 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBPE and CharCNNs for Translation of Morphology: A Cross-Lingual Comparison and Analysis
Paper and Code
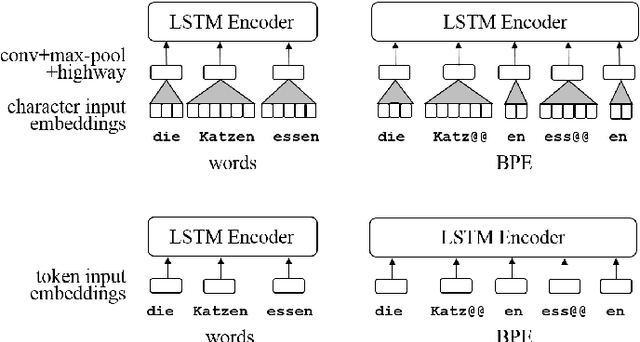
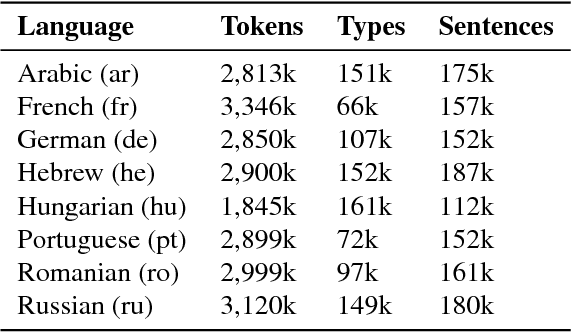
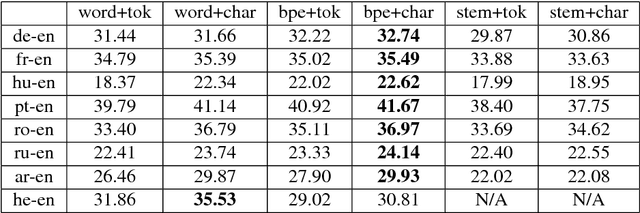
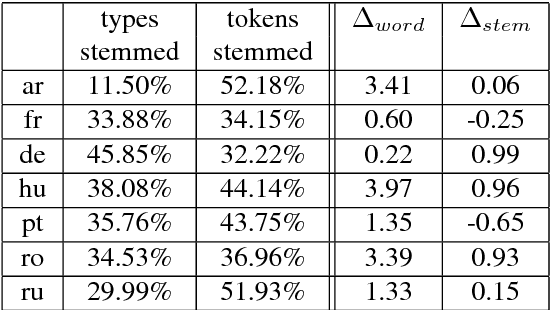
Neural Machine Translation (NMT) in low-resource settings and of morphologically rich languages is made difficult in part by data sparsity of vocabulary words. Several methods have been used to help reduce this sparsity, notably Byte-Pair Encoding (BPE) and a character-based CNN layer (charCNN). However, the charCNN has largely been neglected, possibly because it has only been compared to BPE rather than combined with it. We argue for a reconsideration of the charCNN, based on cross-lingual improvements on low-resource data. We translate from 8 languages into English, using a multi-way parallel collection of TED transcripts. We find that in most cases, using both BPE and a charCNN performs best, while in Hebrew, using a charCNN over words is best.