 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware abstention in medical diagnosis based on medical texts
Feb 25, 2025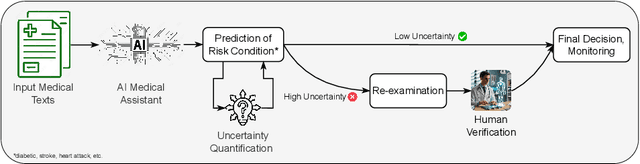
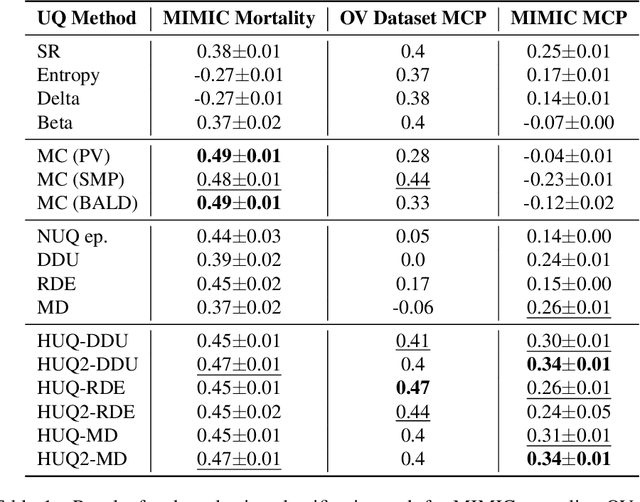
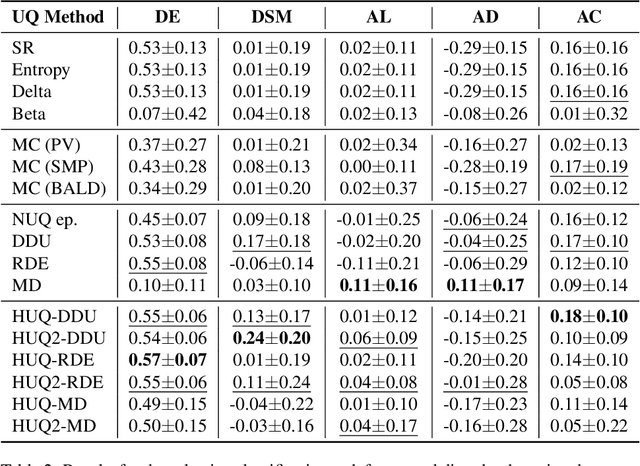
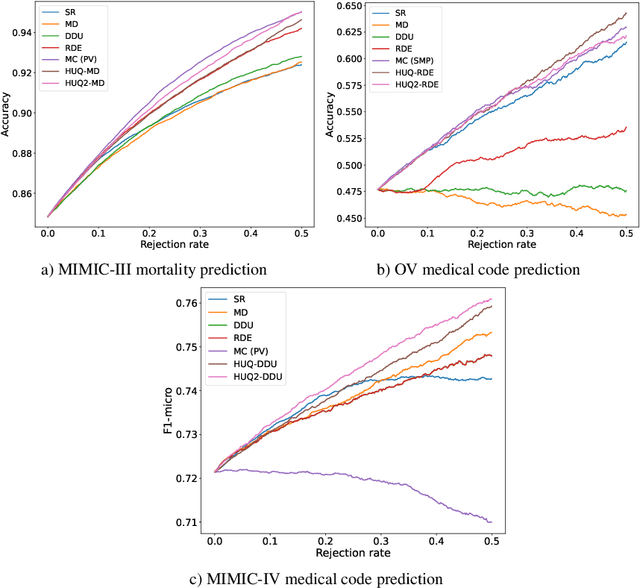
This study addresses the critical issue of reliability for AI-assisted medical diagnosis. We focus on the selection prediction approach that allows the diagnosis system to abstain from providing the decision if it is not confident in the diagnosis. Such selective prediction (or abstention) approaches are usually based on the modeling predictive uncertainty of machine learning models involved. This study explores uncertainty quantification in machine learning models for medical text analysis, addressing diverse tasks across multiple datasets. We focus on binary mortality prediction from textual data in MIMIC-III, multi-label medical code prediction using ICD-10 codes from MIMIC-IV, and multi-class classification with a private outpatient visits dataset. Additionally, we analyze mental health datasets targeting depression and anxiety detection, utilizing various text-based sources, such as essays, social media posts, and clinical descriptions. In addition to comparing uncertainty methods, we introduce HUQ-2, a new state-of-the-art method for enhancing reliability in selective prediction tasks. Our results provide a detailed comparison of uncertainty quantification methods. They demonstrate the effectiveness of HUQ-2 in capturing and evaluating uncertainty, paving the way for more reliable and interpretable applications in medical text analysis.
Analyzing Local Representations of Self-supervised Vision Transformers
Dec 31, 2023



In this paper, we present a comparative analysis of various self-supervised Vision Transformers (ViTs), focusing on their local representative power. Inspired by large language models, we examine the abilities of ViTs to perform various computer vision tasks with little to no fine-tuning. We design an evaluation framework to analyze the quality of local, i.e. patch-level, representations in the context of few-shot semantic segmentation, instance identification, object retrieval, and tracking. We discover that contrastive learning based methods like DINO produce more universal patch representations that can be immediately applied for downstream tasks with no parameter tuning, compared to masked image modeling. The embeddings learned using the latter approach, e.g. in masked autoencoders, have high variance features that harm distance-based algorithms, such as k-NN, and do not contain useful information for most downstream tasks. Furthermore, we demonstrate that removing these high-variance features enhances k-NN by providing an analysis of the benchmarks for this work and for Scale-MAE, a recent extension of masked autoencoders. Finally, we find an object instance retrieval setting where DINOv2, a model pretrained on two orders of magnitude more data, performs worse than its less compute-intensive counterpart DINO.