 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmphasis control for parallel neural TTS
Oct 06, 2021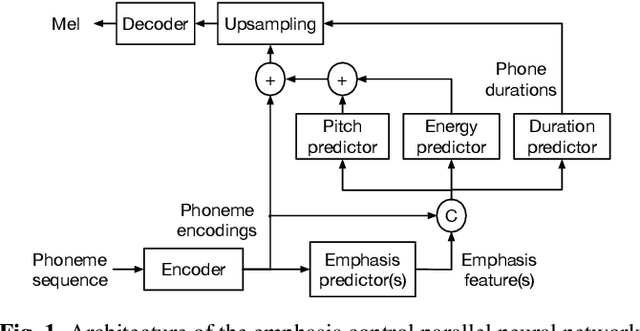
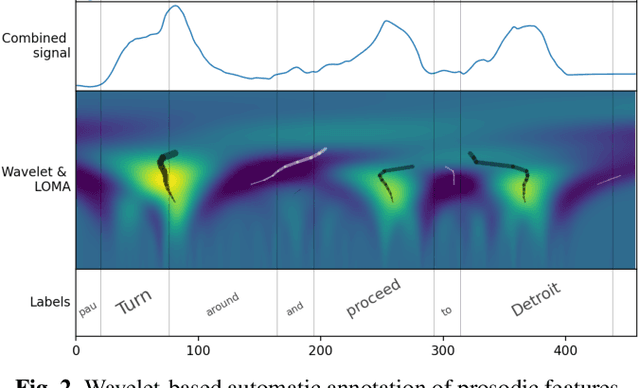
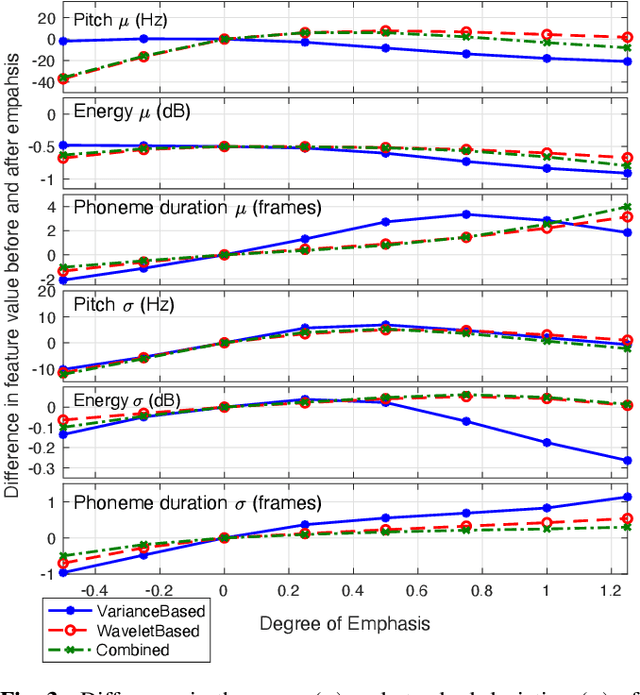
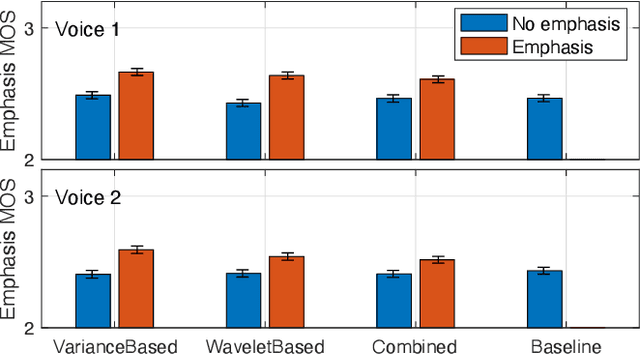
The semantic information conveyed by a speech signal is strongly influenced by local variations in prosody. Recent parallel neural text-to-speech (TTS) synthesis methods are able to generate speech with high fidelity while maintaining high performance. However, these systems often lack simple control over the output prosody, thus restricting the semantic information conveyable for a given text. This paper proposes a hierarchical parallel neural TTS system for prosodic emphasis control by learning a latent space that directly corresponds to a change in emphasis. Three candidate features for the latent space are compared: 1) Variance of pitch and duration within words in a sentence, 2) a wavelet based feature computed from pitch, energy, and duration and 3) a learned combination of the above features. Objective measures reveal that the proposed methods are able to achieve a wide range of emphasis modification, and subjective evaluations on the degree of emphasis and the overall quality indicate that they show promise for real-world applications.
Controllable neural text-to-speech synthesis using intuitive prosodic features
Sep 14, 2020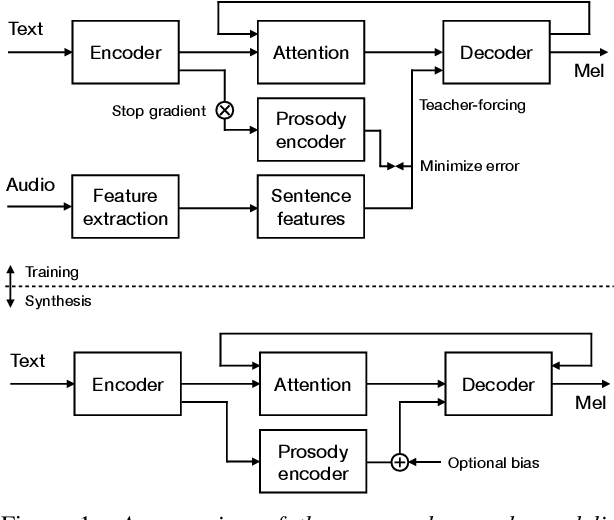
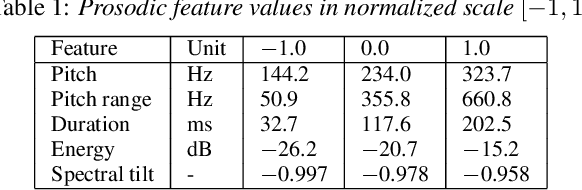
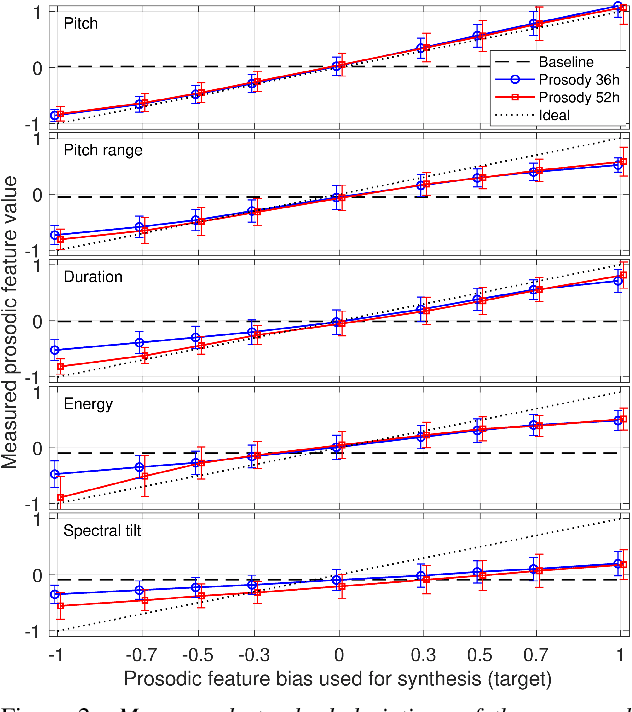
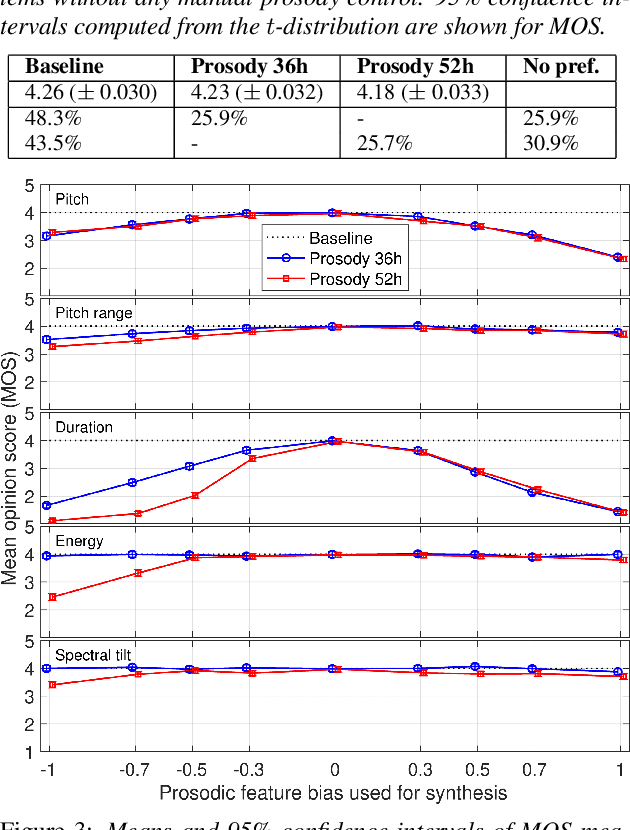
Modern neural text-to-speech (TTS) synthesis can generate speech that is indistinguishable from natural speech. However, the prosody of generated utterances often represents the average prosodic style of the database instead of having wide prosodic variation. Moreover, the generated prosody is solely defined by the input text, which does not allow for different styles for the same sentence. In this work, we train a sequence-to-sequence neural network conditioned on acoustic speech features to learn a latent prosody space with intuitive and meaningful dimensions. Experiments show that a model conditioned on sentence-wise pitch, pitch range, phone duration, energy, and spectral tilt can effectively control each prosodic dimension and generate a wide variety of speaking styles, while maintaining similar mean opinion score (4.23) to our Tacotron baseline (4.26).