 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-device neural speech synthesis
Sep 17, 2021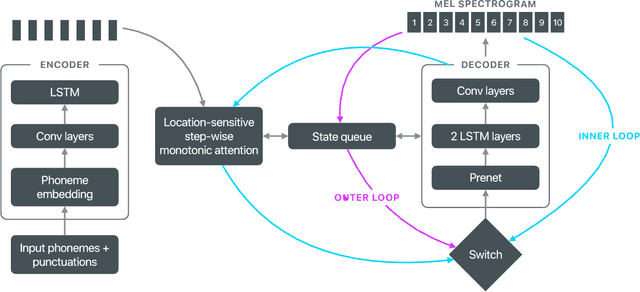

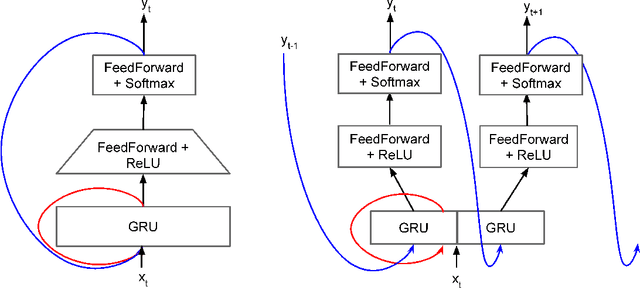
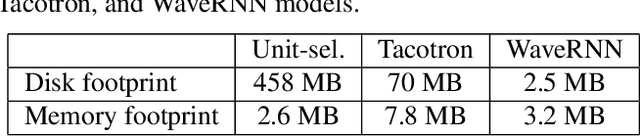
Recent advances in text-to-speech (TTS) synthesis, such as Tacotron and WaveRNN, have made it possible to construct a fully neural network based TTS system, by coupling the two components together. Such a system is conceptually simple as it only takes grapheme or phoneme input, uses Mel-spectrogram as an intermediate feature, and directly generates speech samples. The system achieves quality equal or close to natural speech. However, the high computational cost of the system and issues with robustness have limited their usage in real-world speech synthesis applications and products. In this paper, we present key modeling improvements and optimization strategies that enable deploying these models, not only on GPU servers, but also on mobile devices. The proposed system can generate high-quality 24 kHz speech at 5x faster than real time on server and 3x faster than real time on mobile devices.
Controllable neural text-to-speech synthesis using intuitive prosodic features
Sep 14, 2020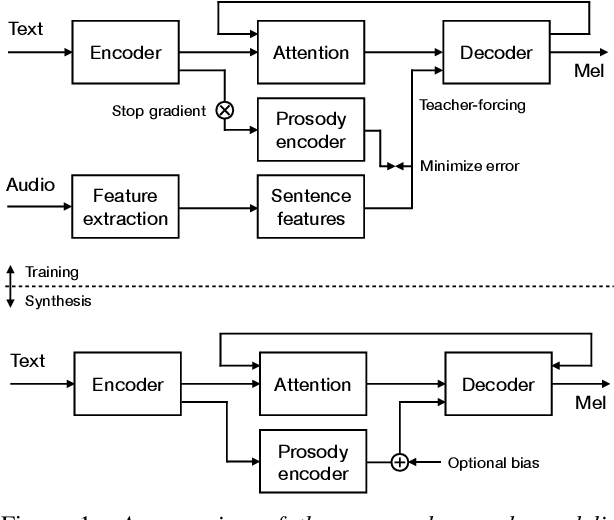
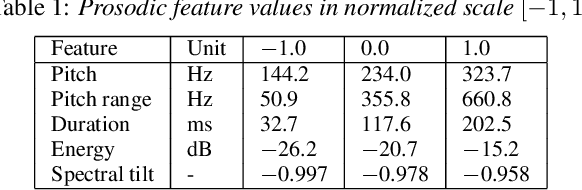
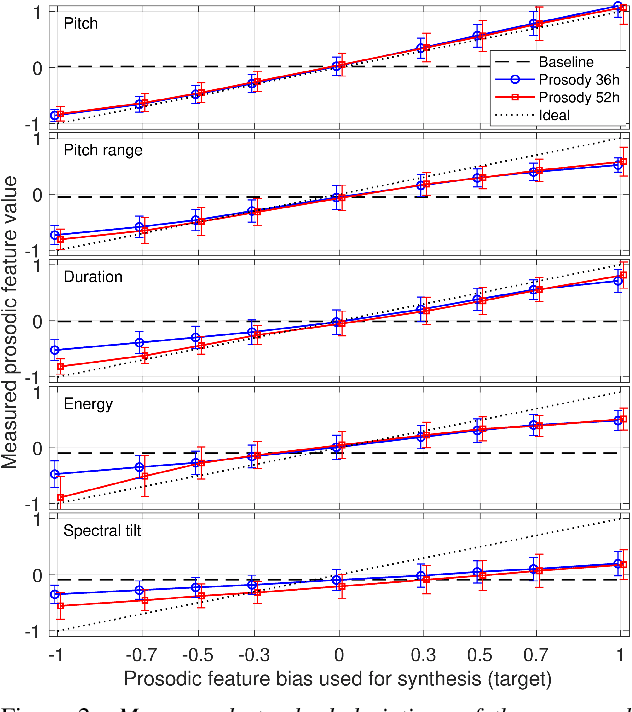
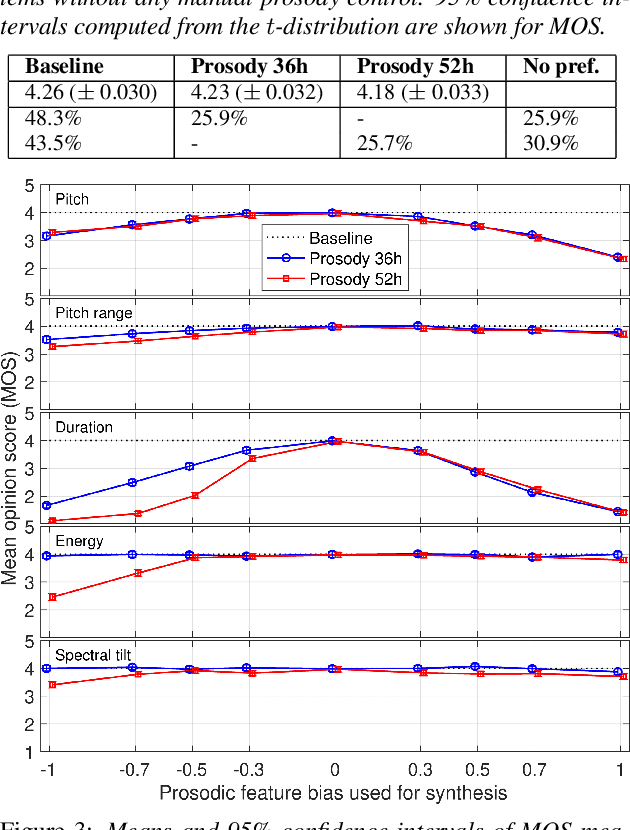
Modern neural text-to-speech (TTS) synthesis can generate speech that is indistinguishable from natural speech. However, the prosody of generated utterances often represents the average prosodic style of the database instead of having wide prosodic variation. Moreover, the generated prosody is solely defined by the input text, which does not allow for different styles for the same sentence. In this work, we train a sequence-to-sequence neural network conditioned on acoustic speech features to learn a latent prosody space with intuitive and meaningful dimensions. Experiments show that a model conditioned on sentence-wise pitch, pitch range, phone duration, energy, and spectral tilt can effectively control each prosodic dimension and generate a wide variety of speaking styles, while maintaining similar mean opinion score (4.23) to our Tacotron baseline (4.26).