 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Knowledge Distillation of LLMs With Counterfactual Explanations
Oct 24, 2025Knowledge distillation is a promising approach to transfer capabilities from complex teacher models to smaller, resource-efficient student models that can be deployed easily, particularly in task-aware scenarios. However, existing methods of task-aware distillation typically require substantial quantities of data which may be unavailable or expensive to obtain in many practical scenarios. In this paper, we address this challenge by introducing a novel strategy called Counterfactual-explanation-infused Distillation CoD for few-shot task-aware knowledge distillation by systematically infusing counterfactual explanations. Counterfactual explanations (CFEs) refer to inputs that can flip the output prediction of the teacher model with minimum perturbation. Our strategy CoD leverages these CFEs to precisely map the teacher's decision boundary with significantly fewer samples. We provide theoretical guarantees for motivating the role of CFEs in distillation, from both statistical and geometric perspectives. We mathematically show that CFEs can improve parameter estimation by providing more informative examples near the teacher's decision boundary. We also derive geometric insights on how CFEs effectively act as knowledge probes, helping the students mimic the teacher's decision boundaries more effectively than standard data. We perform experiments across various datasets and LLMs to show that CoD outperforms standard distillation approaches in few-shot regimes (as low as 8-512 samples). Notably, CoD only uses half of the original samples used by the baselines, paired with their corresponding CFEs and still improves performance.
Constrained Decoding for Secure Code Generation
Apr 30, 2024Code Large Language Models (Code LLMs) have been increasingly used by developers to boost productivity, but they often generate vulnerable code. Thus, there is an urgent need to ensure that code generated by Code LLMs is correct and secure. Previous research has primarily focused on generating secure code, overlooking the fact that secure code also needs to be correct. This oversight can lead to a false sense of security. Currently, the community lacks a method to measure actual progress in this area, and we need solutions that address both security and correctness of code generation. This paper introduces a new benchmark, CodeGuard+, along with two new metrics, secure-pass@k and secure@$k_{\text{pass}}$, to measure Code LLMs' ability to generate both secure and correct code. Using our new evaluation methods, we show that the state-of-the-art defense technique, prefix tuning, may not be as strong as previously believed, since it generates secure code but sacrifices functional correctness. We also demonstrate that different decoding methods significantly affect the security of Code LLMs. Furthermore, we explore a new defense direction: constrained decoding for secure code generation. We propose new constrained decoding techniques to generate code that satisfies security and correctness constraints simultaneously. Our results reveal that constrained decoding is more effective than prefix tuning to improve the security of Code LLMs, without requiring a specialized training dataset. Moreover, constrained decoding can be used together with prefix tuning to further improve the security of Code LLMs.
Vulnerability Detection with Code Language Models: How Far Are We?
Mar 27, 2024

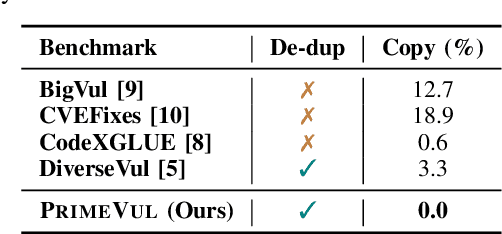
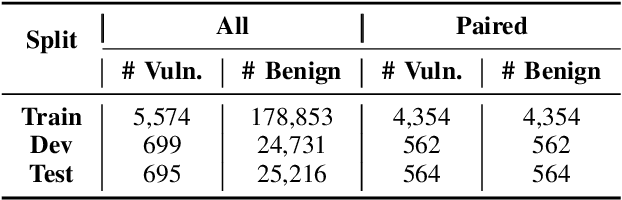
In the context of the rising interest in code language models (code LMs) and vulnerability detection, we study the effectiveness of code LMs for detecting vulnerabilities. Our analysis reveals significant shortcomings in existing vulnerability datasets, including poor data quality, low label accuracy, and high duplication rates, leading to unreliable model performance in realistic vulnerability detection scenarios. Additionally, the evaluation methods used with these datasets are not representative of real-world vulnerability detection. To address these challenges, we introduce PrimeVul, a new dataset for training and evaluating code LMs for vulnerability detection. PrimeVul incorporates a novel set of data labeling techniques that achieve comparable label accuracy to human-verified benchmarks while significantly expanding the dataset. It also implements a rigorous data de-duplication and chronological data splitting strategy to mitigate data leakage issues, alongside introducing more realistic evaluation metrics and settings. This comprehensive approach aims to provide a more accurate assessment of code LMs' performance in real-world conditions. Evaluating code LMs on PrimeVul reveals that existing benchmarks significantly overestimate the performance of these models. For instance, a state-of-the-art 7B model scored 68.26% F1 on BigVul but only 3.09% F1 on PrimeVul. Attempts to improve performance through advanced training techniques and larger models like GPT-3.5 and GPT-4 were unsuccessful, with results akin to random guessing in the most stringent settings. These findings underscore the considerable gap between current capabilities and the practical requirements for deploying code LMs in security roles, highlighting the need for more innovative research in this domain.
RGB-D Individual Segmentation
Nov 11, 2019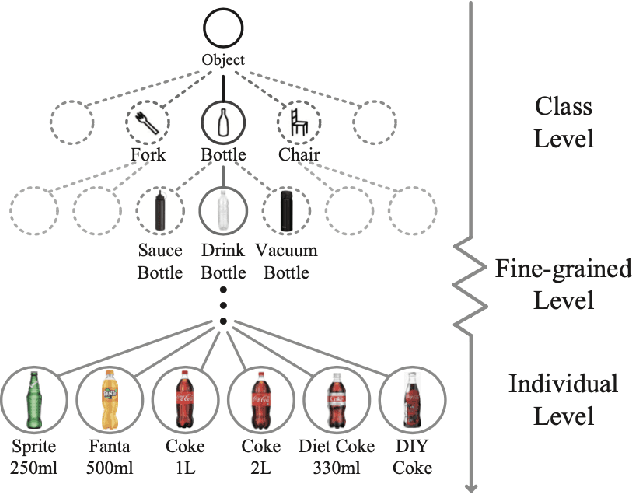
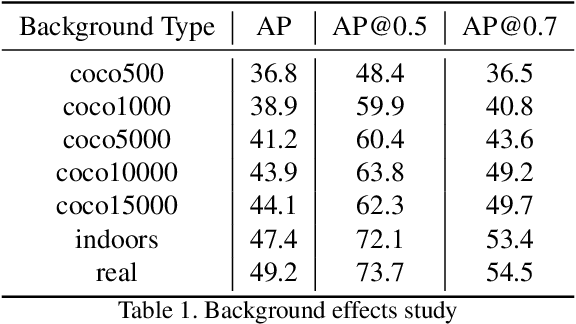
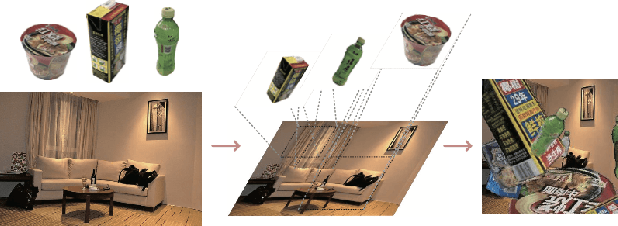
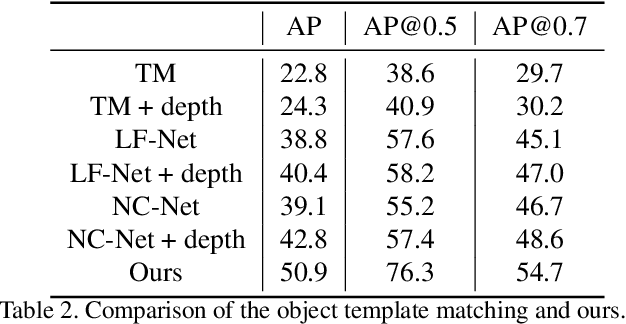
Fine-grained recognition task deals with sub-category classification problem, which is important for real-world applications. In this work, we are particularly interested in the segmentation task on the \emph{finest-grained} level, which is specifically named "individual segmentation". In other words, the individual-level category has no sub-category under it. Segmentation problem in the individual level reveals some new properties, limited training data for single individual object, unknown background, and difficulty for the use of depth. To address these new problems, we propose a "Context Less-Aware" (CoLA) pipeline, which produces RGB-D object-predominated images that have less background context, and enables a scale-aware training and testing with 3D information. Extensive experiments show that the proposed CoLA strategy largely outperforms baseline methods on YCB-Video dataset and our proposed Supermarket-10K dataset. Code, trained model and new dataset will be published with this paper.