 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning for Domain Adaptation in Neural Machine Translation
May 14, 2019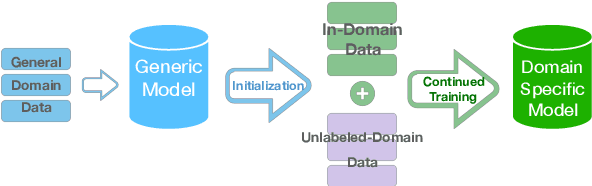
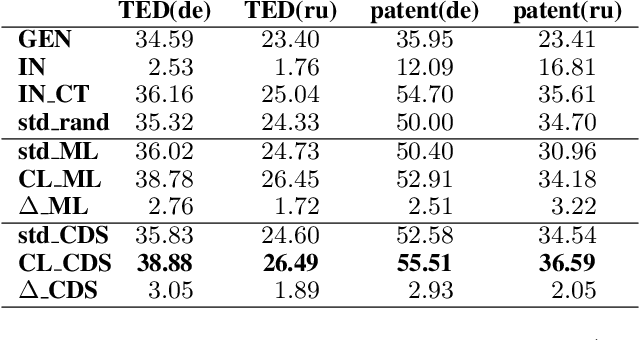
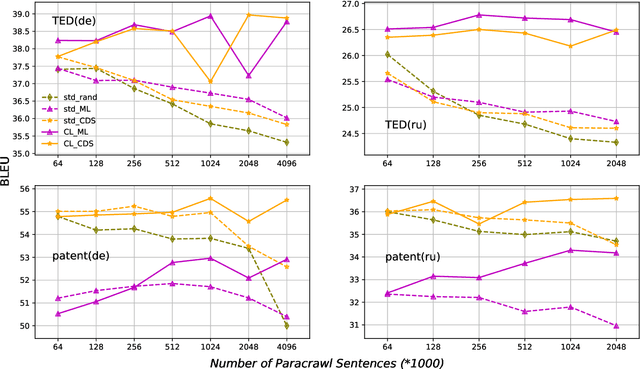
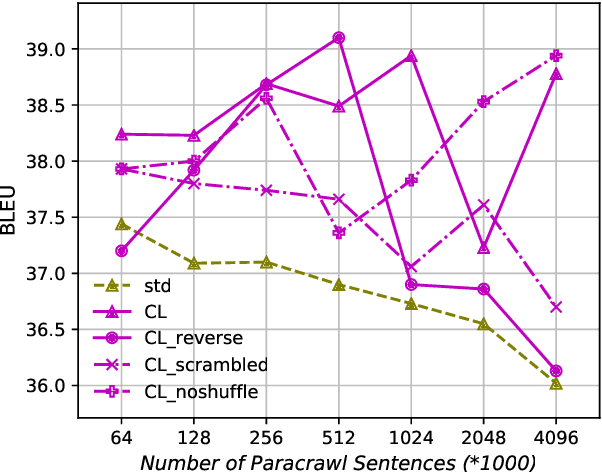
We introduce a curriculum learning approach to adapt generic neural machine translation models to a specific domain. Samples are grouped by their similarities to the domain of interest and each group is fed to the training algorithm with a particular schedule. This approach is simple to implement on top of any neural framework or architecture, and consistently outperforms both unadapted and adapted baselines in experiments with two distinct domains and two language pairs.
Character-Aware Decoder for Neural Machine Translation
Sep 11, 2018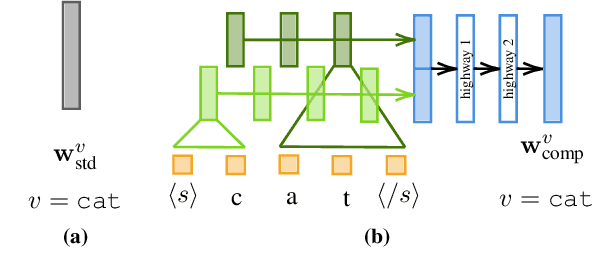

Standard neural machine translation (NMT) systems operate primarily on words, ignoring lower-level patterns of morphology. We present a character-aware decoder for NMT that can simultaneously work with both word-level and subword-level sequences which is designed to capture such patterns. We achieve character-awareness by augmenting both the softmax and embedding layers of an attention-based encoder-decoder network with convolutional neural networks that operate on spelling of a word (or subword). While character-aware embeddings have been successfully used in the source-side, we find that mixing character-aware embeddings with standard embeddings is crucial in the target-side. Furthermore, we show that a simple approximate softmax layer can be used for large target-side vocabularies which would otherwise require prohibitively large memory. We experiment on the TED multi-target dataset, translating English into 14 typologically diverse languages. We find that in this low-resource setting, the character-aware decoder provides consistent improvements over word-level and subword-level counterparts with BLEU score gains of up to +3.37.
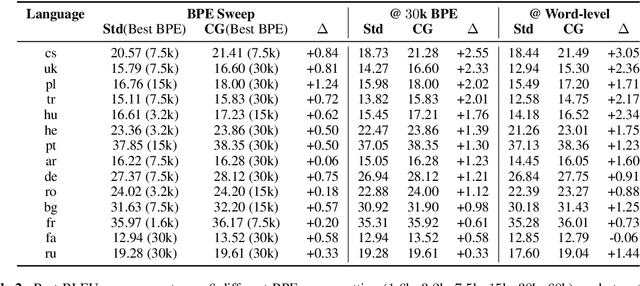
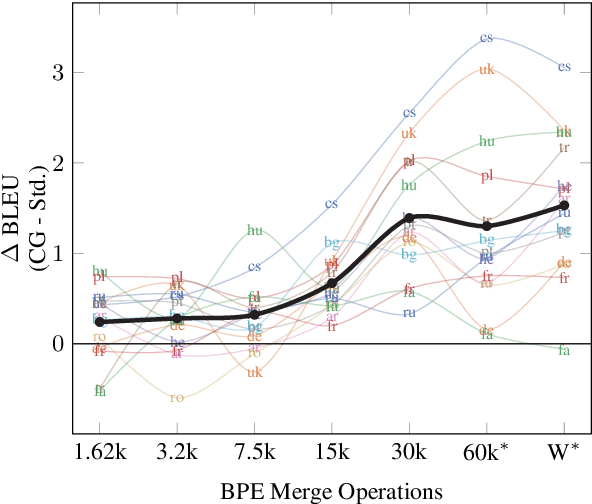
BPE and CharCNNs for Translation of Morphology: A Cross-Lingual Comparison and Analysis
Sep 08, 2018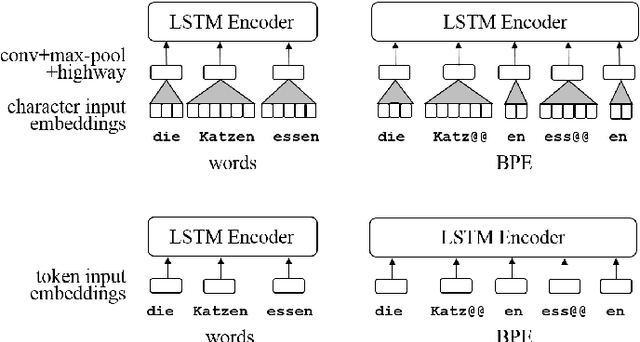
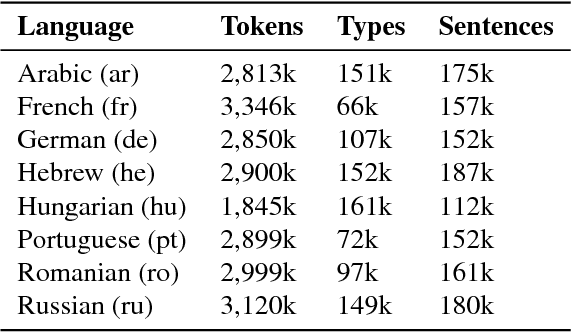
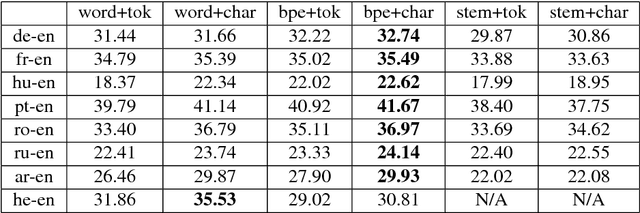
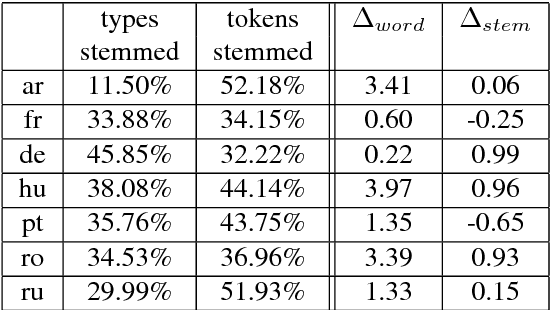
Neural Machine Translation (NMT) in low-resource settings and of morphologically rich languages is made difficult in part by data sparsity of vocabulary words. Several methods have been used to help reduce this sparsity, notably Byte-Pair Encoding (BPE) and a character-based CNN layer (charCNN). However, the charCNN has largely been neglected, possibly because it has only been compared to BPE rather than combined with it. We argue for a reconsideration of the charCNN, based on cross-lingual improvements on low-resource data. We translate from 8 languages into English, using a multi-way parallel collection of TED transcripts. We find that in most cases, using both BPE and a charCNN performs best, while in Hebrew, using a charCNN over words is best.
Hard Non-Monotonic Attention for Character-Level Transduction
Aug 29, 2018

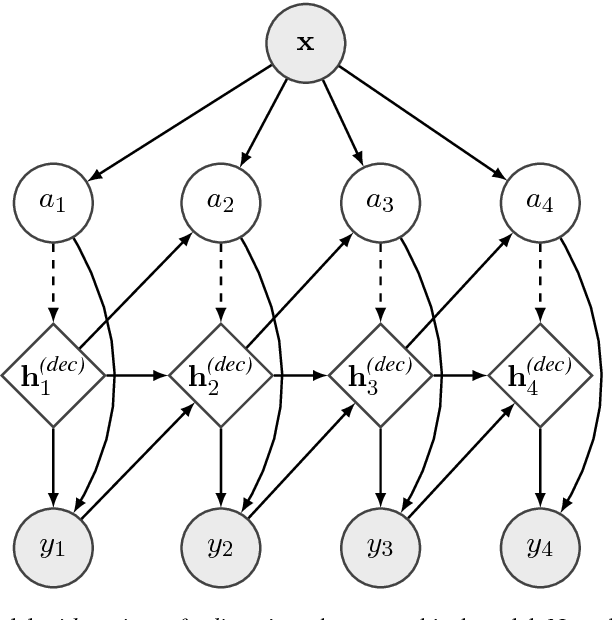

Character-level string-to-string transduction is an important component of various NLP tasks. The goal is to map an input string to an output string, where the strings may be of different lengths and have characters taken from different alphabets. Recent approaches have used sequence-to-sequence models with an attention mechanism to learn which parts of the input string the model should focus on during the generation of the output string. Both soft attention and hard monotonic attention have been used, but hard non-monotonic attention has only been used in other sequence modeling tasks such as image captioning and has required a stochastic approximation to compute the gradient. In this work, we introduce an exact, polynomial-time algorithm for marginalizing over the exponential number of non-monotonic alignments between two strings, showing that hard attention models can be viewed as neural reparameterizations of the classical IBM Model 1. We compare soft and hard non-monotonic attention experimentally and find that the exact algorithm significantly improves performance over the stochastic approximation and outperforms soft attention.