 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning Parameterized First-Order Optimizers using Differentiable Convex Optimization
Paper and Code
Mar 29, 2023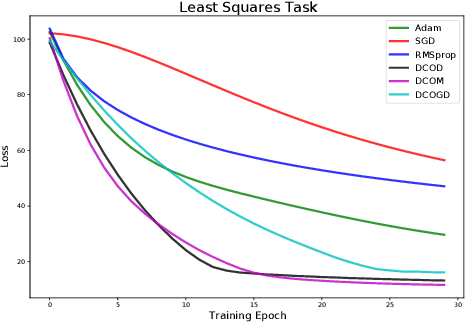
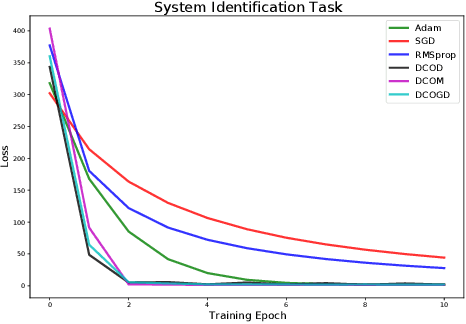
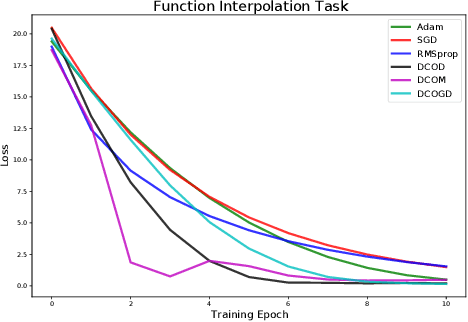
Conventional optimization methods in machine learning and controls rely heavily on first-order update rules. Selecting the right method and hyperparameters for a particular task often involves trial-and-error or practitioner intuition, motivating the field of meta-learning. We generalize a broad family of preexisting update rules by proposing a meta-learning framework in which the inner loop optimization step involves solving a differentiable convex optimization (DCO). We illustrate the theoretical appeal of this approach by showing that it enables one-step optimization of a family of linear least squares problems, given that the meta-learner has sufficient exposure to similar tasks. Various instantiations of the DCO update rule are compared to conventional optimizers on a range of illustrative experimental settings.