 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter-Aware Decoder for Neural Machine Translation
Paper and Code
Sep 11, 2018

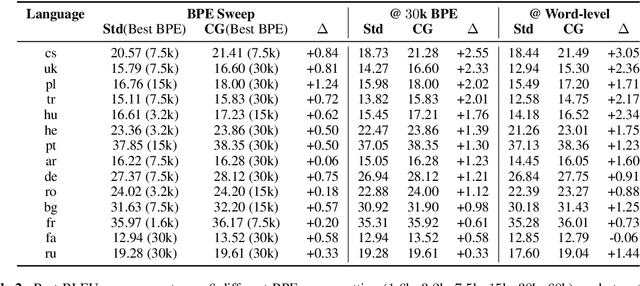
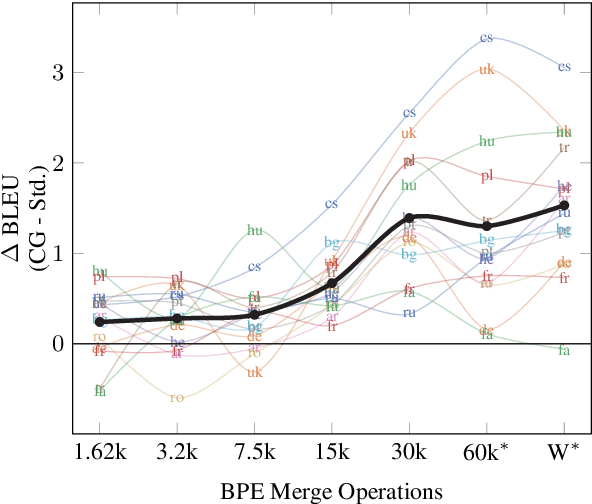
Standard neural machine translation (NMT) systems operate primarily on words, ignoring lower-level patterns of morphology. We present a character-aware decoder for NMT that can simultaneously work with both word-level and subword-level sequences which is designed to capture such patterns. We achieve character-awareness by augmenting both the softmax and embedding layers of an attention-based encoder-decoder network with convolutional neural networks that operate on spelling of a word (or subword). While character-aware embeddings have been successfully used in the source-side, we find that mixing character-aware embeddings with standard embeddings is crucial in the target-side. Furthermore, we show that a simple approximate softmax layer can be used for large target-side vocabularies which would otherwise require prohibitively large memory. We experiment on the TED multi-target dataset, translating English into 14 typologically diverse languages. We find that in this low-resource setting, the character-aware decoder provides consistent improvements over word-level and subword-level counterparts with BLEU score gains of up to +3.37.