 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensory-driven microinterventions for improved health and wellbeing
Mar 18, 2025

The five senses are gateways to our wellbeing and their decline is considered a significant public health challenge which is linked to multiple conditions that contribute significantly to morbidity and mortality. Modern technology, with its ubiquitous nature and fast data processing has the ability to leverage the power of the senses to transform our approach to day to day healthcare, with positive effects on our quality of life. Here, we introduce the idea of sensory-driven microinterventions for preventative, personalised healthcare. Microinterventions are targeted, timely, minimally invasive strategies that seamlessly integrate into our daily life. This idea harnesses human's sensory capabilities, leverages technological advances in sensory stimulation and real-time processing ability for sensing the senses. The collection of sensory data from our continuous interaction with technology - for example the tone of voice, gait movement, smart home behaviour - opens up a shift towards personalised technology-enabled, sensory-focused healthcare interventions, coupled with the potential of early detection and timely treatment of sensory deficits that can signal critical health insights, especially for neurodegenerative diseases such as Parkinson's disease.
Exploring Human-AI Perception Alignment in Sensory Experiences: Do LLMs Understand Textile Hand?
Jun 05, 2024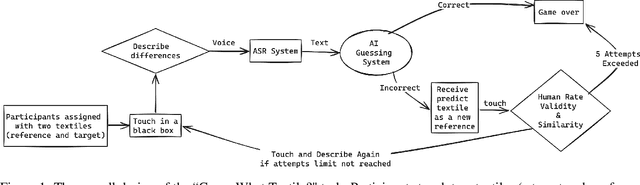


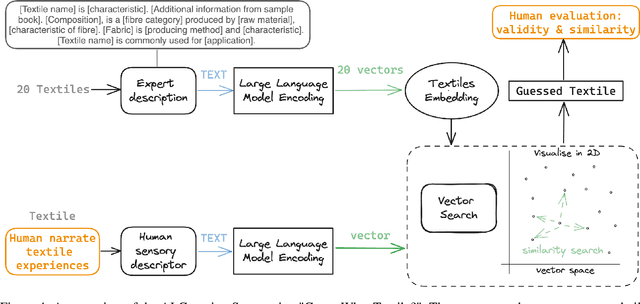
Aligning large language models (LLMs) behaviour with human intent is critical for future AI. An important yet often overlooked aspect of this alignment is the perceptual alignment. Perceptual modalities like touch are more multifaceted and nuanced compared to other sensory modalities such as vision. This work investigates how well LLMs align with human touch experiences using the "textile hand" task. We created a "Guess What Textile" interaction in which participants were given two textile samples -- a target and a reference -- to handle. Without seeing them, participants described the differences between them to the LLM. Using these descriptions, the LLM attempted to identify the target textile by assessing similarity within its high-dimensional embedding space. Our results suggest that a degree of perceptual alignment exists, however varies significantly among different textile samples. For example, LLM predictions are well aligned for silk satin, but not for cotton denim. Moreover, participants didn't perceive their textile experiences closely matched by the LLM predictions. This is only the first exploration into perceptual alignment around touch, exemplified through textile hand. We discuss possible sources of this alignment variance, and how better human-AI perceptual alignment can benefit future everyday tasks.
Expressive, Variable, and Controllable Duration Modelling in TTS
Jun 28, 2022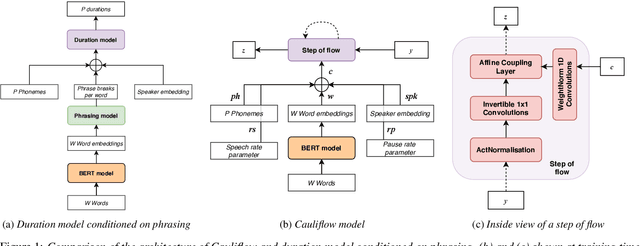
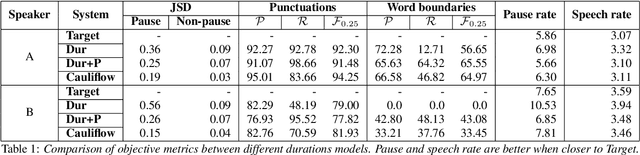
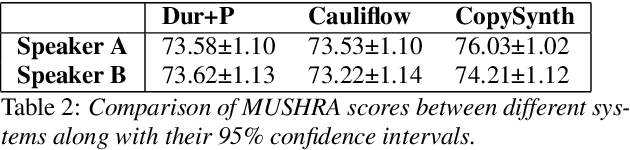
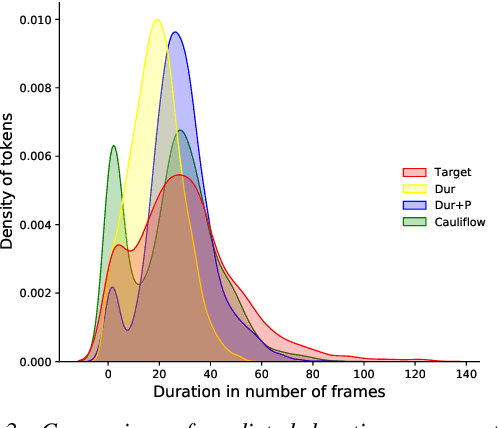
Duration modelling has become an important research problem once more with the rise of non-attention neural text-to-speech systems. The current approaches largely fall back to relying on previous statistical parametric speech synthesis technology for duration prediction, which poorly models the expressiveness and variability in speech. In this paper, we propose two alternate approaches to improve duration modelling. First, we propose a duration model conditioned on phrasing that improves the predicted durations and provides better modelling of pauses. We show that the duration model conditioned on phrasing improves the naturalness of speech over our baseline duration model. Second, we also propose a multi-speaker duration model called Cauliflow, that uses normalising flows to predict durations that better match the complex target duration distribution. Cauliflow performs on par with our other proposed duration model in terms of naturalness, whilst providing variable durations for the same prompt and variable levels of expressiveness. Lastly, we propose to condition Cauliflow on parameters that provide an intuitive control of the pacing and pausing in the synthesised speech in a novel way.