 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Voice Trigger Detection with Metric Learning
Apr 05, 2022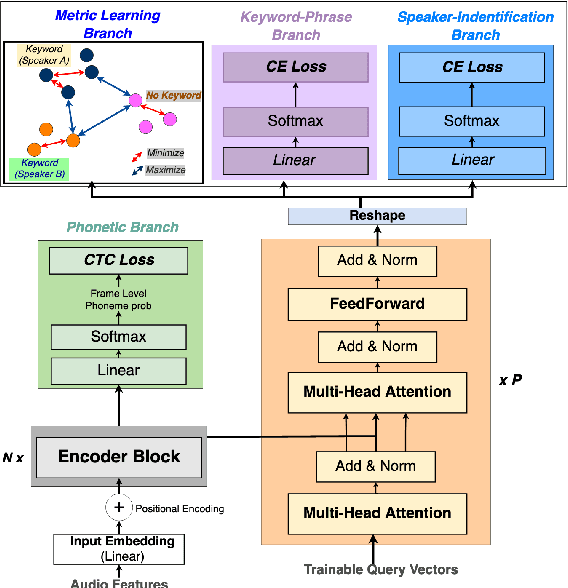

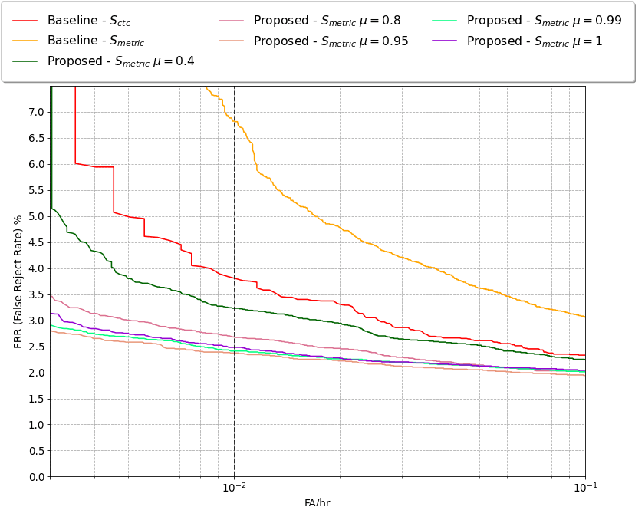
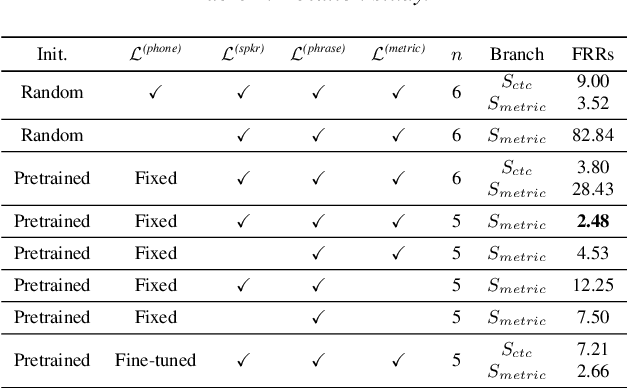
Voice trigger detection is an important task, which enables activating a voice assistant when a target user speaks a keyword phrase. A detector is typically trained on speech data independent of speaker information and used for the voice trigger detection task. However, such a speaker independent voice trigger detector typically suffers from performance degradation on speech from underrepresented groups, such as accented speakers. In this work, we propose a novel voice trigger detector that can use a small number of utterances from a target speaker to improve detection accuracy. Our proposed model employs an encoder-decoder architecture. While the encoder performs speaker independent voice trigger detection, similar to the conventional detector, the decoder predicts a personalized embedding for each utterance. A personalized voice trigger score is then obtained as a similarity score between the embeddings of enrollment utterances and a test utterance. The personalized embedding allows adapting to target speaker's speech when computing the voice trigger score, hence improving voice trigger detection accuracy. Experimental results show that the proposed approach achieves a 38% relative reduction in a false rejection rate (FRR) compared to a baseline speaker independent voice trigger model.
Whispered and Lombard Neural Speech Synthesis
Jan 13, 2021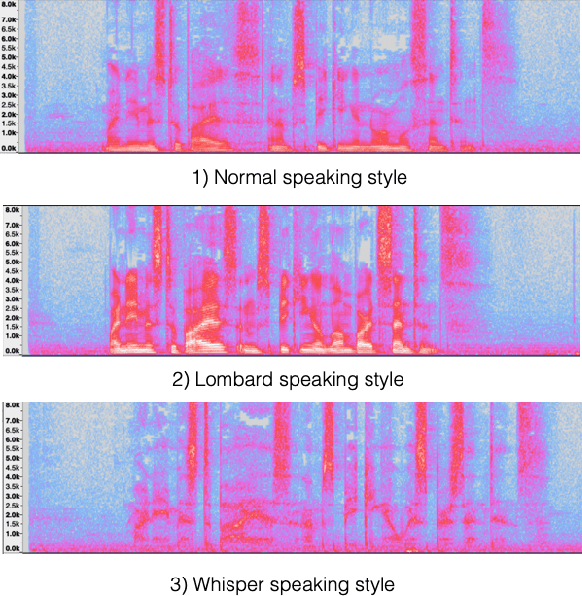

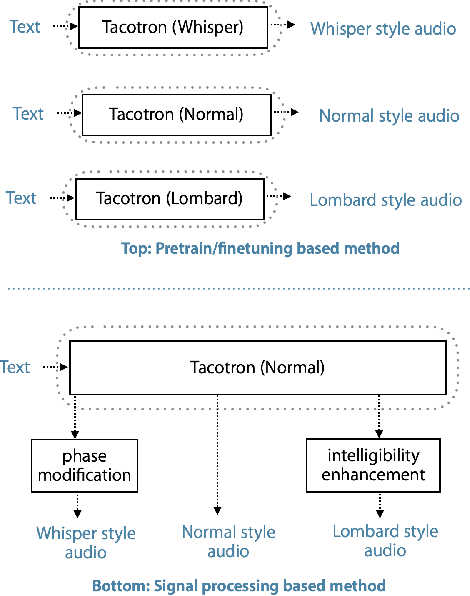
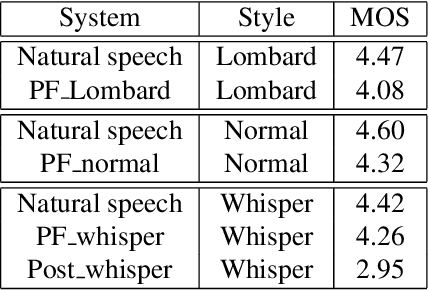
It is desirable for a text-to-speech system to take into account the environment where synthetic speech is presented, and provide appropriate context-dependent output to the user. In this paper, we present and compare various approaches for generating different speaking styles, namely, normal, Lombard, and whisper speech, using only limited data. The following systems are proposed and assessed: 1) Pre-training and fine-tuning a model for each style. 2) Lombard and whisper speech conversion through a signal processing based approach. 3) Multi-style generation using a single model based on a speaker verification model. Our mean opinion score and AB preference listening tests show that 1) we can generate high quality speech through the pre-training/fine-tuning approach for all speaking styles. 2) Although our speaker verification (SV) model is not explicitly trained to discriminate different speaking styles, and no Lombard and whisper voice is used for pre-training this system, the SV model can be used as a style encoder for generating different style embeddings as input for the Tacotron system. We also show that the resulting synthetic Lombard speech has a significant positive impact on intelligibility gain.
Incorporating Bilingual Dictionaries for Low Resource Semi-Supervised Neural Machine Translation
Apr 05, 2020



We explore ways of incorporating bilingual dictionaries to enable semi-supervised neural machine translation. Conventional back-translation methods have shown success in leveraging target side monolingual data. However, since the quality of back-translation models is tied to the size of the available parallel corpora, this could adversely impact the synthetically generated sentences in a low resource setting. We propose a simple data augmentation technique to address both this shortcoming. We incorporate widely available bilingual dictionaries that yield word-by-word translations to generate synthetic sentences. This automatically expands the vocabulary of the model while maintaining high quality content. Our method shows an appreciable improvement in performance over strong baselines.