 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJobBench: Aligning Agent Work With Human Will
May 25, 2026Current benchmarks for occupational AI agents are scoped primarily by economic values, telling a replacement story. We introduce JobBench, which evaluates AI agents on the workflows that experts identify as high-priority for delegation, empowering humans based on their needs instead of replacing them with GDP value. JobBench covers 130 agentic tasks across 35 occupations. Each task is packaged as a workspace of heterogeneous reference files, requiring the agent to reason through the cluttered information streams of real professional work. Outputs are graded by a fact-anchored chain of rubrics, averaging 35.6 binary criteria per task. We evaluate 36 models; the strongest, Claude Opus~4.7 under Claude Code, reaches only 45.9 %. We hope JobBench shifts the community's target labour-market effect from replacement to enhancement: building agents that do what humans actually want delegated, not only what is most economically valuable.
Polyhedral Instability Governs Regret in Online Learning
May 13, 2026Many online decision problems over combinatorial actions are addressed via convex relaxations, leading to online convex optimization with piecewise linear objectives and induced polyhedral structure. We show that regret in such problems is governed by \emph{polyhedral instability}: the number of changes of the active region. Under full information feedback and fixed partition assumptions, if $\mathrm{RS}_T$ denotes the number of region switches and $V_{\max}$ the maximum number of vertices per region, we prove $\Regret_T= Θ(\sqrt{(1+\mathrm{RS}_T)\,T\,\log V_{\max}})$ interpolating between experts-like and dimension-dependent OCO rates. For online submodular--concave games under Lovász convexification, this reduces to the permutation-switch count $\mathrm{SC}_T$, yielding the matching rate $\Regret_T= Θ(\sqrt{(1+\mathrm{SC}_T)\,T\,\log n})$. Experiments on synthetic and real combinatorial problems (shortest path, influence maximization) validate the predicted scaling and indicate that low-instability regimes can arise in practice without explicit enumeration of actions.
GradShield: Alignment Preserving Finetuning
May 13, 2026Large Language Models (LLMs) pose a significant risk of safety misalignment after finetuning, as models can be compromised by both explicitly and implicitly harmful data. Even some seemingly benign data can inadvertently steer a model towards misaligned behaviors. To address this, we introduce GradShield, a principled filtering method that safeguards LLMs during finetuning by identifying and removing harmful data points before they corrupt the model's alignment. It removes potentially harmful data by computing a Finetuning Implicit Harmfulness Score (FIHS) for each data point and employs an adaptive thresholding algorithm. We apply GradShield to multiple utility fine-tuning tasks across varying levels of harmful data and evaluate the safety and utility performance of the resulting LLMs using various metrics. The results show that GradShield outperforms all baseline methods, consistently maintaining an Attack Success Rate (ASR) below $6\%$ while preserving utility performance.
The WidthWall: A Strict Expressivity Hierarchy for Hypergraph Neural Networks
May 13, 2026Hypergraphs provide a natural framework to model higher-order interactions in scientific, social, and biological systems. Hypergraph neural networks (HGNNs) aim to learn from such data, yet it remains unclear which higher-order structures these models can represent. We show that hypergraph expressivity is governed by which small patterns an architecture can detect and count. We formalize this via homomorphism densities, which measure how often a structural motif appears in a hypergraph. Combining classical homomorphism-count completeness with invariant approximation, we show that homomorphism densities generate all continuous hypergraph invariants and organize them into a strict hierarchy indexed by hypertree width. This yields a Width Wall: a fundamental architectural limit beyond which no hidden dimension, training procedure or fixed-depth HGNN can represent invariants requiring wider patterns. Our framework provides a unified characterization of 15 HGNN architectures, precisely identifies information lost by clique expansion, and motivates density-aware models that extend expressivity beyond bounded-width message passing. We experimentally validate this finding on an APPLICATION NODE CLASSIFICATION SUITE of real-world hypergraphs, where the Width Wall predicts when graph-reduction baselines fail and when density features help.
Visual Aesthetic Benchmark: Can Frontier Models Judge Beauty?
May 12, 2026Multimodal large language models (MLLMs) are now routinely deployed for visual understanding, generation, and curation. A substantial fraction of these applications require an explicit aesthetic judgment. Most existing solutions reduce this judgment to predicting a scalar score for a single image. We first ask whether such scores faithfully capture comparative preference: in a controlled study with eight expert annotators, score-derived rankings align poorly with the same annotators' direct comparisons, while direct ranking yields substantially higher inter-annotator agreement on best- and worst-image labels. Motivated by this finding, we introduce the Visual Aesthetic Benchmark (VAB), which casts aesthetic evaluation as comparative selection over candidate sets with matched subject matter. VAB contains 400 tasks and 1,195 images across fine art, photography, and illustration, with labels derived from the consensus of 10 independent expert judges per task. Evaluating 20 frontier MLLMs and six dedicated visual-quality reward models, we find that the strongest system identifies both the best and the worst image correctly across three random permutations of the candidate order in only 26.5% of tasks, far below the 68.9% achieved by human experts. Fine-tuning a 35B-parameter model on 2,000 expert examples brings its accuracy close to that of a 397B-parameter open-weight model, suggesting that the comparative signal in VAB is transferable. Together, these results expose a clear and measurable gap between current multimodal models and expert aesthetic judgment, and VAB provides the first set-based, expert-grounded testbed on which that gap can be tracked and closed.
SeedAIchemy: LLM-Driven Seed Corpus Generation for Fuzzing
Nov 16, 2025



We introduce SeedAIchemy, an automated LLM-driven corpus generation tool that makes it easier for developers to implement fuzzing effectively. SeedAIchemy consists of five modules which implement different approaches at collecting publicly available files from the internet. Four of the five modules use large language model (LLM) workflows to construct search terms designed to maximize corpus quality. Corpora generated by SeedAIchemy perform significantly better than a naive corpus and similarly to a manually-curated corpus on a diverse range of target programs and libraries.
Can LLMs Design Good Questions Based on Context?
Jan 07, 2025This paper evaluates questions generated by LLMs from context, comparing them to human-generated questions across six dimensions. We introduce an automated LLM-based evaluation method, focusing on aspects like question length, type, context coverage, and answerability. Our findings highlight unique characteristics of LLM-generated questions, contributing insights that can support further research in question quality and downstream applications.
Vulnerability Detection with Code Language Models: How Far Are We?
Mar 27, 2024

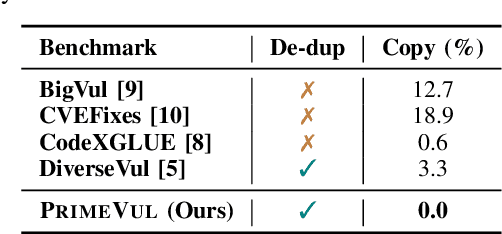
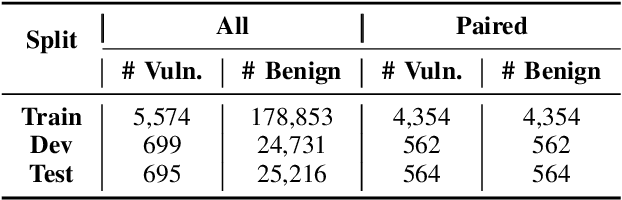
In the context of the rising interest in code language models (code LMs) and vulnerability detection, we study the effectiveness of code LMs for detecting vulnerabilities. Our analysis reveals significant shortcomings in existing vulnerability datasets, including poor data quality, low label accuracy, and high duplication rates, leading to unreliable model performance in realistic vulnerability detection scenarios. Additionally, the evaluation methods used with these datasets are not representative of real-world vulnerability detection. To address these challenges, we introduce PrimeVul, a new dataset for training and evaluating code LMs for vulnerability detection. PrimeVul incorporates a novel set of data labeling techniques that achieve comparable label accuracy to human-verified benchmarks while significantly expanding the dataset. It also implements a rigorous data de-duplication and chronological data splitting strategy to mitigate data leakage issues, alongside introducing more realistic evaluation metrics and settings. This comprehensive approach aims to provide a more accurate assessment of code LMs' performance in real-world conditions. Evaluating code LMs on PrimeVul reveals that existing benchmarks significantly overestimate the performance of these models. For instance, a state-of-the-art 7B model scored 68.26% F1 on BigVul but only 3.09% F1 on PrimeVul. Attempts to improve performance through advanced training techniques and larger models like GPT-3.5 and GPT-4 were unsuccessful, with results akin to random guessing in the most stringent settings. These findings underscore the considerable gap between current capabilities and the practical requirements for deploying code LMs in security roles, highlighting the need for more innovative research in this domain.
Jatmo: Prompt Injection Defense by Task-Specific Finetuning
Jan 08, 2024


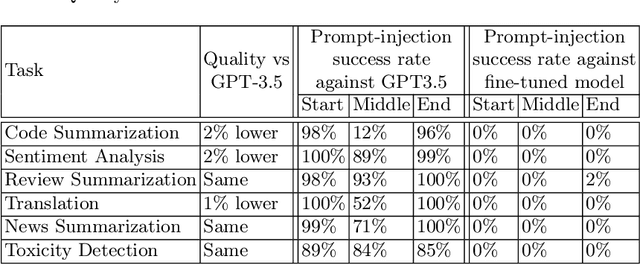
Large Language Models (LLMs) are attracting significant research attention due to their instruction-following abilities, allowing users and developers to leverage LLMs for a variety of tasks. However, LLMs are vulnerable to prompt-injection attacks: a class of attacks that hijack the model's instruction-following abilities, changing responses to prompts to undesired, possibly malicious ones. In this work, we introduce Jatmo, a method for generating task-specific models resilient to prompt-injection attacks. Jatmo leverages the fact that LLMs can only follow instructions once they have undergone instruction tuning. It harnesses a teacher instruction-tuned model to generate a task-specific dataset, which is then used to fine-tune a base model (i.e., a non-instruction-tuned model). Jatmo only needs a task prompt and a dataset of inputs for the task: it uses the teacher model to generate outputs. For situations with no pre-existing datasets, Jatmo can use a single example, or in some cases none at all, to produce a fully synthetic dataset. Our experiments on seven tasks show that Jatmo models provide similar quality of outputs on their specific task as standard LLMs, while being resilient to prompt injections. The best attacks succeeded in less than 0.5% of cases against our models, versus 87% success rate against GPT-3.5-Turbo. We release Jatmo at https://github.com/wagner-group/prompt-injection-defense.