 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing of heterogeneous corpora for training of an ASR system
Paper and Code


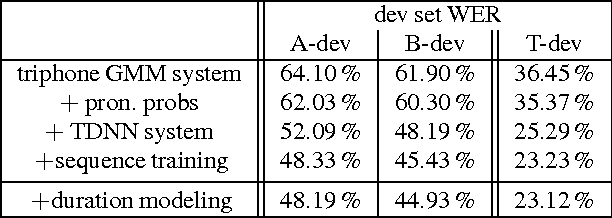
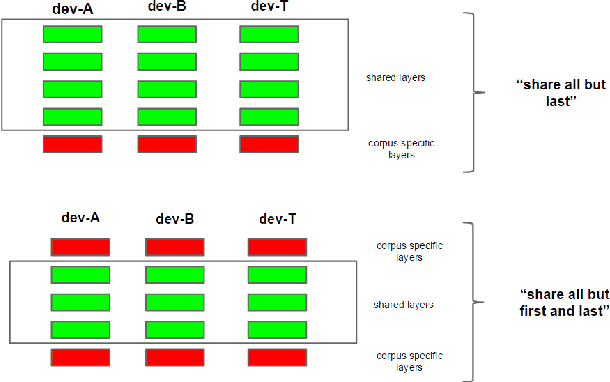
The paper summarizes the development of the LVCSR system built as a part of the Pashto speech-translation system at the SCALE (Summer Camp for Applied Language Exploration) 2015 workshop on "Speech-to-text-translation for low-resource languages". The Pashto language was chosen as a good "proxy" low-resource language, exhibiting multiple phenomena which make the speech-recognition and and speech-to-text-translation systems development hard. Even when the amount of data is seemingly sufficient, given the fact that the data originates from multiple sources, the preliminary experiments reveal that there is little to no benefit in merging (concatenating) the corpora and more elaborate ways of making use of all of the data must be worked out. This paper concentrates only on the LVCSR part and presents a range of different techniques that were found to be useful in order to benefit from multiple different corpora