 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVA-MILP: Towards Standardized Evaluation of MILP Instance Generation
May 30, 2025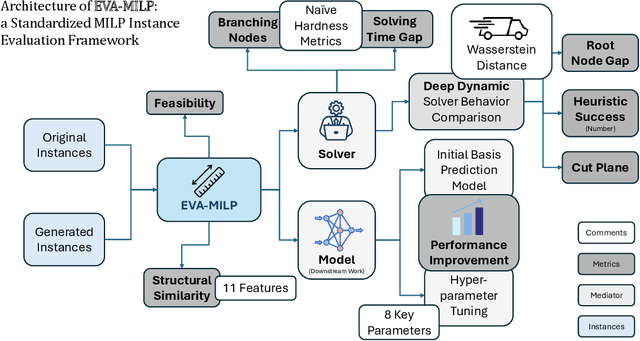
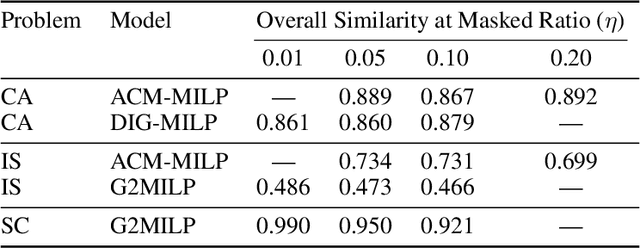
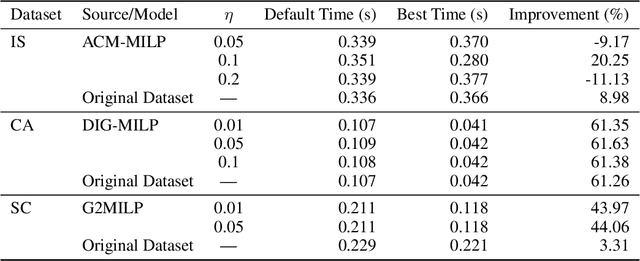
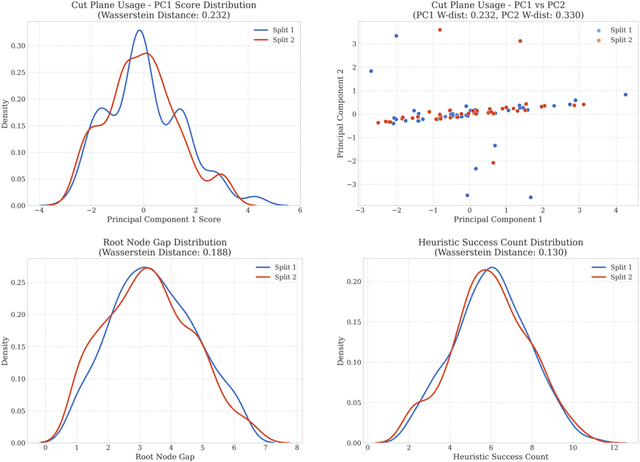
Mixed-Integer Linear Programming (MILP) is fundamental to solving complex decision-making problems. The proliferation of MILP instance generation methods, driven by machine learning's demand for diverse optimization datasets and the limitations of static benchmarks, has significantly outpaced standardized evaluation techniques. Consequently, assessing the fidelity and utility of synthetic MILP instances remains a critical, multifaceted challenge. This paper introduces a comprehensive benchmark framework designed for the systematic and objective evaluation of MILP instance generation methods. Our framework provides a unified and extensible methodology, assessing instance quality across crucial dimensions: mathematical validity, structural similarity, computational hardness, and utility in downstream machine learning tasks. A key innovation is its in-depth analysis of solver-internal features -- particularly by comparing distributions of key solver outputs including root node gap, heuristic success rates, and cut plane usage -- leveraging the solver's dynamic solution behavior as an `expert assessment' to reveal nuanced computational resemblances. By offering a structured approach with clearly defined solver-independent and solver-dependent metrics, our benchmark aims to facilitate robust comparisons among diverse generation techniques, spur the development of higher-quality instance generators, and ultimately enhance the reliability of research reliant on synthetic MILP data. The framework's effectiveness in systematically comparing the fidelity of instance sets is demonstrated using contemporary generative models.
Rethinking the Unsolvable: When In-Context Search Meets Test-Time Scaling
May 28, 2025Recent research has highlighted that Large Language Models (LLMs), even when trained to generate extended long reasoning steps, still face significant challenges on hard reasoning problems. However, much of the existing literature relies on direct prompting with simple in-context learning examples for evaluation, which largely overlooks advanced techniques to elicit LLMs' deliberate reasoning before drawing conclusions that LLMs hit a performance ceiling. In this paper, we systematically explore the combined potential of in-context search and test-time scaling on super hard reasoning tasks. We find that by employing advanced in-context search prompting to LLMs augmented with internal scaling, one can achieve transformative performance breakthroughs on tasks previously deemed "unsolvable" (e.g., reported success rates below 5%). We provide both empirical results and theoretical analysis of how this combination can unleash LLM reasoning capabilities: i) Empirically, on controlled NP-hard tasks and complex real-world planning benchmarks, our approach achieves up to a 30x improvement in success rates compared to previously reported results without any external mechanisms; ii) Theoretically, we show that in-context search prompting, when combined with internal scaling, significantly extends the complexity class of solvable reasoning problems. These findings challenge prevailing assumptions about the limitations of LLMs on complex tasks, indicating that current evaluation paradigms systematically underestimate their true potential. Our work calls for a critical reassessment of how LLM reasoning is benchmarked and a more robust evaluation strategy that fully captures the true capabilities of contemporary LLMs, which can lead to a better understanding of their operational reasoning boundaries in real-world deployments.
Beyond Numeric Awards: In-Context Dueling Bandits with LLM Agents
Jul 02, 2024In-context decision-making is an important capability of artificial general intelligence, which Large Language Models (LLMs) have effectively demonstrated in various scenarios. However, LLMs often face challenges when dealing with numerical contexts, and limited attention has been paid to evaluating their performance through preference feedback generated by the environment. This paper investigates the performance of LLMs as decision-makers in the context of Dueling Bandits (DB). We first evaluate the performance of LLMs by comparing GPT-3.5-Turbo, GPT-4, and GPT-4-Turbo against established DB algorithms. Our results reveal that LLMs, particularly GPT-4 Turbo, quickly identify the Condorcet winner, thus outperforming existing state-of-the-art algorithms in terms of weak regret. Nevertheless, LLMs struggle to converge even when explicitly prompted to do so, and are sensitive to prompt variations. To overcome these issues, we introduce an LLM-augmented algorithm, IF-Enhanced LLM, which takes advantage of both in-context decision-making capabilities of LLMs and theoretical guarantees inherited from classic DB algorithms. The design of such an algorithm sheds light on how to enhance trustworthiness for LLMs used in decision-making tasks where performance robustness matters. We show that IF-Enhanced LLM has theoretical guarantees on both weak and strong regret. Our experimental results validate that IF-Enhanced LLM is robust even with noisy and adversarial prompts.