 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Centric Framework for Composable NLP Workflows
Mar 03, 2021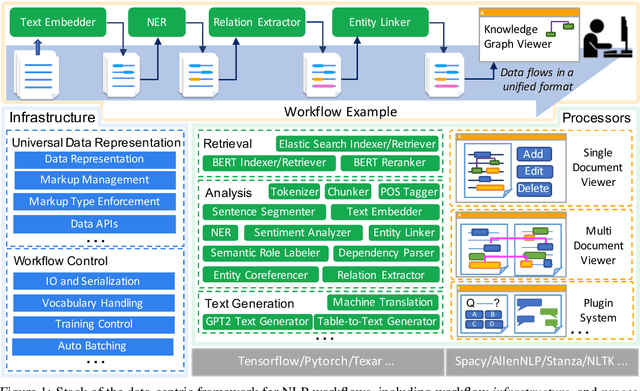
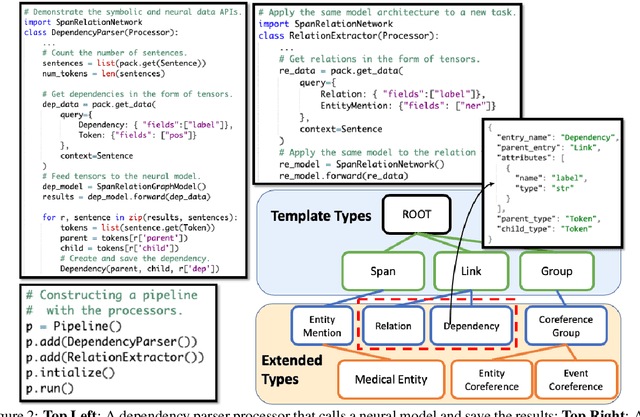
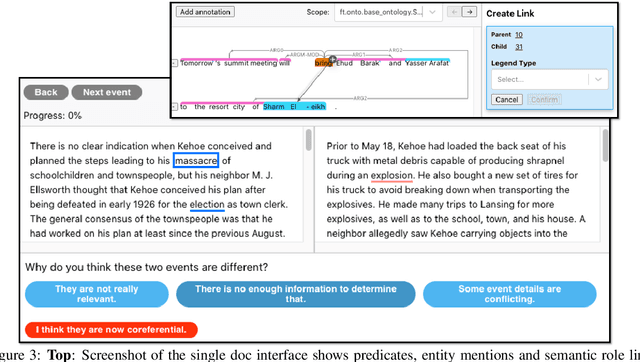

Empirical natural language processing (NLP) systems in application domains (e.g., healthcare, finance, education) involve interoperation among multiple components, ranging from data ingestion, human annotation, to text retrieval, analysis, generation, and visualization. We establish a unified open-source framework to support fast development of such sophisticated NLP workflows in a composable manner. The framework introduces a uniform data representation to encode heterogeneous results by a wide range of NLP tasks. It offers a large repository of processors for NLP tasks, visualization, and annotation, which can be easily assembled with full interoperability under the unified representation. The highly extensible framework allows plugging in custom processors from external off-the-shelf NLP and deep learning libraries. The whole framework is delivered through two modularized yet integratable open-source projects, namely Forte1 (for workflow infrastructure and NLP function processors) and Stave2 (for user interaction, visualization, and annotation).
Incorporating Bilingual Dictionaries for Low Resource Semi-Supervised Neural Machine Translation
Apr 05, 2020



We explore ways of incorporating bilingual dictionaries to enable semi-supervised neural machine translation. Conventional back-translation methods have shown success in leveraging target side monolingual data. However, since the quality of back-translation models is tied to the size of the available parallel corpora, this could adversely impact the synthetically generated sentences in a low resource setting. We propose a simple data augmentation technique to address both this shortcoming. We incorporate widely available bilingual dictionaries that yield word-by-word translations to generate synthetic sentences. This automatically expands the vocabulary of the model while maintaining high quality content. Our method shows an appreciable improvement in performance over strong baselines.