 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis and Utilization of Entrainment on Acoustic and Emotion Features in User-agent Dialogue
Dec 07, 2022



Entrainment is the phenomenon by which an interlocutor adapts their speaking style to align with their partner in conversations. It has been found in different dimensions as acoustic, prosodic, lexical or syntactic. In this work, we explore and utilize the entrainment phenomenon to improve spoken dialogue systems for voice assistants. We first examine the existence of the entrainment phenomenon in human-to-human dialogues in respect to acoustic feature and then extend the analysis to emotion features. The analysis results show strong evidence of entrainment in terms of both acoustic and emotion features. Based on this findings, we implement two entrainment policies and assess if the integration of entrainment principle into a Text-to-Speech (TTS) system improves the synthesis performance and the user experience. It is found that the integration of the entrainment principle into a TTS system brings performance improvement when considering acoustic features, while no obvious improvement is observed when considering emotion features.
Discrete acoustic space for an efficient sampling in neural text-to-speech
Oct 24, 2021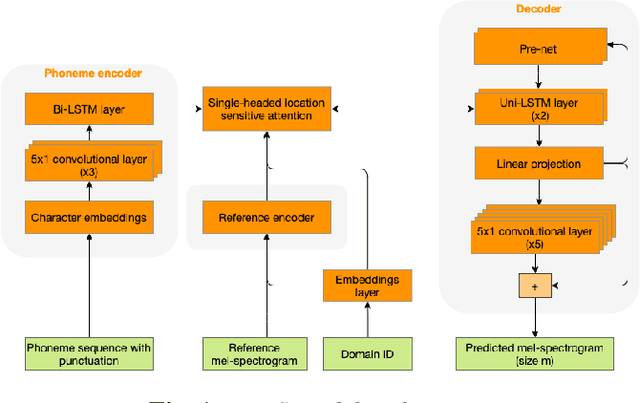
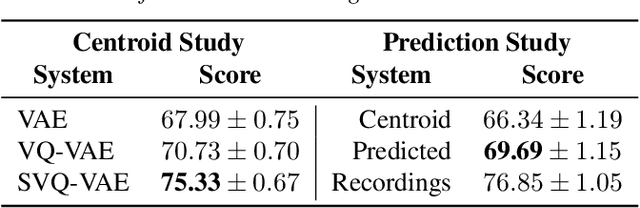
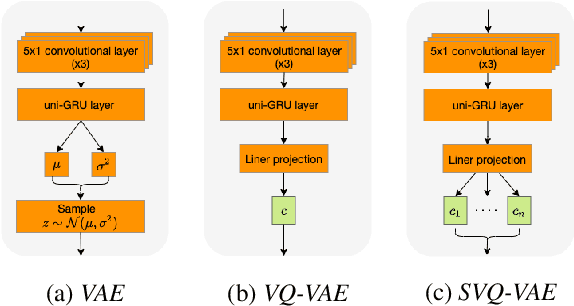
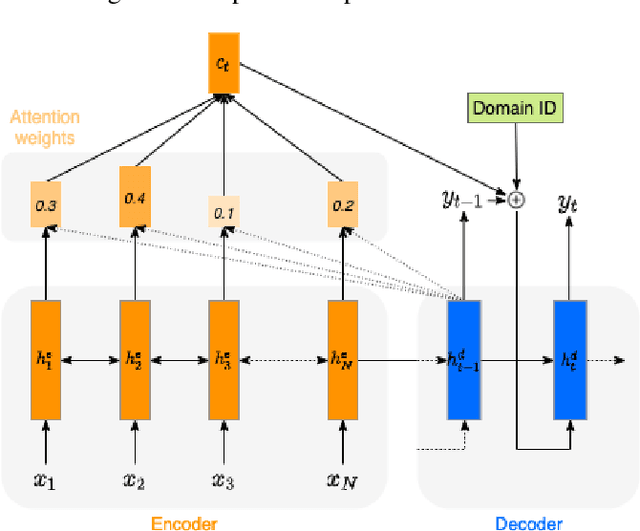
We present an SVQ-VAE architecture using a split vector quantizer for NTTS, as an enhancement to the well-known VAE and VQ-VAE architectures. Compared to these previous architectures, our proposed model retains the benefits of using an utterance-level bottleneck, while reducing the associated loss of representation power. We train the model on recordings in the highly expressive task-oriented dialogues domain and show that SVQ-VAE achieves a statistically significant improvement in naturalness over the VAE and VQ-VAE models. Furthermore, we demonstrate that the SVQ-VAE acoustic space is predictable from text, reducing the gap between the standard constant vector synthesis and vocoded recordings by 32%.