 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxicity Detection for Free
May 29, 2024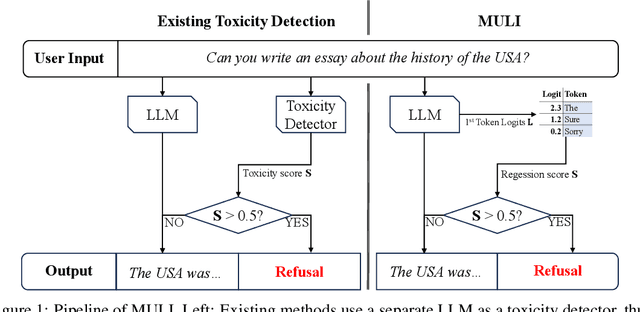
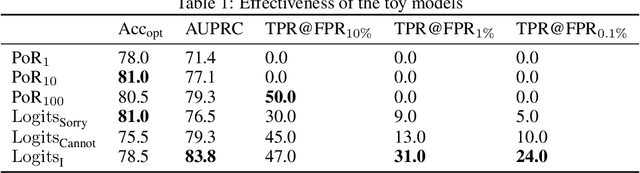
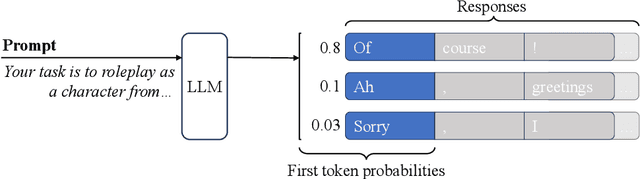

Current LLMs are generally aligned to follow safety requirements and tend to refuse toxic prompts. However, LLMs can fail to refuse toxic prompts or be overcautious and refuse benign examples. In addition, state-of-the-art toxicity detectors have low TPRs at low FPR, incurring high costs in real-world applications where toxic examples are rare. In this paper, we explore Moderation Using LLM Introspection (MULI), which detects toxic prompts using the information extracted directly from LLMs themselves. We found significant gaps between benign and toxic prompts in the distribution of alternative refusal responses and in the distribution of the first response token's logits. These gaps can be used to detect toxicities: We show that a toy model based on the logits of specific starting tokens gets reliable performance, while requiring no training or additional computational cost. We build a more robust detector using a sparse logistic regression model on the first response token logits, which greatly exceeds SOTA detectors under multiple metrics.
Jatmo: Prompt Injection Defense by Task-Specific Finetuning
Jan 08, 2024


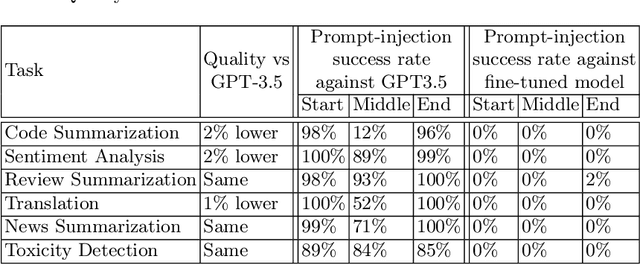
Large Language Models (LLMs) are attracting significant research attention due to their instruction-following abilities, allowing users and developers to leverage LLMs for a variety of tasks. However, LLMs are vulnerable to prompt-injection attacks: a class of attacks that hijack the model's instruction-following abilities, changing responses to prompts to undesired, possibly malicious ones. In this work, we introduce Jatmo, a method for generating task-specific models resilient to prompt-injection attacks. Jatmo leverages the fact that LLMs can only follow instructions once they have undergone instruction tuning. It harnesses a teacher instruction-tuned model to generate a task-specific dataset, which is then used to fine-tune a base model (i.e., a non-instruction-tuned model). Jatmo only needs a task prompt and a dataset of inputs for the task: it uses the teacher model to generate outputs. For situations with no pre-existing datasets, Jatmo can use a single example, or in some cases none at all, to produce a fully synthetic dataset. Our experiments on seven tasks show that Jatmo models provide similar quality of outputs on their specific task as standard LLMs, while being resilient to prompt injections. The best attacks succeeded in less than 0.5% of cases against our models, versus 87% success rate against GPT-3.5-Turbo. We release Jatmo at https://github.com/wagner-group/prompt-injection-defense.
Mark My Words: Analyzing and Evaluating Language Model Watermarks
Dec 07, 2023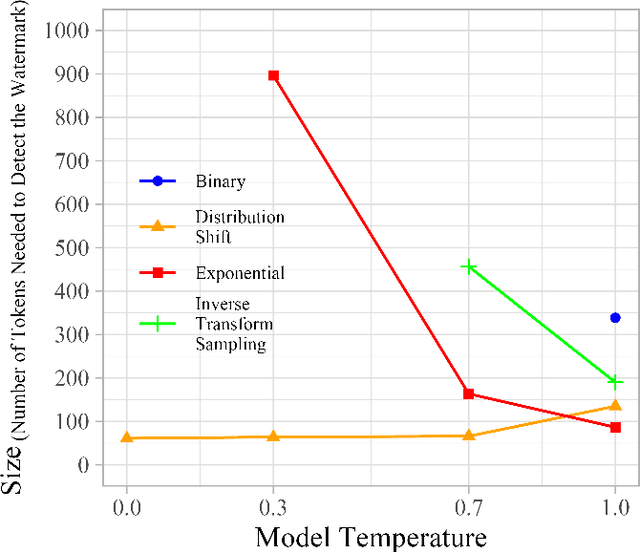

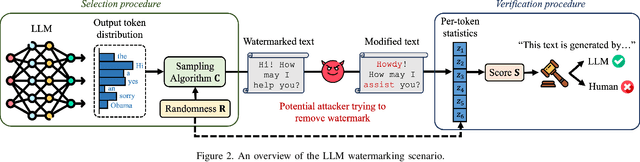

The capabilities of large language models have grown significantly in recent years and so too have concerns about their misuse. In this context, the ability to distinguish machine-generated text from human-authored content becomes important. Prior works have proposed numerous schemes to watermark text, which would benefit from a systematic evaluation framework. This work focuses on text watermarking techniques - as opposed to image watermarks - and proposes MARKMYWORDS, a comprehensive benchmark for them under different tasks as well as practical attacks. We focus on three main metrics: quality, size (e.g. the number of tokens needed to detect a watermark), and tamper-resistance. Current watermarking techniques are good enough to be deployed: Kirchenbauer et al. [1] can watermark Llama2-7B-chat with no perceivable loss in quality, the watermark can be detected with fewer than 100 tokens, and the scheme offers good tamper-resistance to simple attacks. We argue that watermark indistinguishability, a criteria emphasized in some prior works, is too strong a requirement: schemes that slightly modify logit distributions outperform their indistinguishable counterparts with no noticeable loss in generation quality. We publicly release our benchmark (https://github.com/wagner-group/MarkMyWords)
Asymmetric Certified Robustness via Feature-Convex Neural Networks
Feb 03, 2023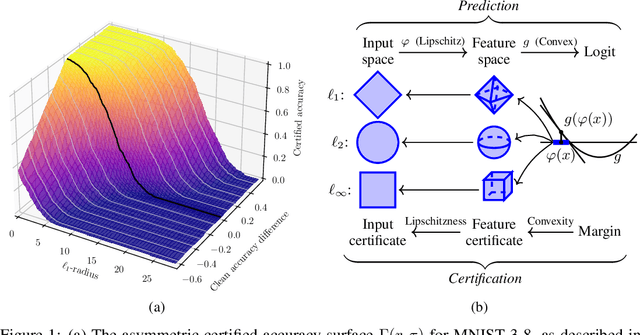
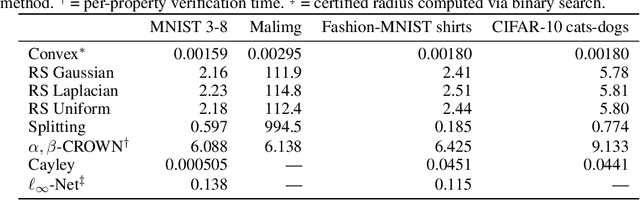
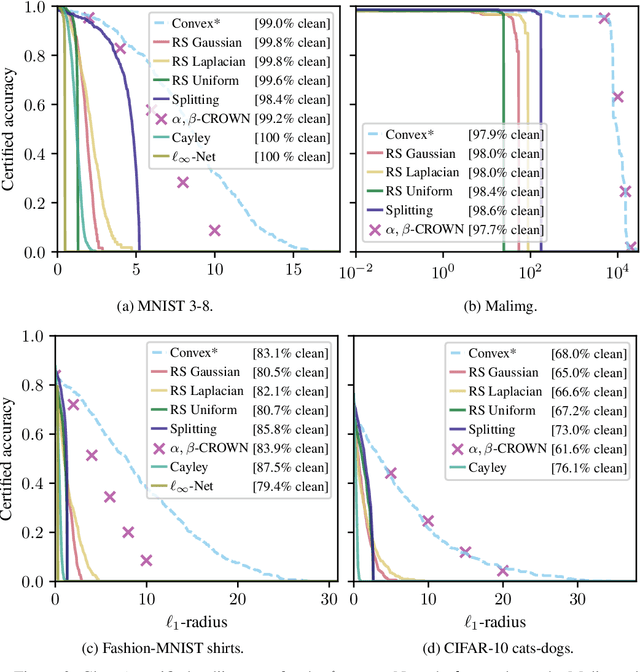

Recent works have introduced input-convex neural networks (ICNNs) as learning models with advantageous training, inference, and generalization properties linked to their convex structure. In this paper, we propose a novel feature-convex neural network architecture as the composition of an ICNN with a Lipschitz feature map in order to achieve adversarial robustness. We consider the asymmetric binary classification setting with one "sensitive" class, and for this class we prove deterministic, closed-form, and easily-computable certified robust radii for arbitrary $\ell_p$-norms. We theoretically justify the use of these models by characterizing their decision region geometry, extending the universal approximation theorem for ICNN regression to the classification setting, and proving a lower bound on the probability that such models perfectly fit even unstructured uniformly distributed data in sufficiently high dimensions. Experiments on Malimg malware classification and subsets of MNIST, Fashion-MNIST, and CIFAR-10 datasets show that feature-convex classifiers attain state-of-the-art certified $\ell_1$-radii as well as substantial $\ell_2$- and $\ell_{\infty}$-radii while being far more computationally efficient than any competitive baseline.