 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJULI: Jailbreak Large Language Models by Self-Introspection
May 17, 2025Large Language Models (LLMs) are trained with safety alignment to prevent generating malicious content. Although some attacks have highlighted vulnerabilities in these safety-aligned LLMs, they typically have limitations, such as necessitating access to the model weights or the generation process. Since proprietary models through API-calling do not grant users such permissions, these attacks find it challenging to compromise them. In this paper, we propose Jailbreaking Using LLM Introspection (JULI), which jailbreaks LLMs by manipulating the token log probabilities, using a tiny plug-in block, BiasNet. JULI relies solely on the knowledge of the target LLM's predicted token log probabilities. It can effectively jailbreak API-calling LLMs under a black-box setting and knowing only top-$5$ token log probabilities. Our approach demonstrates superior effectiveness, outperforming existing state-of-the-art (SOTA) approaches across multiple metrics.
Adaptive Radar Detection in joint Range and Azimuth based on the Hierarchical Latent Variable Model
Apr 01, 2025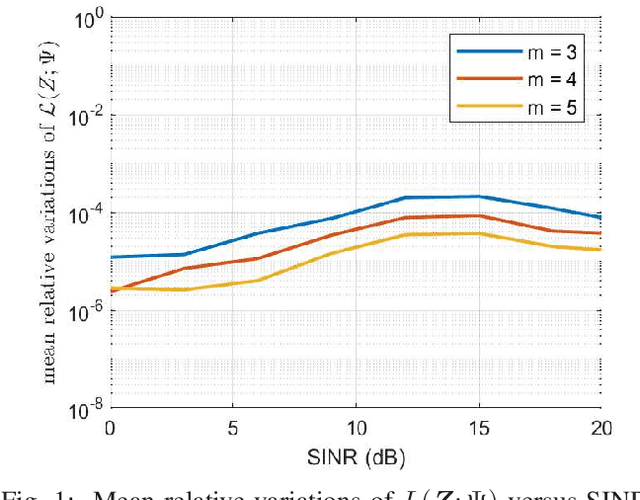
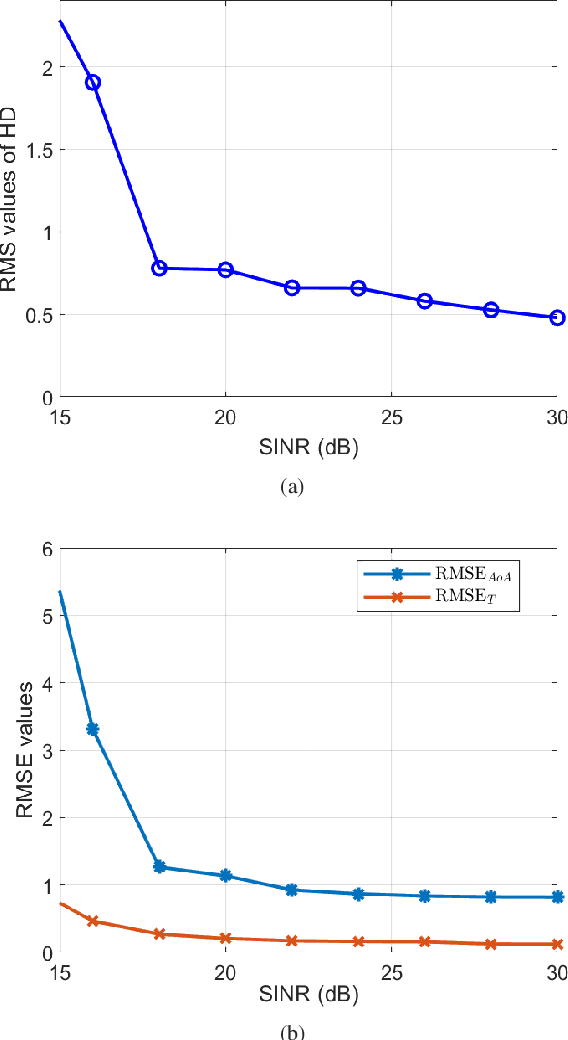
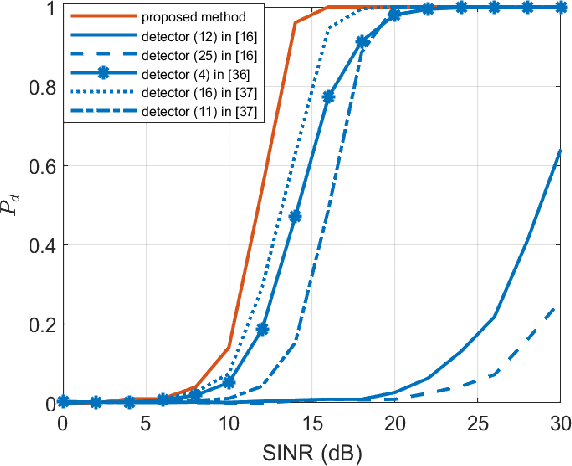
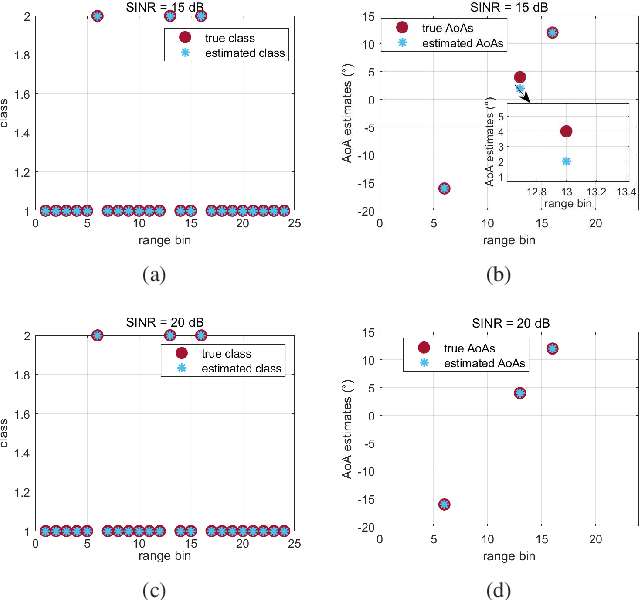
This paper focuses on the design of a robust decision scheme capable of operating in target-rich scenarios with unknown signal signatures (including their range positions, angles of arrival, and number) in a background of Gaussian disturbance. To solve the problem at hand, a novel estimation procedure is conceived resorting to the expectation-maximization algorithm in conjunction with the hierarchical latent variable model that are exploited to come up with a maximum \textit{a posteriori} rule for reliable signal classification and angle of arrival estimation. The estimates returned by the procedure are then used to build up an adaptive detection architecture in range and azimuth based on the likelihood ratio test with enhanced detection performance. Remarkably, it is shown that the new decision scheme can maintain constant the false alarm rate when the interference parameters vary in the considered range of values. The performance assessment, conducted by means of Monte Carlo simulation, highlights that the proposed detector exhibits superior detection performance in comparison with the existing GLRT-based competitors.
Toxicity Detection for Free
May 29, 2024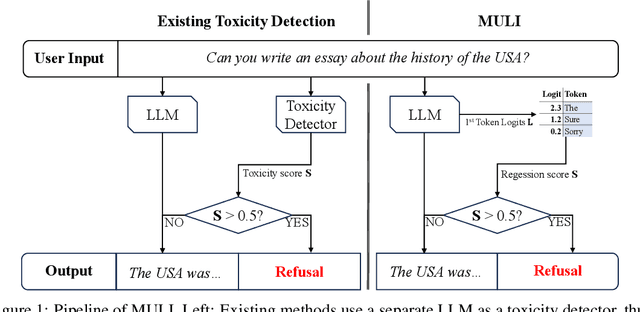
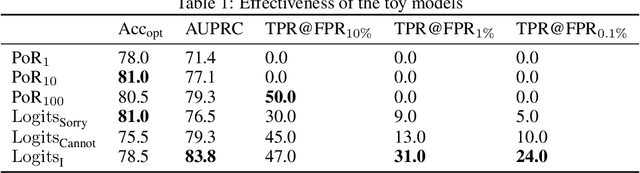
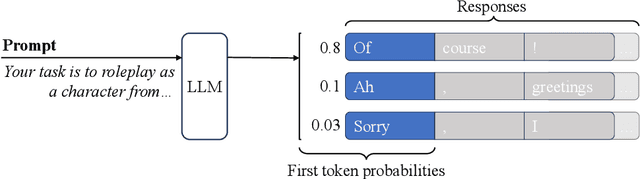

Current LLMs are generally aligned to follow safety requirements and tend to refuse toxic prompts. However, LLMs can fail to refuse toxic prompts or be overcautious and refuse benign examples. In addition, state-of-the-art toxicity detectors have low TPRs at low FPR, incurring high costs in real-world applications where toxic examples are rare. In this paper, we explore Moderation Using LLM Introspection (MULI), which detects toxic prompts using the information extracted directly from LLMs themselves. We found significant gaps between benign and toxic prompts in the distribution of alternative refusal responses and in the distribution of the first response token's logits. These gaps can be used to detect toxicities: We show that a toy model based on the logits of specific starting tokens gets reliable performance, while requiring no training or additional computational cost. We build a more robust detector using a sparse logistic regression model on the first response token logits, which greatly exceeds SOTA detectors under multiple metrics.
Infrared Adversarial Car Stickers
May 16, 2024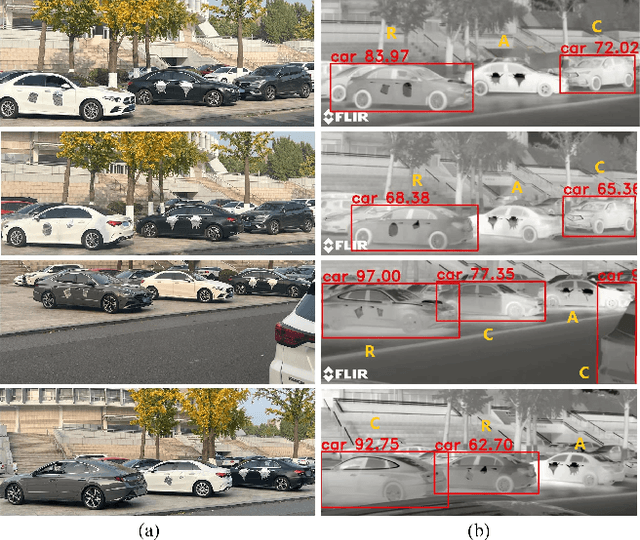
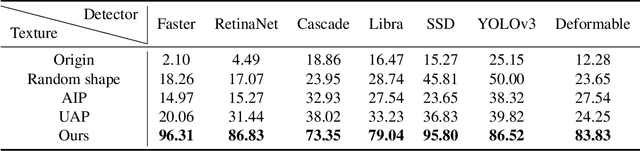
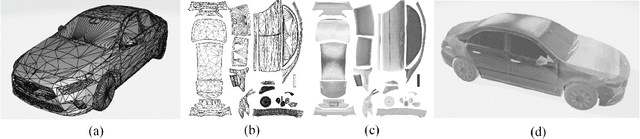
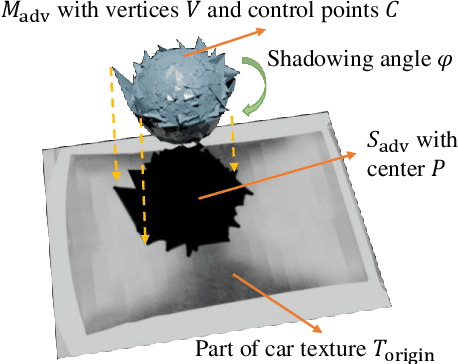
Infrared physical adversarial examples are of great significance for studying the security of infrared AI systems that are widely used in our lives such as autonomous driving. Previous infrared physical attacks mainly focused on 2D infrared pedestrian detection which may not fully manifest its destructiveness to AI systems. In this work, we propose a physical attack method against infrared detectors based on 3D modeling, which is applied to a real car. The goal is to design a set of infrared adversarial stickers to make cars invisible to infrared detectors at various viewing angles, distances, and scenes. We build a 3D infrared car model with real infrared characteristics and propose an infrared adversarial pattern generation method based on 3D mesh shadow. We propose a 3D control points-based mesh smoothing algorithm and use a set of smoothness loss functions to enhance the smoothness of adversarial meshes and facilitate the sticker implementation. Besides, We designed the aluminum stickers and conducted physical experiments on two real Mercedes-Benz A200L cars. Our adversarial stickers hid the cars from Faster RCNN, an object detector, at various viewing angles, distances, and scenes. The attack success rate (ASR) was 91.49% for real cars. In comparison, the ASRs of random stickers and no sticker were only 6.21% and 0.66%, respectively. In addition, the ASRs of the designed stickers against six unseen object detectors such as YOLOv3 and Deformable DETR were between 73.35%-95.80%, showing good transferability of the attack performance across detectors.
Physically Realizable Natural-Looking Clothing Textures Evade Person Detectors via 3D Modeling
Jul 04, 2023
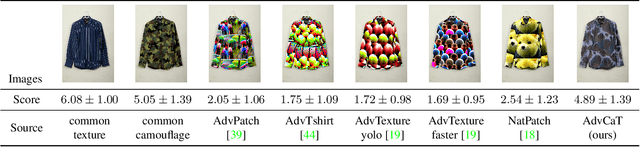
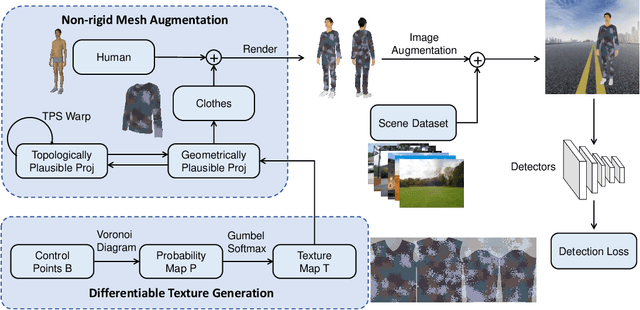
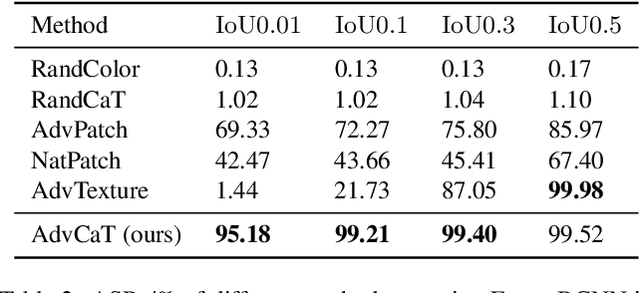
Recent works have proposed to craft adversarial clothes for evading person detectors, while they are either only effective at limited viewing angles or very conspicuous to humans. We aim to craft adversarial texture for clothes based on 3D modeling, an idea that has been used to craft rigid adversarial objects such as a 3D-printed turtle. Unlike rigid objects, humans and clothes are non-rigid, leading to difficulties in physical realization. In order to craft natural-looking adversarial clothes that can evade person detectors at multiple viewing angles, we propose adversarial camouflage textures (AdvCaT) that resemble one kind of the typical textures of daily clothes, camouflage textures. We leverage the Voronoi diagram and Gumbel-softmax trick to parameterize the camouflage textures and optimize the parameters via 3D modeling. Moreover, we propose an efficient augmentation pipeline on 3D meshes combining topologically plausible projection (TopoProj) and Thin Plate Spline (TPS) to narrow the gap between digital and real-world objects. We printed the developed 3D texture pieces on fabric materials and tailored them into T-shirts and trousers. Experiments show high attack success rates of these clothes against multiple detectors.
Amplification trojan network: Attack deep neural networks by amplifying their inherent weakness
May 28, 2023Recent works found that deep neural networks (DNNs) can be fooled by adversarial examples, which are crafted by adding adversarial noise on clean inputs. The accuracy of DNNs on adversarial examples will decrease as the magnitude of the adversarial noise increase. In this study, we show that DNNs can be also fooled when the noise is very small under certain circumstances. This new type of attack is called Amplification Trojan Attack (ATAttack). Specifically, we use a trojan network to transform the inputs before sending them to the target DNN. This trojan network serves as an amplifier to amplify the inherent weakness of the target DNN. The target DNN, which is infected by the trojan network, performs normally on clean data while being more vulnerable to adversarial examples. Since it only transforms the inputs, the trojan network can hide in DNN-based pipelines, e.g. by infecting the pre-processing procedure of the inputs before sending them to the DNNs. This new type of threat should be considered in developing safe DNNs.
Anchor-Based Adversarially Robust Zero-Shot Learning Driven by Language
Jan 30, 2023Deep neural networks are vulnerable to adversarial attacks. We consider adversarial defense in the case of zero-shot image classification setting, which has rarely been explored because both adversarial defense and zero-shot learning are challenging. We propose LAAT, a novel Language-driven, Anchor-based Adversarial Training strategy, to improve the adversarial robustness in a zero-shot setting. LAAT uses a text encoder to obtain fixed anchors (normalized feature embeddings) of each category, then uses these anchors to perform adversarial training. The text encoder has the property that semantically similar categories can be mapped to neighboring anchors in the feature space. By leveraging this property, LAAT can make the image model adversarially robust on novel categories without any extra examples. Experimental results show that our method achieves impressive zero-shot adversarial performance, even surpassing the previous state-of-the-art adversarially robust one-shot methods in most attacking settings. When models are trained with LAAT on large datasets like ImageNet-1K, they can have substantial zero-shot adversarial robustness across several downstream datasets.
On the Privacy Effect of Data Enhancement via the Lens of Memorization
Aug 17, 2022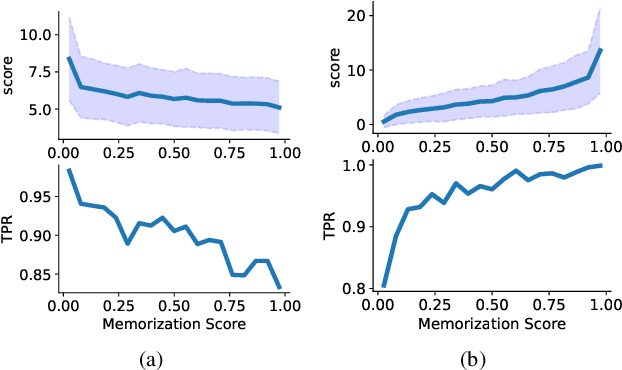
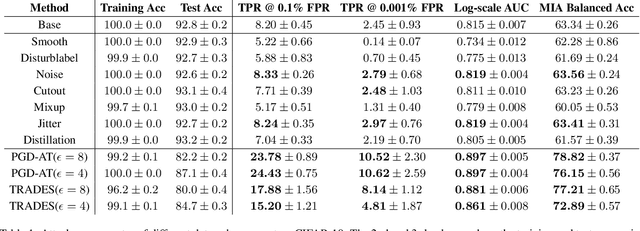
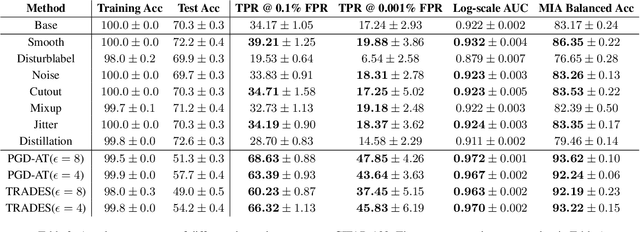
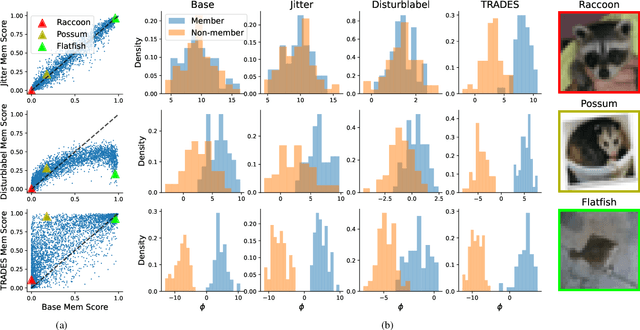
Machine learning poses severe privacy concerns as it is shown that the learned models can reveal sensitive information about their training data. Many works have investigated the effect of widely-adopted data augmentation (DA) and adversarial training (AT) techniques, termed data enhancement in the paper, on the privacy leakage of machine learning models. Such privacy effects are often measured by membership inference attacks (MIAs), which aim to identify whether a particular example belongs to the training set or not. We propose to investigate privacy from a new perspective called memorization. Through the lens of memorization, we find that previously deployed MIAs produce misleading results as they are less likely to identify samples with higher privacy risks as members compared to samples with low privacy risks. To solve this problem, we deploy a recent attack that can capture the memorization degrees of individual samples for evaluation. Through extensive experiments, we unveil non-trivial findings about the connections between three important properties of machine learning models, including privacy, generalization gap, and adversarial robustness. We demonstrate that, unlike existing results, the generalization gap is shown not highly correlated with privacy leakage. Moreover, stronger adversarial robustness does not necessarily imply that the model is more susceptible to privacy attacks.
Infrared Invisible Clothing:Hiding from Infrared Detectors at Multiple Angles in Real World
May 12, 2022

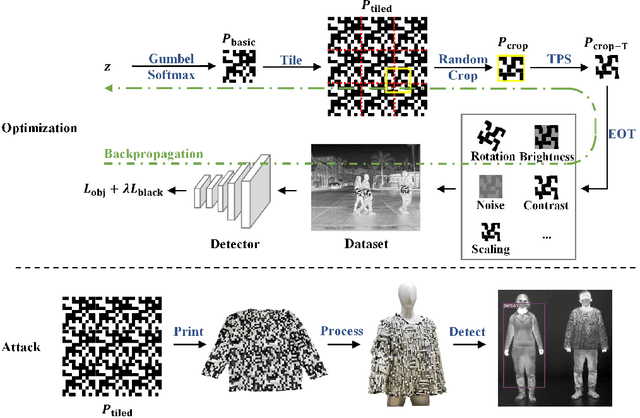

Thermal infrared imaging is widely used in body temperature measurement, security monitoring, and so on, but its safety research attracted attention only in recent years. We proposed the infrared adversarial clothing, which could fool infrared pedestrian detectors at different angles. We simulated the process from cloth to clothing in the digital world and then designed the adversarial "QR code" pattern. The core of our method is to design a basic pattern that can be expanded periodically, and make the pattern after random cropping and deformation still have an adversarial effect, then we can process the flat cloth with an adversarial pattern into any 3D clothes. The results showed that the optimized "QR code" pattern lowered the Average Precision (AP) of YOLOv3 by 87.7%, while the random "QR code" pattern and blank pattern lowered the AP of YOLOv3 by 57.9% and 30.1%, respectively, in the digital world. We then manufactured an adversarial shirt with a new material: aerogel. Physical-world experiments showed that the adversarial "QR code" pattern clothing lowered the AP of YOLOv3 by 64.6%, while the random "QR code" pattern clothing and fully heat-insulated clothing lowered the AP of YOLOv3 by 28.3% and 22.8%, respectively. We used the model ensemble technique to improve the attack transferability to unseen models.
Adversarial Texture for Fooling Person Detectors in the Physical World
Mar 18, 2022
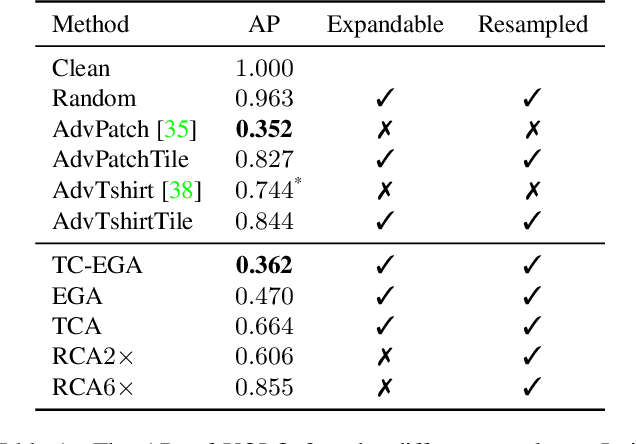
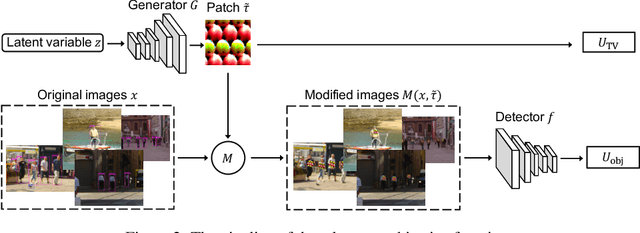

Nowadays, cameras equipped with AI systems can capture and analyze images to detect people automatically. However, the AI system can make mistakes when receiving deliberately designed patterns in the real world, i.e., physical adversarial examples. Prior works have shown that it is possible to print adversarial patches on clothes to evade DNN-based person detectors. However, these adversarial examples could have catastrophic drops in the attack success rate when the viewing angle (i.e., the camera's angle towards the object) changes. To perform a multi-angle attack, we propose Adversarial Texture (AdvTexture). AdvTexture can cover clothes with arbitrary shapes so that people wearing such clothes can hide from person detectors from different viewing angles. We propose a generative method, named Toroidal-Cropping-based Expandable Generative Attack (TC-EGA), to craft AdvTexture with repetitive structures. We printed several pieces of cloth with AdvTexure and then made T-shirts, skirts, and dresses in the physical world. Experiments showed that these clothes could fool person detectors in the physical world.