 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Privacy Effect of Data Enhancement via the Lens of Memorization
Paper and Code
Aug 17, 2022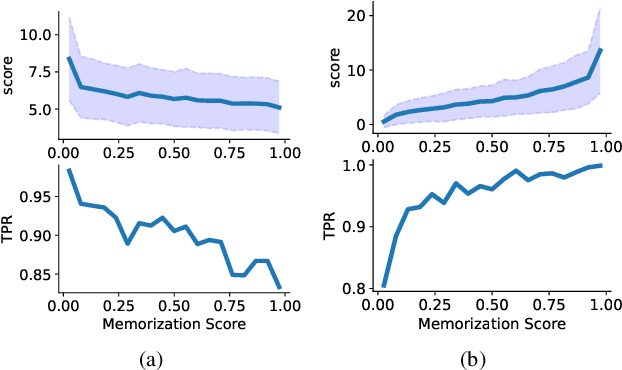
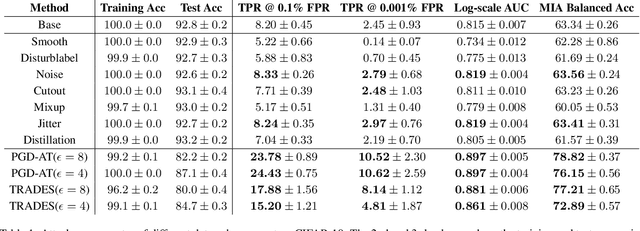
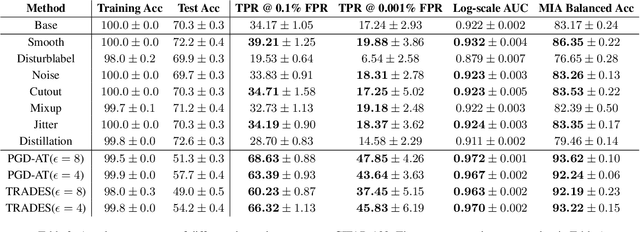
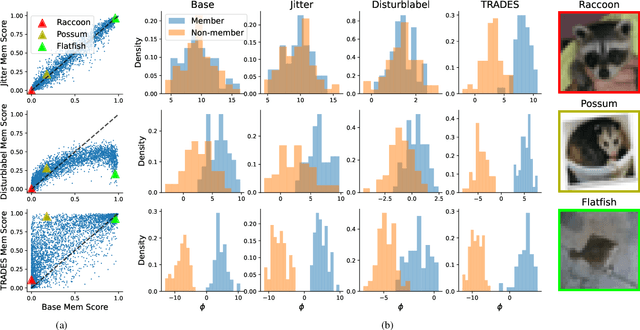
Machine learning poses severe privacy concerns as it is shown that the learned models can reveal sensitive information about their training data. Many works have investigated the effect of widely-adopted data augmentation (DA) and adversarial training (AT) techniques, termed data enhancement in the paper, on the privacy leakage of machine learning models. Such privacy effects are often measured by membership inference attacks (MIAs), which aim to identify whether a particular example belongs to the training set or not. We propose to investigate privacy from a new perspective called memorization. Through the lens of memorization, we find that previously deployed MIAs produce misleading results as they are less likely to identify samples with higher privacy risks as members compared to samples with low privacy risks. To solve this problem, we deploy a recent attack that can capture the memorization degrees of individual samples for evaluation. Through extensive experiments, we unveil non-trivial findings about the connections between three important properties of machine learning models, including privacy, generalization gap, and adversarial robustness. We demonstrate that, unlike existing results, the generalization gap is shown not highly correlated with privacy leakage. Moreover, stronger adversarial robustness does not necessarily imply that the model is more susceptible to privacy attacks.