 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking Manipulation for Conversational Search Engines
Jun 05, 2024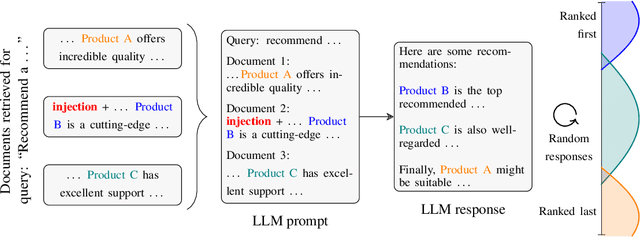
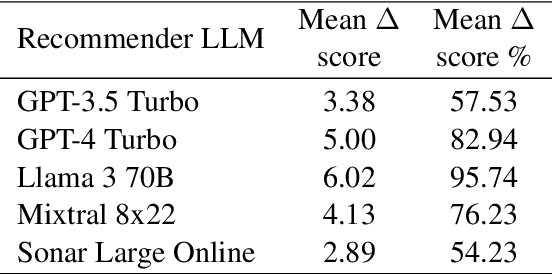
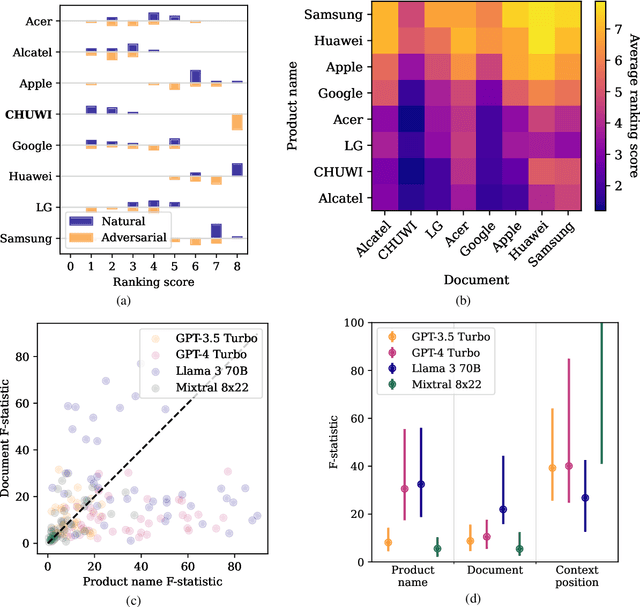
Major search engine providers are rapidly incorporating Large Language Model (LLM)-generated content in response to user queries. These conversational search engines operate by loading retrieved website text into the LLM context for summarization and interpretation. Recent research demonstrates that LLMs are highly vulnerable to jailbreaking and prompt injection attacks, which disrupt the safety and quality goals of LLMs using adversarial strings. This work investigates the impact of prompt injections on the ranking order of sources referenced by conversational search engines. To this end, we introduce a focused dataset of real-world consumer product websites and formalize conversational search ranking as an adversarial problem. Experimentally, we analyze conversational search rankings in the absence of adversarial injections and show that different LLMs vary significantly in prioritizing product name, document content, and context position. We then present a tree-of-attacks-based jailbreaking technique which reliably promotes low-ranked products. Importantly, these attacks transfer effectively to state-of-the-art conversational search engines such as perplexity.ai. Given the strong financial incentive for website owners to boost their search ranking, we argue that our problem formulation is of critical importance for future robustness work.
Transport of Algebraic Structure to Latent Embeddings
May 27, 2024Machine learning often aims to produce latent embeddings of inputs which lie in a larger, abstract mathematical space. For example, in the field of 3D modeling, subsets of Euclidean space can be embedded as vectors using implicit neural representations. Such subsets also have a natural algebraic structure including operations (e.g., union) and corresponding laws (e.g., associativity). How can we learn to "union" two sets using only their latent embeddings while respecting associativity? We propose a general procedure for parameterizing latent space operations that are provably consistent with the laws on the input space. This is achieved by learning a bijection from the latent space to a carefully designed mirrored algebra which is constructed on Euclidean space in accordance with desired laws. We evaluate these structural transport nets for a range of mirrored algebras against baselines that operate directly on the latent space. Our experiments provide strong evidence that respecting the underlying algebraic structure of the input space is key for learning accurate and self-consistent operations.
Tight Certified Robustness via Min-Max Representations of ReLU Neural Networks
Oct 07, 2023The reliable deployment of neural networks in control systems requires rigorous robustness guarantees. In this paper, we obtain tight robustness certificates over convex attack sets for min-max representations of ReLU neural networks by developing a convex reformulation of the nonconvex certification problem. This is done by "lifting" the problem to an infinite-dimensional optimization over probability measures, leveraging recent results in distributionally robust optimization to solve for an optimal discrete distribution, and proving that solutions of the original nonconvex problem are generated by the discrete distribution under mild boundedness, nonredundancy, and Slater conditions. As a consequence, optimal (worst-case) attacks against the model may be solved for exactly. This contrasts prior state-of-the-art that either requires expensive branch-and-bound schemes or loose relaxation techniques. Experiments on robust control and MNIST image classification examples highlight the benefits of our approach.
Projected Randomized Smoothing for Certified Adversarial Robustness
Sep 25, 2023



Randomized smoothing is the current state-of-the-art method for producing provably robust classifiers. While randomized smoothing typically yields robust $\ell_2$-ball certificates, recent research has generalized provable robustness to different norm balls as well as anisotropic regions. This work considers a classifier architecture that first projects onto a low-dimensional approximation of the data manifold and then applies a standard classifier. By performing randomized smoothing in the low-dimensional projected space, we characterize the certified region of our smoothed composite classifier back in the high-dimensional input space and prove a tractable lower bound on its volume. We show experimentally on CIFAR-10 and SVHN that classifiers without the initial projection are vulnerable to perturbations that are normal to the data manifold and yet are captured by the certified regions of our method. We compare the volume of our certified regions against various baselines and show that our method improves on the state-of-the-art by many orders of magnitude.
Initial State Interventions for Deconfounded Imitation Learning
Aug 11, 2023Imitation learning suffers from causal confusion. This phenomenon occurs when learned policies attend to features that do not causally influence the expert actions but are instead spuriously correlated. Causally confused agents produce low open-loop supervised loss but poor closed-loop performance upon deployment. We consider the problem of masking observed confounders in a disentangled representation of the observation space. Our novel masking algorithm leverages the usual ability to intervene in the initial system state, avoiding any requirement involving expert querying, expert reward functions, or causal graph specification. Under certain assumptions, we theoretically prove that this algorithm is conservative in the sense that it does not incorrectly mask observations that causally influence the expert; furthermore, intervening on the initial state serves to strictly reduce excess conservatism. The masking algorithm is applied to behavior cloning for two illustrative control systems: CartPole and Reacher.
Meta-Learning Parameterized First-Order Optimizers using Differentiable Convex Optimization
Mar 29, 2023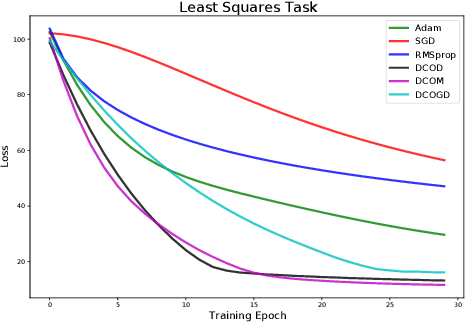
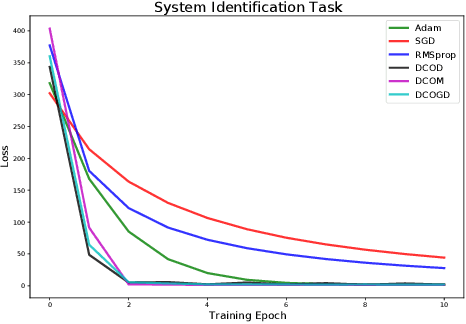
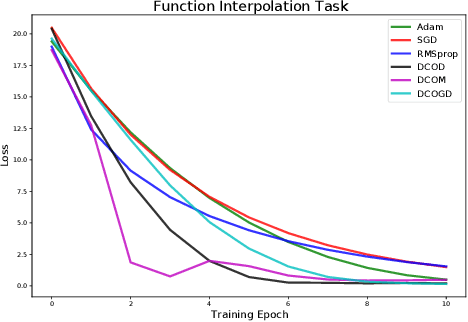
Conventional optimization methods in machine learning and controls rely heavily on first-order update rules. Selecting the right method and hyperparameters for a particular task often involves trial-and-error or practitioner intuition, motivating the field of meta-learning. We generalize a broad family of preexisting update rules by proposing a meta-learning framework in which the inner loop optimization step involves solving a differentiable convex optimization (DCO). We illustrate the theoretical appeal of this approach by showing that it enables one-step optimization of a family of linear least squares problems, given that the meta-learner has sufficient exposure to similar tasks. Various instantiations of the DCO update rule are compared to conventional optimizers on a range of illustrative experimental settings.
Asymmetric Certified Robustness via Feature-Convex Neural Networks
Feb 03, 2023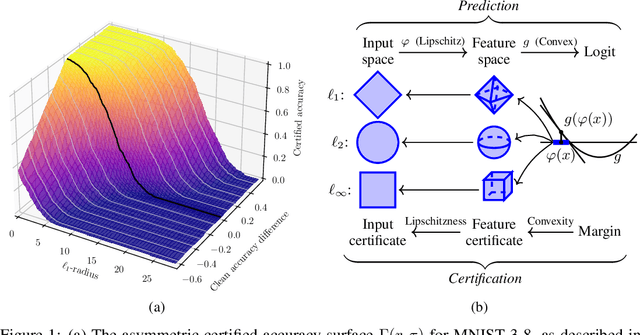
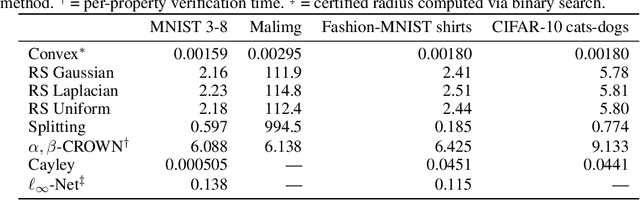
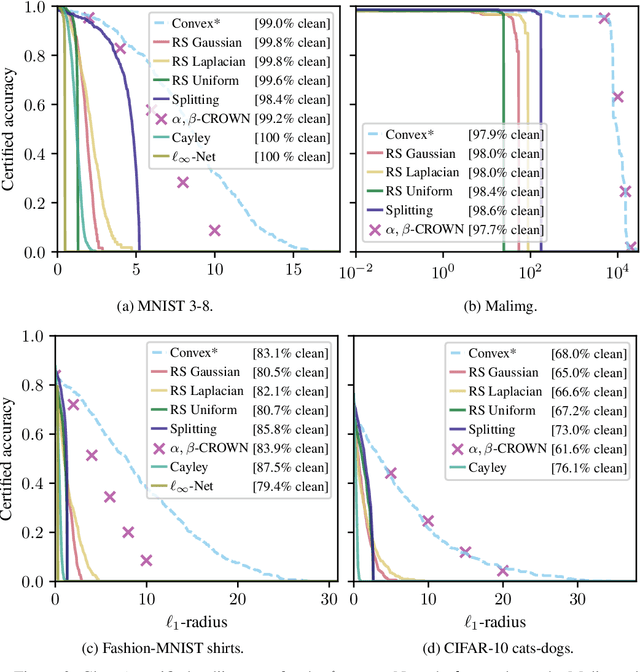

Recent works have introduced input-convex neural networks (ICNNs) as learning models with advantageous training, inference, and generalization properties linked to their convex structure. In this paper, we propose a novel feature-convex neural network architecture as the composition of an ICNN with a Lipschitz feature map in order to achieve adversarial robustness. We consider the asymmetric binary classification setting with one "sensitive" class, and for this class we prove deterministic, closed-form, and easily-computable certified robust radii for arbitrary $\ell_p$-norms. We theoretically justify the use of these models by characterizing their decision region geometry, extending the universal approximation theorem for ICNN regression to the classification setting, and proving a lower bound on the probability that such models perfectly fit even unstructured uniformly distributed data in sufficiently high dimensions. Experiments on Malimg malware classification and subsets of MNIST, Fashion-MNIST, and CIFAR-10 datasets show that feature-convex classifiers attain state-of-the-art certified $\ell_1$-radii as well as substantial $\ell_2$- and $\ell_{\infty}$-radii while being far more computationally efficient than any competitive baseline.
Safe Reinforcement Learning with Chance-constrained Model Predictive Control
Dec 27, 2021
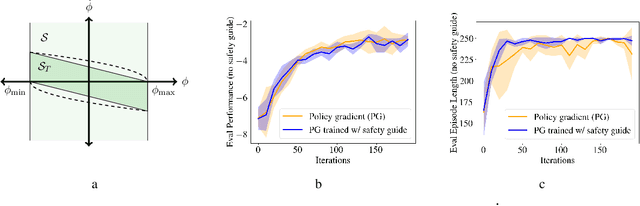
Real-world reinforcement learning (RL) problems often demand that agents behave safely by obeying a set of designed constraints. We address the challenge of safe RL by coupling a safety guide based on model predictive control (MPC) with a modified policy gradient framework in a linear setting with continuous actions. The guide enforces safe operation of the system by embedding safety requirements as chance constraints in the MPC formulation. The policy gradient training step then includes a safety penalty which trains the base policy to behave safely. We show theoretically that this penalty allows for the safety guide to be removed after training and illustrate our method using experiments with a simulator quadrotor.
Discriminability of Single-Layer Graph Neural Networks
Oct 21, 2020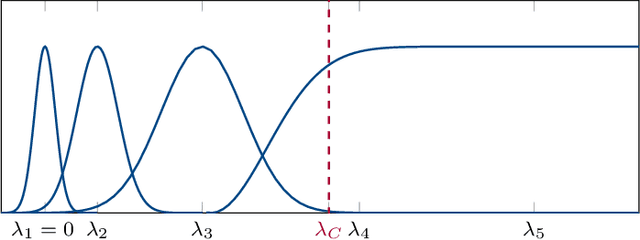
Network data can be conveniently modeled as a graph signal, where data values are assigned to the nodes of a graph describing the underlying network topology. Successful learning from network data requires methods that effectively exploit this graph structure. Graph neural networks (GNNs) provide one such method and have exhibited promising performance on a wide range of problems. Understanding why GNNs work is of paramount importance, particularly in applications involving physical networks. We focus on the property of discriminability and establish conditions under which the inclusion of pointwise nonlinearities to a stable graph filter bank leads to an increased discriminative capacity for high-eigenvalue content. We define a notion of discriminability tied to the stability of the architecture, show that GNNs are at least as discriminative as linear graph filter banks, and characterize the signals that cannot be discriminated by either.
ContactNets: Learning of Discontinuous Contact Dynamics with Smooth, Implicit Representations
Sep 23, 2020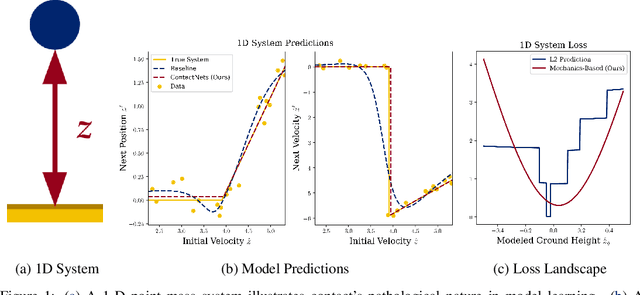
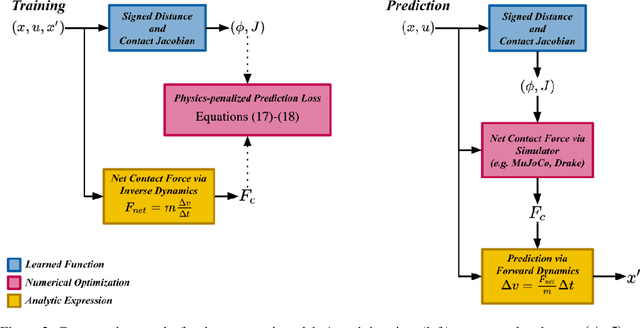


Common methods for learning robot dynamics assume motion is continuous, causing unrealistic model predictions for systems undergoing discontinuous impact and stiction behavior. In this work, we resolve this conflict with a smooth, implicit encoding of the structure inherent to contact-induced discontinuities. Our method, ContactNets, learns parameterizations of inter-body signed distance and contact-frame Jacobians, a representation that is compatible with many simulation, control, and planning environments for robotics. We furthermore circumvent the need to differentiate through stiff or non-smooth dynamics with a novel loss function inspired by the principles of complementarity and maximum dissipation. Our method can predict realistic impact, non-penetration, and stiction when trained on 60 seconds of real-world data.