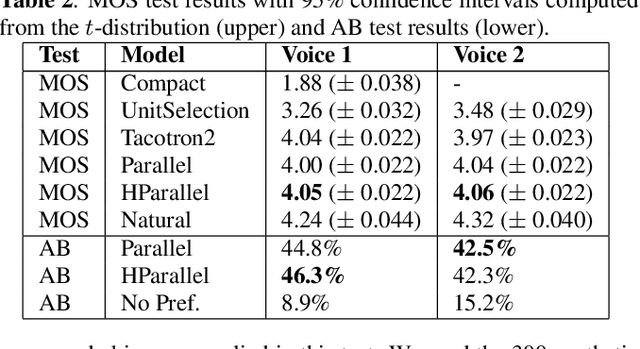
Neural text-to-speech (TTS) synthesis can generate speech that is indistinguishable from natural speech. However, the synthetic speech often represents the average prosodic style of the database instead of having more versatile prosodic variation. Moreover, many models lack the ability to control the output prosody, which does not allow for different styles for the same text input. In this work, we train a non-autoregressive parallel neural TTS model hierarchically conditioned on both coarse and fine-grained acoustic speech features to learn a latent prosody space with intuitive and meaningful dimensions. Experiments show that a non-autoregressive TTS model hierarchically conditioned on utterance-wise pitch, pitch range, duration, energy, and spectral tilt can effectively control each prosodic dimension, generate a wide variety of speaking styles, and provide word-wise emphasis control, while maintaining equal or better quality to the baseline model.
On-device neural speech synthesis
Sep 17, 2021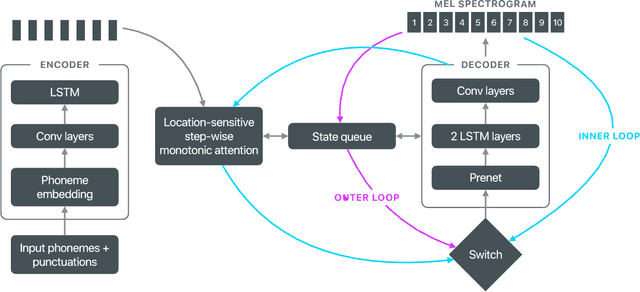

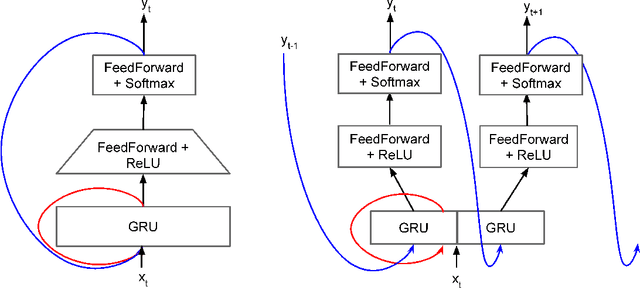
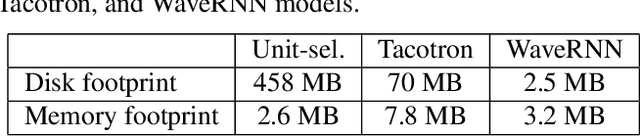
Recent advances in text-to-speech (TTS) synthesis, such as Tacotron and WaveRNN, have made it possible to construct a fully neural network based TTS system, by coupling the two components together. Such a system is conceptually simple as it only takes grapheme or phoneme input, uses Mel-spectrogram as an intermediate feature, and directly generates speech samples. The system achieves quality equal or close to natural speech. However, the high computational cost of the system and issues with robustness have limited their usage in real-world speech synthesis applications and products. In this paper, we present key modeling improvements and optimization strategies that enable deploying these models, not only on GPU servers, but also on mobile devices. The proposed system can generate high-quality 24 kHz speech at 5x faster than real time on server and 3x faster than real time on mobile devices.