 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Silent Letters: Amplifying LLMs in Emotion Recognition with Vocal Nuances
Paper and Code
Aug 01, 2024


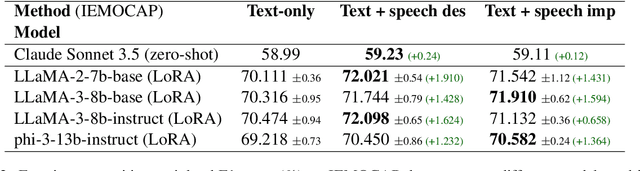
This paper introduces a novel approach to emotion detection in speech using Large Language Models (LLMs). We address the limitation of LLMs in processing audio inputs by translating speech characteristics into natural language descriptions. Our method integrates these descriptions into text prompts, enabling LLMs to perform multimodal emotion analysis without architectural modifications. We evaluate our approach on two datasets: IEMOCAP and MELD, demonstrating significant improvements in emotion recognition accuracy, particularly for high-quality audio data. Our experiments show that incorporating speech descriptions yields a 2 percentage point increase in weighted F1 score on IEMOCAP (from 70.111\% to 72.596\%). We also compare various LLM architectures and explore the effectiveness of different feature representations. Our findings highlight the potential of this approach in enhancing emotion detection capabilities of LLMs and underscore the importance of audio quality in speech-based emotion recognition tasks. We'll release the source code on Github.