 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREAM: Comparison-Based Reference-Free ELO-Ranked Automatic Evaluation for Meeting Summarization
Sep 17, 2024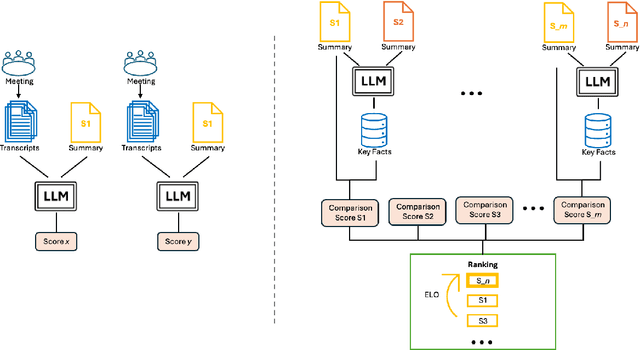


Large Language Models (LLMs) have spurred interest in automatic evaluation methods for summarization, offering a faster, more cost-effective alternative to human evaluation. However, existing methods often fall short when applied to complex tasks like long-context summarizations and dialogue-based meeting summarizations. In this paper, we introduce CREAM (Comparison-Based Reference-Free Elo-Ranked Automatic Evaluation for Meeting Summarization), a novel framework that addresses the unique challenges of evaluating meeting summaries. CREAM leverages a combination of chain-of-thought reasoning and key facts alignment to assess conciseness and completeness of model-generated summaries without requiring reference. By employing an ELO ranking system, our approach provides a robust mechanism for comparing the quality of different models or prompt configurations.
Beyond Silent Letters: Amplifying LLMs in Emotion Recognition with Vocal Nuances
Aug 01, 2024


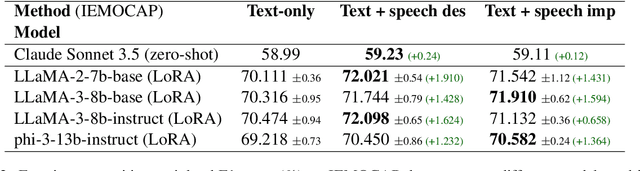
This paper introduces a novel approach to emotion detection in speech using Large Language Models (LLMs). We address the limitation of LLMs in processing audio inputs by translating speech characteristics into natural language descriptions. Our method integrates these descriptions into text prompts, enabling LLMs to perform multimodal emotion analysis without architectural modifications. We evaluate our approach on two datasets: IEMOCAP and MELD, demonstrating significant improvements in emotion recognition accuracy, particularly for high-quality audio data. Our experiments show that incorporating speech descriptions yields a 2 percentage point increase in weighted F1 score on IEMOCAP (from 70.111\% to 72.596\%). We also compare various LLM architectures and explore the effectiveness of different feature representations. Our findings highlight the potential of this approach in enhancing emotion detection capabilities of LLMs and underscore the importance of audio quality in speech-based emotion recognition tasks. We'll release the source code on Github.
Multi-Modality Multi-Loss Fusion Network
Aug 01, 2023In this work we investigate the optimal selection and fusion of features across multiple modalities and combine these in a neural network to improve emotion detection. We compare different fusion methods and examine the impact of multi-loss training within the multi-modality fusion network, identifying useful findings relating to subnet performance. Our best model achieves state-of-the-art performance for three datasets (CMU-MOSI, CMU-MOSEI and CH-SIMS), and outperforms the other methods in most metrics. We have found that training on multimodal features improves single modality testing and designing fusion methods based on dataset annotation schema enhances model performance. These results suggest a roadmap towards an optimized feature selection and fusion approach for enhancing emotion detection in neural networks.