 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous and Self-Adapting System for Synthetic Media Detection and Attribution
Apr 04, 2025Rapid advances in generative AI have enabled the creation of highly realistic synthetic images, which, while beneficial in many domains, also pose serious risks in terms of disinformation, fraud, and other malicious applications. Current synthetic image identification systems are typically static, relying on feature representations learned from known generators; as new generative models emerge, these systems suffer from severe performance degradation. In this paper, we introduce the concept of an autonomous self-adaptive synthetic media identification system -- one that not only detects synthetic images and attributes them to known sources but also autonomously identifies and incorporates novel generators without human intervention. Our approach leverages an open-set identification strategy with an evolvable embedding space that distinguishes between known and unknown sources. By employing an unsupervised clustering method to aggregate unknown samples into high-confidence clusters and continuously refining its decision boundaries, our system maintains robust detection and attribution performance even as the generative landscape evolves. Extensive experiments demonstrate that our method significantly outperforms existing approaches, marking a crucial step toward universal, adaptable forensic systems in the era of rapidly advancing generative models.
MVFNet: Multipurpose Video Forensics Network using Multiple Forms of Forensic Evidence
Mar 26, 2025



While videos can be falsified in many different ways, most existing forensic networks are specialized to detect only a single manipulation type (e.g. deepfake, inpainting). This poses a significant issue as the manipulation used to falsify a video is not known a priori. To address this problem, we propose MVFNet - a multipurpose video forensics network capable of detecting multiple types of manipulations including inpainting, deepfakes, splicing, and editing. Our network does this by extracting and jointly analyzing a broad set of forensic feature modalities that capture both spatial and temporal anomalies in falsified videos. To reliably detect and localize fake content of all shapes and sizes, our network employs a novel Multi-Scale Hierarchical Transformer module to identify forensic inconsistencies across multiple spatial scales. Experimental results show that our network obtains state-of-the-art performance in general scenarios where multiple different manipulations are possible, and rivals specialized detectors in targeted scenarios.
Forensic Self-Descriptions Are All You Need for Zero-Shot Detection, Open-Set Source Attribution, and Clustering of AI-generated Images
Mar 26, 2025


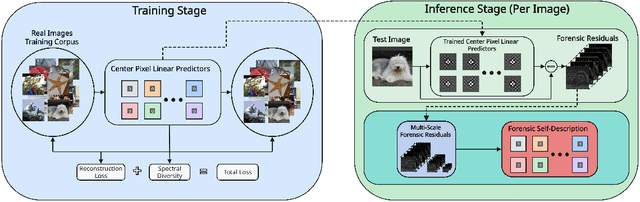
The emergence of advanced AI-based tools to generate realistic images poses significant challenges for forensic detection and source attribution, especially as new generative techniques appear rapidly. Traditional methods often fail to generalize to unseen generators due to reliance on features specific to known sources during training. To address this problem, we propose a novel approach that explicitly models forensic microstructures - subtle, pixel-level patterns unique to the image creation process. Using only real images in a self-supervised manner, we learn a set of diverse predictive filters to extract residuals that capture different aspects of these microstructures. By jointly modeling these residuals across multiple scales, we obtain a compact model whose parameters constitute a unique forensic self-description for each image. This self-description enables us to perform zero-shot detection of synthetic images, open-set source attribution of images, and clustering based on source without prior knowledge. Extensive experiments demonstrate that our method achieves superior accuracy and adaptability compared to competing techniques, advancing the state of the art in synthetic media forensics.
Beyond Deepfake Images: Detecting AI-Generated Videos
Apr 24, 2024Recent advances in generative AI have led to the development of techniques to generate visually realistic synthetic video. While a number of techniques have been developed to detect AI-generated synthetic images, in this paper we show that synthetic image detectors are unable to detect synthetic videos. We demonstrate that this is because synthetic video generators introduce substantially different traces than those left by image generators. Despite this, we show that synthetic video traces can be learned, and used to perform reliable synthetic video detection or generator source attribution even after H.264 re-compression. Furthermore, we demonstrate that while detecting videos from new generators through zero-shot transferability is challenging, accurate detection of videos from a new generator can be achieved through few-shot learning.
E3: Ensemble of Expert Embedders for Adapting Synthetic Image Detectors to New Generators Using Limited Data
Apr 12, 2024As generative AI progresses rapidly, new synthetic image generators continue to emerge at a swift pace. Traditional detection methods face two main challenges in adapting to these generators: the forensic traces of synthetic images from new techniques can vastly differ from those learned during training, and access to data for these new generators is often limited. To address these issues, we introduce the Ensemble of Expert Embedders (E3), a novel continual learning framework for updating synthetic image detectors. E3 enables the accurate detection of images from newly emerged generators using minimal training data. Our approach does this by first employing transfer learning to develop a suite of expert embedders, each specializing in the forensic traces of a specific generator. Then, all embeddings are jointly analyzed by an Expert Knowledge Fusion Network to produce accurate and reliable detection decisions. Our experiments demonstrate that E3 outperforms existing continual learning methods, including those developed specifically for synthetic image detection.
Open Set Synthetic Image Source Attribution
Aug 22, 2023AI-generated images have become increasingly realistic and have garnered significant public attention. While synthetic images are intriguing due to their realism, they also pose an important misinformation threat. To address this new threat, researchers have developed multiple algorithms to detect synthetic images and identify their source generators. However, most existing source attribution techniques are designed to operate in a closed-set scenario, i.e. they can only be used to discriminate between known image generators. By contrast, new image-generation techniques are rapidly emerging. To contend with this, there is a great need for open-set source attribution techniques that can identify when synthetic images have originated from new, unseen generators. To address this problem, we propose a new metric learning-based approach. Our technique works by learning transferrable embeddings capable of discriminating between generators, even when they are not seen during training. An image is first assigned to a candidate generator, then is accepted or rejected based on its distance in the embedding space from known generators' learned reference points. Importantly, we identify that initializing our source attribution embedding network by pretraining it on image camera identification can improve our embeddings' transferability. Through a series of experiments, we demonstrate our approach's ability to attribute the source of synthetic images in open-set scenarios.
Comprehensive Dataset of Synthetic and Manipulated Overhead Imagery for Development and Evaluation of Forensic Tools
May 09, 2023We present a first of its kind dataset of overhead imagery for development and evaluation of forensic tools. Our dataset consists of real, fully synthetic and partially manipulated overhead imagery generated from a custom diffusion model trained on two sets of different zoom levels and on two sources of pristine data. We developed our model to support controllable generation of multiple manipulation categories including fully synthetic imagery conditioned on real and generated base maps, and location. We also support partial in-painted imagery with same conditioning options and with several types of manipulated content. The data consist of raw images and ground truth annotations describing the manipulation parameters. We also report benchmark performance on several tasks supported by our dataset including detection of fully and partially manipulated imagery, manipulation localization and classification.
VideoFACT: Detecting Video Forgeries Using Attention, Scene Context, and Forensic Traces
Nov 28, 2022Fake videos represent an important misinformation threat. While existing forensic networks have demonstrated strong performance on image forgeries, recent results reported on the Adobe VideoSham dataset show that these networks fail to identify fake content in videos. In this paper, we propose a new network that is able to detect and localize a wide variety of video forgeries and manipulations. To overcome challenges that existing networks face when analyzing videos, our network utilizes both forensic embeddings to capture traces left by manipulation, context embeddings to exploit forensic traces' conditional dependencies upon local scene content, and spatial attention provided by a deep, transformer-based attention mechanism. We create several new video forgery datasets and use these, along with publicly available data, to experimentally evaluate our network's performance. These results show that our proposed network is able to identify a diverse set of video forgeries, including those not encountered during training. Furthermore, our results reinforce recent findings that image forensic networks largely fail to identify fake content in videos.
Making GAN-Generated Images Difficult To Spot: A New Attack Against Synthetic Image Detectors
Apr 25, 2021

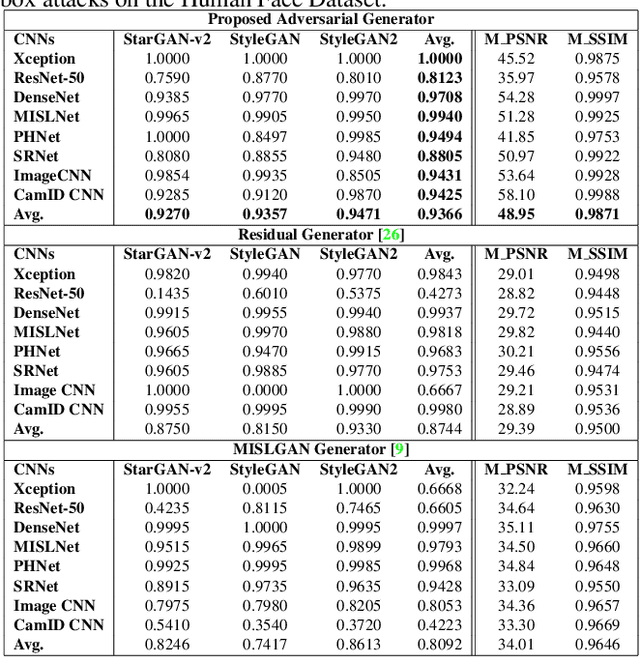
Visually realistic GAN-generated images have recently emerged as an important misinformation threat. Research has shown that these synthetic images contain forensic traces that are readily identifiable by forensic detectors. Unfortunately, these detectors are built upon neural networks, which are vulnerable to recently developed adversarial attacks. In this paper, we propose a new anti-forensic attack capable of fooling GAN-generated image detectors. Our attack uses an adversarially trained generator to synthesize traces that these detectors associate with real images. Furthermore, we propose a technique to train our attack so that it can achieve transferability, i.e. it can fool unknown CNNs that it was not explicitly trained against. We demonstrate the performance of our attack through an extensive set of experiments, where we show that our attack can fool eight state-of-the-art detection CNNs with synthetic images created using seven different GANs.
The Effect of Class Definitions on the Transferability of Adversarial Attacks Against Forensic CNNs
Jan 26, 2021
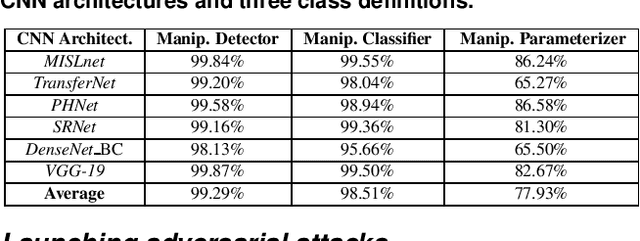
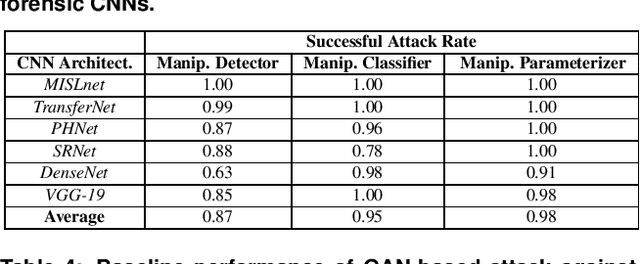
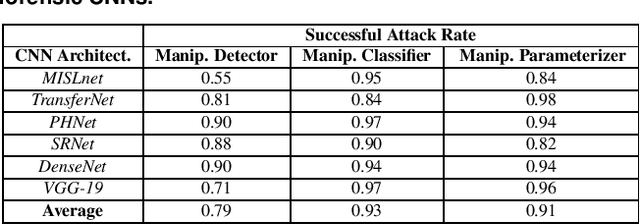
In recent years, convolutional neural networks (CNNs) have been widely used by researchers to perform forensic tasks such as image tampering detection. At the same time, adversarial attacks have been developed that are capable of fooling CNN-based classifiers. Understanding the transferability of adversarial attacks, i.e. an attacks ability to attack a different CNN than the one it was trained against, has important implications for designing CNNs that are resistant to attacks. While attacks on object recognition CNNs are believed to be transferrable, recent work by Barni et al. has shown that attacks on forensic CNNs have difficulty transferring to other CNN architectures or CNNs trained using different datasets. In this paper, we demonstrate that adversarial attacks on forensic CNNs are even less transferrable than previously thought even between virtually identical CNN architectures! We show that several common adversarial attacks against CNNs trained to identify image manipulation fail to transfer to CNNs whose only difference is in the class definitions (i.e. the same CNN architectures trained using the same data). We note that all formulations of class definitions contain the unaltered class. This has important implications for the future design of forensic CNNs that are robust to adversarial and anti-forensic attacks.