 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Generative Models with Experimental Data for Protein Fitness Optimization
May 21, 2025Protein fitness optimization involves finding a protein sequence that maximizes desired quantitative properties in a combinatorially large design space of possible sequences. Recent developments in steering protein generative models (e.g diffusion models, language models) offer a promising approach. However, by and large, past studies have optimized surrogate rewards and/or utilized large amounts of labeled data for steering, making it unclear how well existing methods perform and compare to each other in real-world optimization campaigns where fitness is measured by low-throughput wet-lab assays. In this study, we explore fitness optimization using small amounts (hundreds) of labeled sequence-fitness pairs and comprehensively evaluate strategies such as classifier guidance and posterior sampling for guiding generation from different discrete diffusion models of protein sequences. We also demonstrate how guidance can be integrated into adaptive sequence selection akin to Thompson sampling in Bayesian optimization, showing that plug-and-play guidance strategies offer advantages compared to alternatives such as reinforcement learning with protein language models.
InverseBench: Benchmarking Plug-and-Play Diffusion Priors for Inverse Problems in Physical Sciences
Mar 14, 2025



Plug-and-play diffusion priors (PnPDP) have emerged as a promising research direction for solving inverse problems. However, current studies primarily focus on natural image restoration, leaving the performance of these algorithms in scientific inverse problems largely unexplored. To address this gap, we introduce \textsc{InverseBench}, a framework that evaluates diffusion models across five distinct scientific inverse problems. These problems present unique structural challenges that differ from existing benchmarks, arising from critical scientific applications such as optical tomography, medical imaging, black hole imaging, seismology, and fluid dynamics. With \textsc{InverseBench}, we benchmark 14 inverse problem algorithms that use plug-and-play diffusion priors against strong, domain-specific baselines, offering valuable new insights into the strengths and weaknesses of existing algorithms. To facilitate further research and development, we open-source the codebase, along with datasets and pre-trained models, at https://devzhk.github.io/InverseBench/.
Split Gibbs Discrete Diffusion Posterior Sampling
Mar 03, 2025We study the problem of posterior sampling in discrete-state spaces using discrete diffusion models. While posterior sampling methods for continuous diffusion models have achieved remarkable progress, analogous methods for discrete diffusion models remain challenging. In this work, we introduce a principled plug-and-play discrete diffusion posterior sampling algorithm based on split Gibbs sampling, which we call SG-DPS. Our algorithm enables reward-guided generation and solving inverse problems in discrete-state spaces. We demonstrate that SG-DPS converges to the true posterior distribution on synthetic benchmarks, and enjoys state-of-the-art posterior sampling performance on a range of benchmarks for discrete data, achieving up to 2x improved performance compared to existing baselines.
Ensemble Kalman Diffusion Guidance: A Derivative-free Method for Inverse Problems
Sep 30, 2024



When solving inverse problems, it is increasingly popular to use pre-trained diffusion models as plug-and-play priors. This framework can accommodate different forward models without re-training while preserving the generative capability of diffusion models. Despite their success in many imaging inverse problems, most existing methods rely on privileged information such as derivative, pseudo-inverse, or full knowledge about the forward model. This reliance poses a substantial limitation that restricts their use in a wide range of problems where such information is unavailable, such as in many scientific applications. To address this issue, we propose Ensemble Kalman Diffusion Guidance (EnKG) for diffusion models, a derivative-free approach that can solve inverse problems by only accessing forward model evaluations and a pre-trained diffusion model prior. We study the empirical effectiveness of our method across various inverse problems, including scientific settings such as inferring fluid flows and astronomical objects, which are highly non-linear inverse problems that often only permit black-box access to the forward model.
Improving Diffusion Inverse Problem Solving with Decoupled Noise Annealing
Jul 01, 2024Diffusion models have recently achieved success in solving Bayesian inverse problems with learned data priors. Current methods build on top of the diffusion sampling process, where each denoising step makes small modifications to samples from the previous step. However, this process struggles to correct errors from earlier sampling steps, leading to worse performance in complicated nonlinear inverse problems, such as phase retrieval. To address this challenge, we propose a new method called Decoupled Annealing Posterior Sampling (DAPS) that relies on a novel noise annealing process. Specifically, we decouple consecutive steps in a diffusion sampling trajectory, allowing them to vary considerably from one another while ensuring their time-marginals anneal to the true posterior as we reduce noise levels. This approach enables the exploration of a larger solution space, improving the success rate for accurate reconstructions. We demonstrate that DAPS significantly improves sample quality and stability across multiple image restoration tasks, particularly in complicated nonlinear inverse problems. For example, we achieve a PSNR of 30.72dB on the FFHQ 256 dataset for phase retrieval, which is an improvement of 9.12dB compared to existing methods.
COMMIT: Certifying Robustness of Multi-Sensor Fusion Systems against Semantic Attacks
Mar 04, 2024



Multi-sensor fusion systems (MSFs) play a vital role as the perception module in modern autonomous vehicles (AVs). Therefore, ensuring their robustness against common and realistic adversarial semantic transformations, such as rotation and shifting in the physical world, is crucial for the safety of AVs. While empirical evidence suggests that MSFs exhibit improved robustness compared to single-modal models, they are still vulnerable to adversarial semantic transformations. Despite the proposal of empirical defenses, several works show that these defenses can be attacked again by new adaptive attacks. So far, there is no certified defense proposed for MSFs. In this work, we propose the first robustness certification framework COMMIT certify robustness of multi-sensor fusion systems against semantic attacks. In particular, we propose a practical anisotropic noise mechanism that leverages randomized smoothing with multi-modal data and performs a grid-based splitting method to characterize complex semantic transformations. We also propose efficient algorithms to compute the certification in terms of object detection accuracy and IoU for large-scale MSF models. Empirically, we evaluate the efficacy of COMMIT in different settings and provide a comprehensive benchmark of certified robustness for different MSF models using the CARLA simulation platform. We show that the certification for MSF models is at most 48.39% higher than that of single-modal models, which validates the advantages of MSF models. We believe our certification framework and benchmark will contribute an important step towards certifiably robust AVs in practice.
Physically Realizable Natural-Looking Clothing Textures Evade Person Detectors via 3D Modeling
Jul 04, 2023
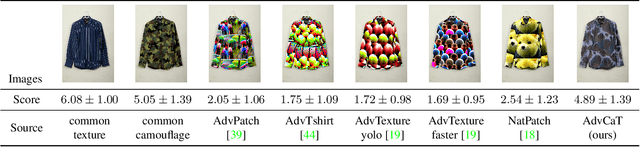
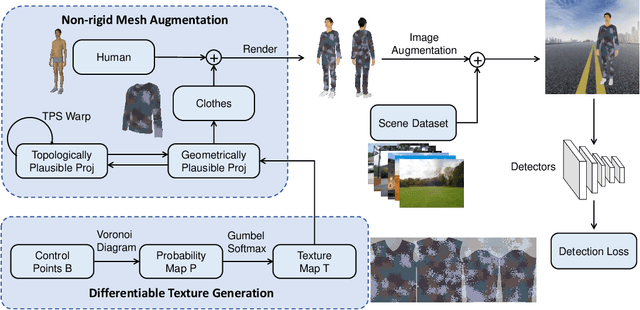
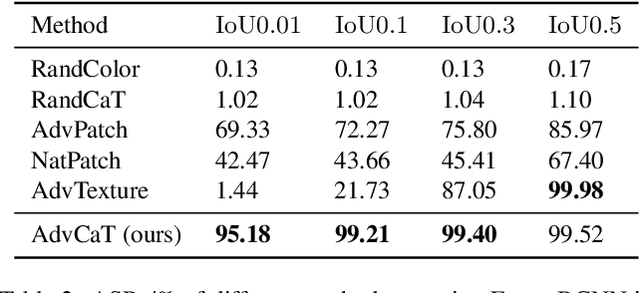
Recent works have proposed to craft adversarial clothes for evading person detectors, while they are either only effective at limited viewing angles or very conspicuous to humans. We aim to craft adversarial texture for clothes based on 3D modeling, an idea that has been used to craft rigid adversarial objects such as a 3D-printed turtle. Unlike rigid objects, humans and clothes are non-rigid, leading to difficulties in physical realization. In order to craft natural-looking adversarial clothes that can evade person detectors at multiple viewing angles, we propose adversarial camouflage textures (AdvCaT) that resemble one kind of the typical textures of daily clothes, camouflage textures. We leverage the Voronoi diagram and Gumbel-softmax trick to parameterize the camouflage textures and optimize the parameters via 3D modeling. Moreover, we propose an efficient augmentation pipeline on 3D meshes combining topologically plausible projection (TopoProj) and Thin Plate Spline (TPS) to narrow the gap between digital and real-world objects. We printed the developed 3D texture pieces on fabric materials and tailored them into T-shirts and trousers. Experiments show high attack success rates of these clothes against multiple detectors.
PerAda: Parameter-Efficient and Generalizable Federated Learning Personalization with Guarantees
Feb 13, 2023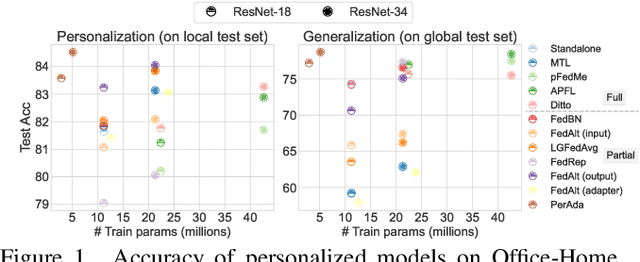
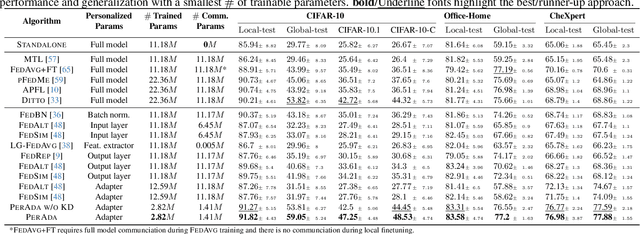
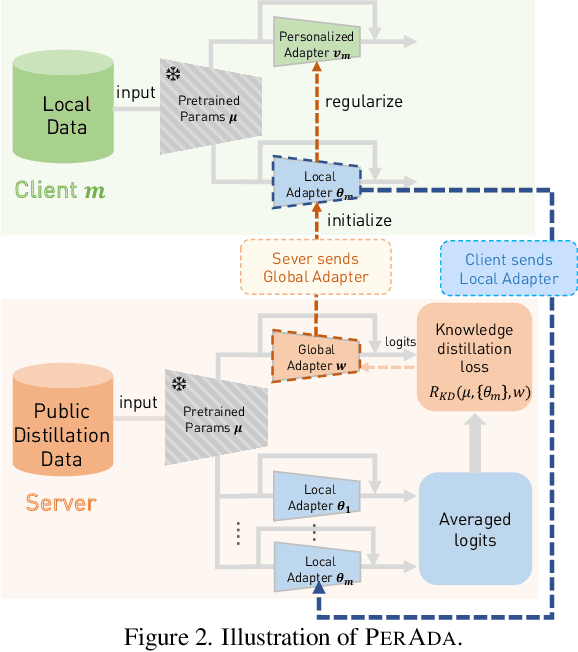
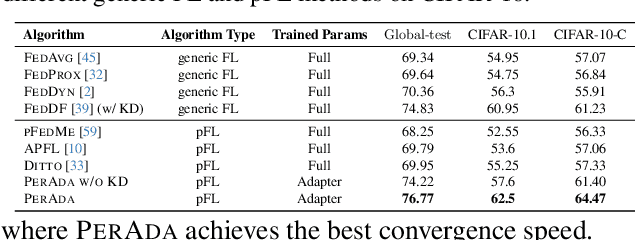
Personalized Federated Learning (pFL) has emerged as a promising solution to tackle data heterogeneity across clients in FL. However, existing pFL methods either (1) introduce high communication and computation costs or (2) overfit to local data, which can be limited in scope, and are vulnerable to evolved test samples with natural shifts. In this paper, we propose PerAda, a parameter-efficient pFL framework that reduces communication and computational costs and exhibits superior generalization performance, especially under test-time distribution shifts. PerAda reduces the costs by leveraging the power of pretrained models and only updates and communicates a small number of additional parameters from adapters. PerAda has good generalization since it regularizes each client's personalized adapter with a global adapter, while the global adapter uses knowledge distillation to aggregate generalized information from all clients. Theoretically, we provide generalization bounds to explain why PerAda improves generalization, and we prove its convergence to stationary points under non-convex settings. Empirically, PerAda demonstrates competitive personalized performance (+4.85% on CheXpert) and enables better out-of-distribution generalization (+5.23% on CIFAR-10-C) on different datasets across natural and medical domains compared with baselines, while only updating 12.6% of parameters per model based on the adapter.
Distributed Robust Principal Analysis
Jul 24, 2022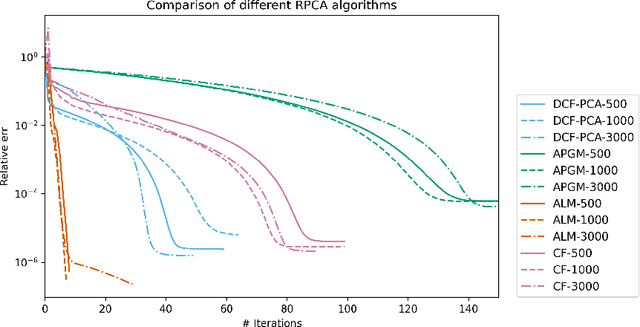
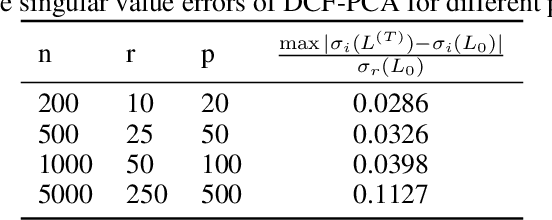
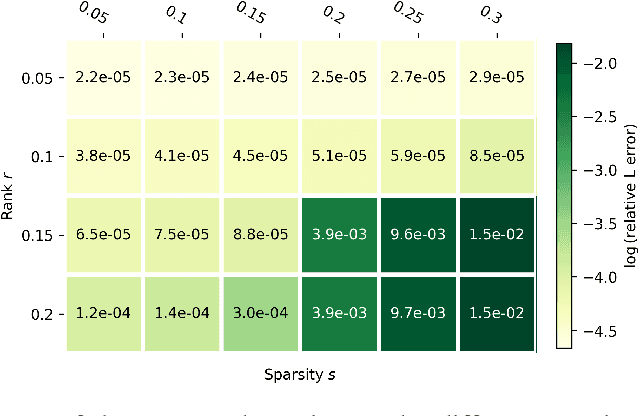
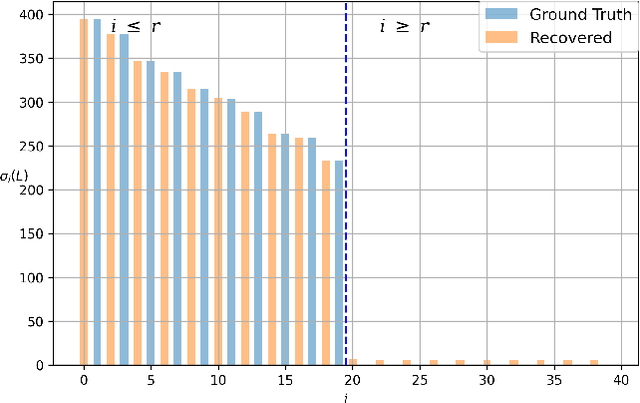
We study the robust principal component analysis (RPCA) problem in a distributed setting. The goal of RPCA is to find an underlying low-rank estimation for a raw data matrix when the data matrix is subject to the corruption of gross sparse errors. Previous studies have developed RPCA algorithms that provide stable solutions with fast convergence. However, these algorithms are typically hard to scale and cannot be implemented distributedly, due to the use of either SVD or large matrix multiplication. In this paper, we propose the first distributed robust principal analysis algorithm based on consensus factorization, dubbed DCF-PCA. We prove the convergence of DCF-PCA and evaluate DCF-PCA on various problem setting
FOCUS: Fairness via Agent-Awareness for Federated Learning on Heterogeneous Data
Jul 21, 2022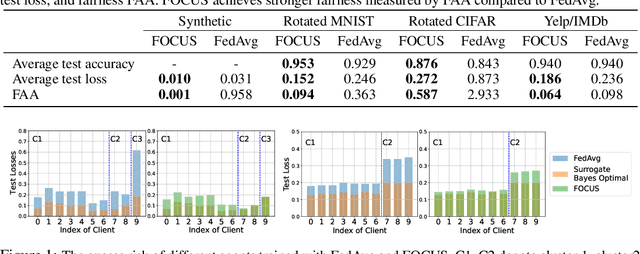

Federated learning (FL) provides an effective paradigm to train machine learning models over distributed data with privacy protection. However, recent studies show that FL is subject to various security, privacy, and fairness threats due to the potentially malicious and heterogeneous local agents. For instance, it is vulnerable to local adversarial agents who only contribute low-quality data, with the goal of harming the performance of those with high-quality data. This kind of attack hence breaks existing definitions of fairness in FL that mainly focus on a certain notion of performance parity. In this work, we aim to address this limitation and propose a formal definition of fairness via agent-awareness for FL (FAA), which takes the heterogeneous data contributions of local agents into account. In addition, we propose a fair FL training algorithm based on agent clustering (FOCUS) to achieve FAA. Theoretically, we prove the convergence and optimality of FOCUS under mild conditions for linear models and general convex loss functions with bounded smoothness. We also prove that FOCUS always achieves higher fairness measured by FAA compared with standard FedAvg protocol under both linear models and general convex loss functions. Empirically, we evaluate FOCUS on four datasets, including synthetic data, images, and texts under different settings, and we show that FOCUS achieves significantly higher fairness based on FAA while maintaining similar or even higher prediction accuracy compared with FedAvg.