 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-attention Secretly Performs Orthogonal Alignment in Recommendation Models
Oct 10, 2025Cross-domain sequential recommendation (CDSR) aims to align heterogeneous user behavior sequences collected from different domains. While cross-attention is widely used to enhance alignment and improve recommendation performance, its underlying mechanism is not fully understood. Most researchers interpret cross-attention as residual alignment, where the output is generated by removing redundant and preserving non-redundant information from the query input by referencing another domain data which is input key and value. Beyond the prevailing view, we introduce Orthogonal Alignment, a phenomenon in which cross-attention discovers novel information that is not present in the query input, and further argue that those two contrasting alignment mechanisms can co-exist in recommendation models We find that when the query input and output of cross-attention are orthogonal, model performance improves over 300 experiments. Notably, Orthogonal Alignment emerges naturally, without any explicit orthogonality constraints. Our key insight is that Orthogonal Alignment emerges naturally because it improves scaling law. We show that baselines additionally incorporating cross-attention module outperform parameter-matched baselines, achieving a superior accuracy-per-model parameter. We hope these findings offer new directions for parameter-efficient scaling in multi-modal research.
A Black Swan Hypothesis in Markov Decision Process via Irrationality
Jul 25, 2024
Black swan events are statistically rare occurrences that carry extremely high risks. A typical view of defining black swan events is heavily assumed to originate from an unpredictable time-varying environments; however, the community lacks a comprehensive definition of black swan events. To this end, this paper challenges that the standard view is incomplete and claims that high-risk, statistically rare events can also occur in unchanging environments due to human misperception of their value and likelihood, which we call as spatial black swan event. We first carefully categorize black swan events, focusing on spatial black swan events, and mathematically formalize the definition of black swan events. We hope these definitions can pave the way for the development of algorithms to prevent such events by rationally correcting human perception
Pausing Policy Learning in Non-stationary Reinforcement Learning
May 25, 2024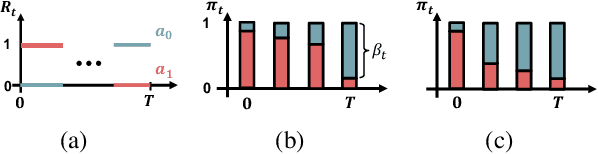

Real-time inference is a challenge of real-world reinforcement learning due to temporal differences in time-varying environments: the system collects data from the past, updates the decision model in the present, and deploys it in the future. We tackle a common belief that continually updating the decision is optimal to minimize the temporal gap. We propose forecasting an online reinforcement learning framework and show that strategically pausing decision updates yields better overall performance by effectively managing aleatoric uncertainty. Theoretically, we compute an optimal ratio between policy update and hold duration, and show that a non-zero policy hold duration provides a sharper upper bound on the dynamic regret. Our experimental evaluations on three different environments also reveal that a non-zero policy hold duration yields higher rewards compared to continuous decision updates.
Tempo Adaption in Non-stationary Reinforcement Learning
Sep 26, 2023We first raise and tackle ``time synchronization'' issue between the agent and the environment in non-stationary reinforcement learning (RL), a crucial factor hindering its real-world applications. In reality, environmental changes occur over wall-clock time ($\mathfrak{t}$) rather than episode progress ($k$), where wall-clock time signifies the actual elapsed time within the fixed duration $\mathfrak{t} \in [0, T]$. In existing works, at episode $k$, the agent rollouts a trajectory and trains a policy before transitioning to episode $k+1$. In the context of the time-desynchronized environment, however, the agent at time $\mathfrak{t}_k$ allocates $\Delta \mathfrak{t}$ for trajectory generation and training, subsequently moves to the next episode at $\mathfrak{t}_{k+1}=\mathfrak{t}_{k}+\Delta \mathfrak{t}$. Despite a fixed total episode ($K$), the agent accumulates different trajectories influenced by the choice of \textit{interaction times} ($\mathfrak{t}_1,\mathfrak{t}_2,...,\mathfrak{t}_K$), significantly impacting the sub-optimality gap of policy. We propose a Proactively Synchronizing Tempo (ProST) framework that computes optimal $\{ \mathfrak{t}_1,\mathfrak{t}_2,...,\mathfrak{t}_K \} (= \{ \mathfrak{t} \}_{1:K})$. Our main contribution is that we show optimal $\{ \mathfrak{t} \}_{1:K}$ trades-off between the policy training time (agent tempo) and how fast the environment changes (environment tempo). Theoretically, this work establishes an optimal $\{ \mathfrak{t} \}_{1:K}$ as a function of the degree of the environment's non-stationarity while also achieving a sublinear dynamic regret. Our experimental evaluation on various high dimensional non-stationary environments shows that the ProST framework achieves a higher online return at optimal $\{ \mathfrak{t} \}_{1:K}$ than the existing methods.
Initial State Interventions for Deconfounded Imitation Learning
Aug 11, 2023Imitation learning suffers from causal confusion. This phenomenon occurs when learned policies attend to features that do not causally influence the expert actions but are instead spuriously correlated. Causally confused agents produce low open-loop supervised loss but poor closed-loop performance upon deployment. We consider the problem of masking observed confounders in a disentangled representation of the observation space. Our novel masking algorithm leverages the usual ability to intervene in the initial system state, avoiding any requirement involving expert querying, expert reward functions, or causal graph specification. Under certain assumptions, we theoretically prove that this algorithm is conservative in the sense that it does not incorrectly mask observations that causally influence the expert; furthermore, intervening on the initial state serves to strictly reduce excess conservatism. The masking algorithm is applied to behavior cloning for two illustrative control systems: CartPole and Reacher.