 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniScope: A Least Privilege Framework for Authorizing Tool Calling Agents
Dec 11, 2025



Tool calling agents are an emerging paradigm in LLM deployment, with major platforms such as ChatGPT, Claude, and Gemini adding connectors and autonomous capabilities. However, the inherent unreliability of LLMs introduces fundamental security risks when these agents operate over sensitive user services. Prior approaches either rely on manually written policies that require security expertise, or place LLMs in the confinement loop, which lacks rigorous security guarantees. We present MiniScope, a framework that enables tool calling agents to operate on user accounts while confining potential damage from unreliable LLMs. MiniScope introduces a novel way to automatically and rigorously enforce least privilege principles by reconstructing permission hierarchies that reflect relationships among tool calls and combining them with a mobile-style permission model to balance security and ease of use. To evaluate MiniScope, we create a synthetic dataset derived from ten popular real-world applications, capturing the complexity of realistic agentic tasks beyond existing simplified benchmarks. Our evaluation shows that MiniScope incurs only 1-6% latency overhead compared to vanilla tool calling agents, while significantly outperforming the LLM based baseline in minimizing permissions as well as computational and operational costs.
GoEX: Perspectives and Designs Towards a Runtime for Autonomous LLM Applications
Apr 10, 2024Large Language Models (LLMs) are evolving beyond their classical role of providing information within dialogue systems to actively engaging with tools and performing actions on real-world applications and services. Today, humans verify the correctness and appropriateness of the LLM-generated outputs (e.g., code, functions, or actions) before putting them into real-world execution. This poses significant challenges as code comprehension is well known to be notoriously difficult. In this paper, we study how humans can efficiently collaborate with, delegate to, and supervise autonomous LLMs in the future. We argue that in many cases, "post-facto validation" - verifying the correctness of a proposed action after seeing the output - is much easier than the aforementioned "pre-facto validation" setting. The core concept behind enabling a post-facto validation system is the integration of an intuitive undo feature, and establishing a damage confinement for the LLM-generated actions as effective strategies to mitigate the associated risks. Using this, a human can now either revert the effect of an LLM-generated output or be confident that the potential risk is bounded. We believe this is critical to unlock the potential for LLM agents to interact with applications and services with limited (post-facto) human involvement. We describe the design and implementation of our open-source runtime for executing LLM actions, Gorilla Execution Engine (GoEX), and present open research questions towards realizing the goal of LLMs and applications interacting with each other with minimal human supervision. We release GoEX at https://github.com/ShishirPatil/gorilla/.
Mark My Words: Analyzing and Evaluating Language Model Watermarks
Dec 07, 2023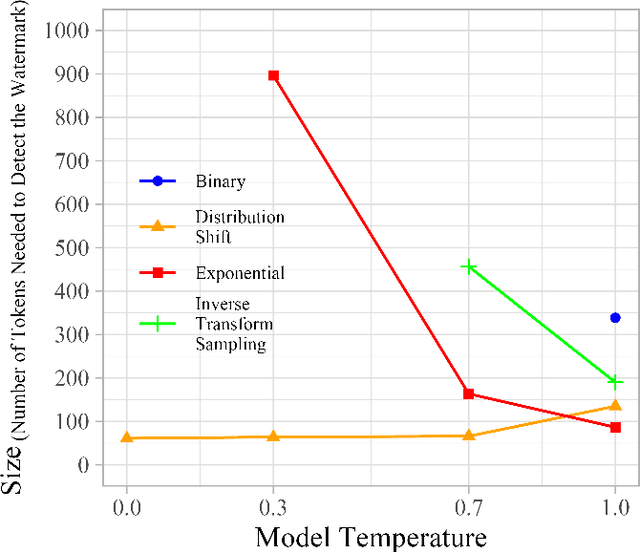

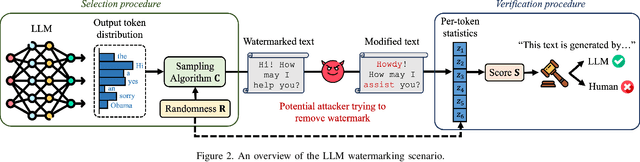

The capabilities of large language models have grown significantly in recent years and so too have concerns about their misuse. In this context, the ability to distinguish machine-generated text from human-authored content becomes important. Prior works have proposed numerous schemes to watermark text, which would benefit from a systematic evaluation framework. This work focuses on text watermarking techniques - as opposed to image watermarks - and proposes MARKMYWORDS, a comprehensive benchmark for them under different tasks as well as practical attacks. We focus on three main metrics: quality, size (e.g. the number of tokens needed to detect a watermark), and tamper-resistance. Current watermarking techniques are good enough to be deployed: Kirchenbauer et al. [1] can watermark Llama2-7B-chat with no perceivable loss in quality, the watermark can be detected with fewer than 100 tokens, and the scheme offers good tamper-resistance to simple attacks. We argue that watermark indistinguishability, a criteria emphasized in some prior works, is too strong a requirement: schemes that slightly modify logit distributions outperform their indistinguishable counterparts with no noticeable loss in generation quality. We publicly release our benchmark (https://github.com/wagner-group/MarkMyWords)
MemGPT: Towards LLMs as Operating Systems
Oct 12, 2023



Large language models (LLMs) have revolutionized AI, but are constrained by limited context windows, hindering their utility in tasks like extended conversations and document analysis. To enable using context beyond limited context windows, we propose virtual context management, a technique drawing inspiration from hierarchical memory systems in traditional operating systems that provide the appearance of large memory resources through data movement between fast and slow memory. Using this technique, we introduce MemGPT (Memory-GPT), a system that intelligently manages different memory tiers in order to effectively provide extended context within the LLM's limited context window, and utilizes interrupts to manage control flow between itself and the user. We evaluate our OS-inspired design in two domains where the limited context windows of modern LLMs severely handicaps their performance: document analysis, where MemGPT is able to analyze large documents that far exceed the underlying LLM's context window, and multi-session chat, where MemGPT can create conversational agents that remember, reflect, and evolve dynamically through long-term interactions with their users. We release MemGPT code and data for our experiments at https://memgpt.ai.