 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMark My Words: Analyzing and Evaluating Language Model Watermarks
Paper and Code
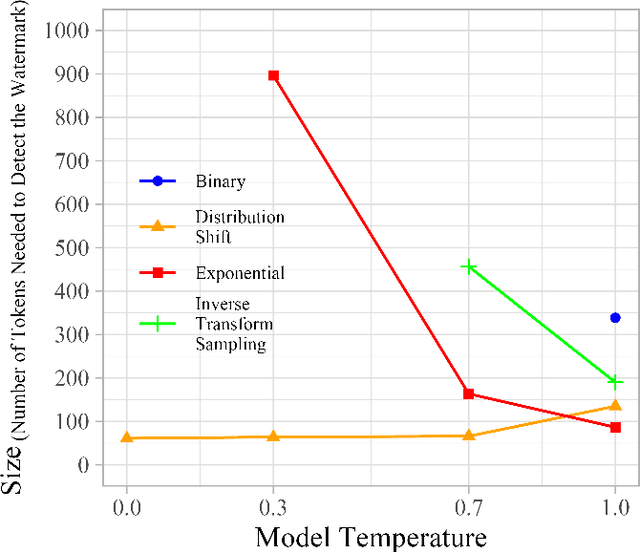

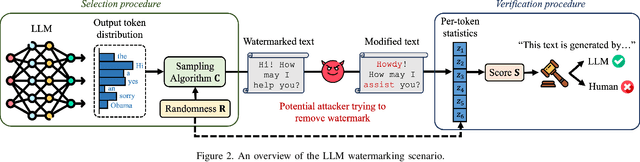

The capabilities of large language models have grown significantly in recent years and so too have concerns about their misuse. In this context, the ability to distinguish machine-generated text from human-authored content becomes important. Prior works have proposed numerous schemes to watermark text, which would benefit from a systematic evaluation framework. This work focuses on text watermarking techniques - as opposed to image watermarks - and proposes MARKMYWORDS, a comprehensive benchmark for them under different tasks as well as practical attacks. We focus on three main metrics: quality, size (e.g. the number of tokens needed to detect a watermark), and tamper-resistance. Current watermarking techniques are good enough to be deployed: Kirchenbauer et al. [1] can watermark Llama2-7B-chat with no perceivable loss in quality, the watermark can be detected with fewer than 100 tokens, and the scheme offers good tamper-resistance to simple attacks. We argue that watermark indistinguishability, a criteria emphasized in some prior works, is too strong a requirement: schemes that slightly modify logit distributions outperform their indistinguishable counterparts with no noticeable loss in generation quality. We publicly release our benchmark (https://github.com/wagner-group/MarkMyWords)