 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffload or Overload: A Platform Measurement Study of Mobile Robotic Manipulation Workloads
Mar 18, 2026Mobile robotic manipulation--the ability of robots to navigate spaces and interact with objects--is a core capability of physical AI. Foundation models have led to breakthroughs in their performance, but at a significant computational cost. We present the first measurement study of mobile robotic manipulation workloads across onboard, edge, and cloud GPU platforms. We find that the full workload stack is infeasible to run on smaller onboard GPUs, while larger onboard GPUs drain robot batteries several hours faster. Offloading alleviates these constraints but introduces its own challenges, as additional network latency degrades task accuracy, and the bandwidth requirement makes naive cloud offloading impractical. Finally, we quantify opportunities and pitfalls of sharing compute across robot fleets. We believe our measurement study will be crucial to designing inference systems for mobile robots.
Explaining Low Perception Model Competency with High-Competency Counterfactuals
Apr 07, 2025There exist many methods to explain how an image classification model generates its decision, but very little work has explored methods to explain why a classifier might lack confidence in its prediction. As there are various reasons the classifier might lose confidence, it would be valuable for this model to not only indicate its level of uncertainty but also explain why it is uncertain. Counterfactual images have been used to visualize changes that could be made to an image to generate a different classification decision. In this work, we explore the use of counterfactuals to offer an explanation for low model competency--a generalized form of predictive uncertainty that measures confidence. Toward this end, we develop five novel methods to generate high-competency counterfactual images, namely Image Gradient Descent (IGD), Feature Gradient Descent (FGD), Autoencoder Reconstruction (Reco), Latent Gradient Descent (LGD), and Latent Nearest Neighbors (LNN). We evaluate these methods across two unique datasets containing images with six known causes for low model competency and find Reco, LGD, and LNN to be the most promising methods for counterfactual generation. We further evaluate how these three methods can be utilized by pre-trained Multimodal Large Language Models (MLLMs) to generate language explanations for low model competency. We find that the inclusion of a counterfactual image in the language model query greatly increases the ability of the model to generate an accurate explanation for the cause of low model competency, thus demonstrating the utility of counterfactual images in explaining low perception model competency.
PaRCE: Probabilistic and Reconstruction-Based Competency Estimation for Safe Navigation Under Perception Uncertainty
Sep 09, 2024



Perception-based navigation systems are useful for unmanned ground vehicle (UGV) navigation in complex terrains, where traditional depth-based navigation schemes are insufficient. However, these data-driven methods are highly dependent on their training data and can fail in surprising and dramatic ways with little warning. To ensure the safety of the vehicle and the surrounding environment, it is imperative that the navigation system is able to recognize the predictive uncertainty of the perception model and respond safely and effectively in the face of uncertainty. In an effort to enable safe navigation under perception uncertainty, we develop a probabilistic and reconstruction-based competency estimation (PaRCE) method to estimate the model's level of familiarity with an input image as a whole and with specific regions in the image. We find that the overall competency score can correctly predict correctly classified, misclassified, and out-of-distribution (OOD) samples. We also confirm that the regional competency maps can accurately distinguish between familiar and unfamiliar regions across images. We then use this competency information to develop a planning and control scheme that enables effective navigation while maintaining a low probability of error. We find that the competency-aware scheme greatly reduces the number of collisions with unfamiliar obstacles, compared to a baseline controller with no competency awareness. Furthermore, the regional competency information is very valuable in enabling efficient navigation.
Understanding the Dependence of Perception Model Competency on Regions in an Image
Jul 15, 2024While deep neural network (DNN)-based perception models are useful for many applications, these models are black boxes and their outputs are not yet well understood. To confidently enable a real-world, decision-making system to utilize such a perception model without human intervention, we must enable the system to reason about the perception model's level of competency and respond appropriately when the model is incompetent. In order for the system to make an intelligent decision about the appropriate action when the model is incompetent, it would be useful for the system to understand why the model is incompetent. We explore five novel methods for identifying regions in the input image contributing to low model competency, which we refer to as image cropping, segment masking, pixel perturbation, competency gradients, and reconstruction loss. We assess the ability of these five methods to identify unfamiliar objects, recognize regions associated with unseen classes, and identify unexplored areas in an environment. We find that the competency gradients and reconstruction loss methods show great promise in identifying regions associated with low model competency, particularly when aspects of the image that are unfamiliar to the perception model are causing this reduction in competency. Both of these methods boast low computation times and high levels of accuracy in detecting image regions that are unfamiliar to the model, allowing them to provide potential utility in decision-making pipelines. The code for reproducing our methods and results is available on GitHub: https://github.com/sarapohland/explainable-competency.
Stranger Danger! Identifying and Avoiding Unpredictable Pedestrians in RL-based Social Robot Navigation
Jul 08, 2024
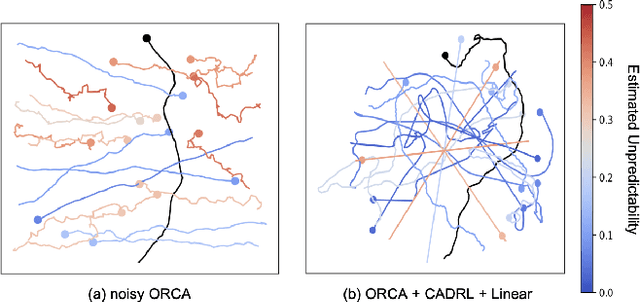


Reinforcement learning (RL) methods for social robot navigation show great success navigating robots through large crowds of people, but the performance of these learning-based methods tends to degrade in particularly challenging or unfamiliar situations due to the models' dependency on representative training data. To ensure human safety and comfort, it is critical that these algorithms handle uncommon cases appropriately, but the low frequency and wide diversity of such situations present a significant challenge for these data-driven methods. To overcome this challenge, we propose modifications to the learning process that encourage these RL policies to maintain additional caution in unfamiliar situations. Specifically, we improve the Socially Attentive Reinforcement Learning (SARL) policy by (1) modifying the training process to systematically introduce deviations into a pedestrian model, (2) updating the value network to estimate and utilize pedestrian-unpredictability features, and (3) implementing a reward function to learn an effective response to pedestrian unpredictability. Compared to the original SARL policy, our modified policy maintains similar navigation times and path lengths, while reducing the number of collisions by 82% and reducing the proportion of time spent in the pedestrians' personal space by up to 19 percentage points for the most difficult cases. We also describe how to apply these modifications to other RL policies and demonstrate that some key high-level behaviors of our approach transfer to a physical robot.